
SPSS ile, veri setinizle Ki Kare Bağımsızlık Testi (Chi-Square Test of Independence) yaptınız ve p değerine bakarak istatistiksel olarak anlamlı bir sonuç buldunuz. Hangi değişkenlerinin hangi seviyeleri arasında anlamlı bir ilişki olduğunu merak ediyorsanız, Post Hoc testi yapmanız gerekecek. Bu sayfada, SPSS ile ki kare testi sonrası post hoc testlerinin nasıl yapılacağını anlatıyorum.
Bu sayfadaki post hoc testi yaparken kullandığım örnek veri, bu linke tıklarsanız gideceğiniz başlıktaki 3 x 3 ki kare bağımsızlık testi örneğiyle aynı veri. Eğer o sayfadan bu sayfaya geçtiyseniz kolayca takip edebilirsiniz. Ki kare bağımsızlık testinin post hoc aşamasına gelmeden önceki adımlarını görmek istiyorsanız da bu sayfadan o sayfaya geçebilirsiniz.
SPSS ile Ki Kare Bağımsızlık Testi için Post Hoc Testi Nasıl Yapılır?
Bu aşamaya gelmeden önce Ki Kare Bağımsızlık Testi analizimize başladık, p değeri anlamlılık seviyesini 0.05’in altında bulduk. Şimdi, sıra ki kare testi için post hoc analizi yapıp hangi değerler arasında anlamlı bir ilişki olup hangileri arasında olmadığını bulmakta.
Önce, Analyze -> Descriptive Statistics -> Crosstabs tuşlarına basarak Crosstabs penceresini açıyoruz.
“Cells” butonuna basıyoruz.
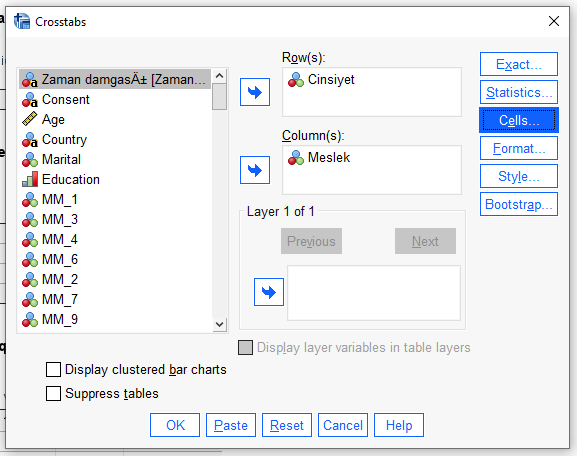
Açılan pencerede, “Residuals” bölümündeki “Adjusted standardized” seçeneğini işaretliyoruz.
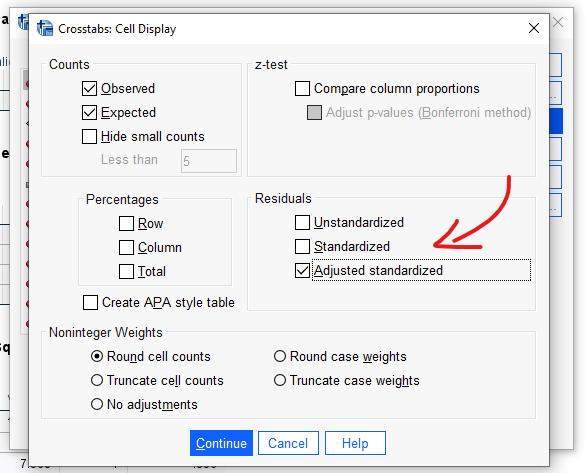
“Continue” ve “OK” butonlarına basıyoruz.
SPSS bize tablolar verecek.
Bu tablolardan “Crosstabulation” tablosuna bakmalıyız. Buradan sonra 2 yöntem kullanabiliriz:
- Birinci yöntem, hücrelerin z skorlarını bulmak ve p < 0.05 anlamlılık seviyesine göre z skorlarının anlamlı olup olmadığını bulmak. (Bu yöntem kısa fakat Tip I hataya daha açık)
- İkinci yöntem, hücrelerin z skorlarının adjustment’ını yapmak (hata oranını ayarlamak) ve yeni bir p değeri anlamlılık seviyesi hesaplayarak o değerle karşılaştırarak anlamlı olup olmadığını bulmak. (Bu yöntem uzun fakat istatistiksel olarak daha güvenilir sonuçlar veriyor)

1) Kısa Yol: Z Skoruna Bakarak Ki Kare Post Hoc Yorumlama
“Crosstabulation” tablosunda, her hücre için “Adjusted Residual” değerine bakmamız gerekiyor. Bu Adjusted Residual değerleri, aynı zamanda Z skorlarıdır. İstatistikçilere göre, -1.96 değerinden küçük veya 1.96 değerinden büyük Z skorları, 0.05 anlamlılık seviyesi eşik değerine göre, istatistiksel olarak anlamlı kabul edilmektedir.
Yani, Crosstabulation tablosundaki Adjusted Residual değeri -1.96’dan küçük veya 1.96’dan büyük değerlere sahip hücrelerde, değişkenler arasında anlamlı bir ilişki vardır.
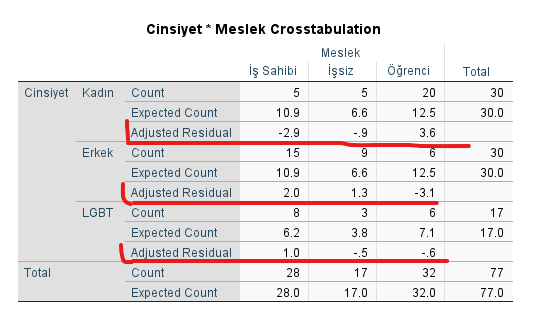
Bu örnekte, işsiz erkek ve iş sahibi LGBT dışında bütün cinsiyet-meslek çiftleri arasında anlamlı bir ilişki vardır. Gerçek değerin ortalamadan (ya da beklenen değerden) daha yüksek ya da daha düşük olduğuna Count ve Expected Count satırlarındaki değerleri karşılaştırarak bakabiliriz. Yani, tabloyu bu şekilde yorumlarsak, örneğin:
- “İş sahibi erkekler, ortalamadan fazla yoğunluğa sahiptir.”
- “İstatistiksel olarak anlamlı olacak biçimde az orandaki kadın iş sahibidir.”
- “Kadınların istatistiksel olarak anlamlı olacak biçimde çoğu, öğrencidir.”
formatında cümleler kurabiliriz.
Bu yöntemde Tip I hata yapma ihtimali yüksek demiştik. Yani yanlış pozitif (gerçekte var olmayan ilişkileri varmış gibi bulmak) sonuçlar alma ihtimali yüksektir. 9 hücrenin 7’sinde anlamlı bir sonuç bulduk. Şimdi, bu yöntemden daha uzun olan diğer yöntemi uygulayarak o yöntemle kaç hücrede anlamlı sonuç bulacağımızı görelim.
2) Uzun Yol: Bonferroni Düzeltmesi Yaparak Ki Kare Post Hoc Yorumlama
Biz deminki metotta 9 kere p değerine baktık ve 0.05’ten küçük olup olmadığına baktık. Bu yöntemde Tip I hata yapma ihtimali yüksektir. Tip I hata oranını düşürmek için, p değerlerine Bonferroni düzeltmesi yapmamız gerekiyor. Eğer bunu yaparsak, bulacağımız istatistiksel anlamlılık değerleri, gerçeği deminki metotta bulduğumuza göre gerçeği daha çok yansıtıyor olacaktır.
- Önce Adjusted Residual değerleri üzerinden Z skorunun karesini alıp yeni bir değişken oluşturacağız.
- Sonra o değişkenin Bonferroni düzeltmesi yapılmış p değerini bulacağız.
- Sonra 0.05 anlamlılık değerini hücre sayısına bölüp yeni bir p değeri anlamlılık eşik değeri bulacağız.
- Sonra her değişkenimizin Bonferroni düzeltmesi yapılmış p değeri ile eşik değerini karşılaştırıp, her değişkenin istatistiksel olarak anlamlı olup olmadığını bulacağız.
Şimdi başlayalım!
Adım 1: Adjusted Residual Z Skorunun Karesini Alma
Yine demin yukarıda gösterdiğim SPSS analizi adımlarını izleyip aşağıdaki “Crosstabulation” tablosuna ulaşıyoruz. Buradan sonra, yorumlama şeklimiz değişecek ve ekstra işlemler yapmamız gerekecek.
Bu şekilde bulduğumuz Adjusted Residual değerleri (yani Z skoru değerleri), Tip I hataya açık demiştik. Hata oranlarını düzeltmek ve daha güvenilir post hoc sonuçlarına ulaşmak için, bazı düzeltmeler yapmamız gerekiyor.
Bu Adjusted Residual (Z skoru) değerleri, -1.96’dan küçükse ya da 1.96’dan büyükse, bu, Z skorunun p değerinin 0.05’ten küçük olduğunu gösteriyor. Ama bu tabloya bakarak, p değerinin tam olarak kaç olduğunu göremiyoruz. Bu, ki kare analizini raporlarken ideal bir durum değil. Aşağıda yapacağımız işlemler sonucunda, üstteki birinci yönteme göre istatistiksel açıdan daha güvenilir sonuçlar bulmakla kalmayacak, aynı zamanda her hücrenin düzeltilmiş p değerini bulup ki kare analizi raporlama aşamasında da daha net sonuçlar elde edeceğiz.
Önce SPSS output dosyamızı bi kenara koyup, veri dosyamızı açıyoruz ve Data View kısmına gidiyoruz. Ki kare analizi sonucu bulduğumuz “Crosstabulation” tablosunda gördüğümüz Adjusted Residual değerlerini, SPSS veri dosyamızda yeni bir sütun açarak o sütuna alt alta yazıyoruz.
Örnekte, yukarıdaki “Crosstabulation” tablosundaki Adjusted Residual değerlerini yeni bir sütuna yazdığımı görebilirsiniz. Bu örnek 3 x 3 olduğu için toplam 9 değer var. Adjusted Residual dediğimiz şeyin Adjusted Z Score ile aynı şey olduğunu tekrar hatırlatalım.

Transform -> Compute Variable butonlarına basıyoruz.

Açılan Compute Variable penceresi bu şekilde görünecek.

“Target Variable” kısmına, yeni oluşturacağımız değişkenin adını yazıyoruz. Ad olarak ne yazdığımız fark etmez. Sonra, soldaki kutudan, demin oluşturduğumuz Adjusted Z Score değişkenini 1 kere alıp sağdaki Numeric Expression kutusuna atıyoruz. Sonra * işaretine basıyoruz. Sonra, soldan Adjusted Z Score’u alıp tekrar sağa atıyoruz. Ekran aşağıdaki gibi görünmeli.
Sonra OK butonuna basıyoruz.

SPSS veri setimizin Variable View bölümüne gelirsek, verinin en sağ sütununda yeni bir değişken oluştuğunu göreceğiz.

Adım 2: Bonferroni Düzeltmesi Yapılmış p Değeri Bulma
Yine Analyze -> Compute Variable butonlarına basarak Compute Variable penceresini açıyoruz.
Kutulardakileri siliyoruz. Elinizle ya da “Reset” butonuna basarak silebilirsiniz.

“Target Variable” bölümüne yeni bir değişken oluşturuyoruz. Sağdaki “Function group” menüsünden, “Significance”ı seçiyoruz. Altındaki “Functions and Special Variables” menüsünden, “Sig.Chisq” seçeneğini seçiyoruz ve yukarıdaki “Numeric Expression” bölümüne taşıyoruz.
Bunları yaptığınızda ekran aşağıdaki gibi görünmeli.

Sonra, demin oluşturduğumuz en yeni değişkeni soldaki kutudan alıp, sağdaki kutunun “?” ile dolu olan yerine taşıyoruz.

Taşıdıktan sonra, elimizle yanına ” , 1 ” yazıyoruz. Ekranın son hali aşağıdaki gibi görünmeli.
Sonra “OK” butonuna basıyoruz.

SPSS Variable View penceremizin en sağ sütununda, en yeni oluşturduğumuz p değeri görünmekte.

Bu p değerlerini daha iyi görebilmek için, Data View kısmına gidip, “Decimals” sütununda değişkeni 7 decimal yani virgülden sonraki rakam olarak ayarlıyoruz.

Ayarladıktan sonra Variable View bölümüne geri gidersek, p değerlerinin artık daha detaylı göründüğünü görebiliriz.

Adım 3: Bonferroni Düzeltmesi Yapılmış p Anlamlılık Eşik Değeri Bulma
Biz bu analizde ilk başta standart olarak 0.05 p değeri eşik seviyesini kullanmıştık.
Bu eşik seviyesi 1 tek analiz için Tip I hata oranlarını kontrol altında tutar. Analiz sayısı arttıkça, Tip I hata yapma oranımız artar. Tip I hata yapma oranını kontrol altına almak için, Bonferroni düzeltmesi yapmamız gerekiyor.
Bizim bu analizimiz 3 x 3 olduğu için ki kare analizindeki 9 hücremiz için arka arkaya 9 adet p değeri hesaplaması yapmamız gerekti. Bunu p = 0.05 eşik değeri üzerinden yapınca Tip I hata oranı riski artmış oldu. Bu hata oranını sınırlamak için aşağıdaki formül ile yeni bir Bonferroni düzeltmesi yapılmış p eşik değeri bulacağız.
Yeni p değeri = 0.05 / Ki kare analizindeki hücre sayısı
Yani bizim bu örneğimizde değerleri formülde yerlerine koyarsak:
Yeni p değeri = 0.05 / 9
Yeni p değeri = 0.0055555
Demin 2. Adım’da bulduğumuz düzeltilmiş p değerlerinin istatistiksel olarak anlamlı olup olmadığını, bu yeni bulduğumuz Bonferroni düzeltmesi yapılmış p değeri ile karşılaştırarak göreceğiz.

Adım 4: Yeni p Değerleriyle Eşik Değerini Karşılaştırma
Son adım bu.
9 hücrenin de demin oluşturduğumuz “p_value” değeri ile hesap makinesinde yeni hesapladığımız p eşik değerini karşılaştıracağız. Eğer p_value değeri eşik değerinden küçük ise, istatistiksel anlamlılık vardır demek olacak.

Bu örnekte, satır 1, 3, 6, 7, 8, ve 9’daki p değerleri istatistiksel olarak anlamlı çıkmış. Bunların karşılık geldiği Adjusted Residual (Adjusted Z Score) değerlerine bakarsak, -2.9, 3.6, -3.1, 6.2, 3.8, ve 7.1 değerlerini görebiliriz.
Demin SPSS’in bize verdiği “Crosstabs” tablosuna bakıp bu Adjusted Residual değerlerinin hangi değişken çiftlerine ait olduğunu hatırlarsak:
Tabloyu bu şekilde inceleyince, iş sahibi kadın, öğrenci kadın, öğrenci erkek, işsiz LGBT, iş sahibi LGBT, öğrenci LGBT sayısı, ki kare testi ile, eğer gruplar arasında hiç fark olmasaydı beklenen değerden istatistiksel anlamda farklı çıkmış şeklinde bir sonuca varabiliriz.
Gerçek değerin ortalamadan (ya da beklenen değerden) daha yüksek ya da daha düşük olduğuna Count ve Expected Count satırlarındaki değerleri karşılaştırarak bakabiliyoruz.
Yani, sonuç olarak şu değerlendirmeleri yapabiliriz:
- İş sahibi kadın sayısı beklenenden az çıktı.
- Öğrenci kadın sayısı beklenenden çok çıktı.
- Öğrenci erkek sayısı beklenenden az çıktı.
- LGBT iş sahibi sayısı beklenenden çok çıktı.
- LGBT işsiz sayısı beklenenden az çıktı.
- LGBT öğrenci sayısı sayısı beklenenden az çıktı.
Bu değerlendirme cümlelerinin hepsi, istatistiksel olarak anlamlıdır.
2 Metot Karşılaştırması
Tip I hata oranı düşük olan Metot 2’de toplam 6 tane p değeri anlamlı çıkmış.
Tip I hata oranı daha yüksek olan Metot 1’de kaç tane p değerinin istatistiksel anlamlı çıktığına bakarsak, 7 adet p değerinin anlamlı çıktığını görebiliriz. Yani, Metot 1’deki yöntemle anlamlı çıkan 1 adet daha fazla p değeri var. Anlamlı çıkan 1 adet ekstra değer, muhtemelen yanlış pozitif bir değerdi.
Metot 2’de bulduğumuz 6 adet anlamlı p değeri, bu yüzden Metot 1’de bulunan 7 adet anlamlı p değerinden daha güvenilirdir.
Kaynakça
SPSS ile ki kare post hoc analizi kısa ve uzun yoldan yapma adımları bu kadardı, buraya kadar takip ettiyseniz SPSS ile uğraşan çoğu kişinin bilmediği bir yöntemi öğrenmiş oldunuz, tebrikler.
Bu yönteme inanmayan olursa aşağıdaki 2 bilimsel dergi makalesini referans olarak verebilirsiniz:
Beasley, T. M., & Schumacker, R. E. (1995). Multiple regression approach to analyzing contingency tables: Post hoc and planned comparison procedures. The Journal of Experimental Education, 64(1), 79–93. https://doi.org/10.1080/00220973.1995.9943797
Bir yanıt bırakın