
İçindekiler
SPSS’te Çoklu Doğrusal Regresyon Analizi yapmanın birden fazla yöntemi bulunmaktadır. “Forced-Entry” yöntemi, çoklu regresyon analizi yaparken analiz modeline bağımsız değişkenlerin hepsinin aynı anda dahil edildiği yönteme denmektedir. Bu yazıda, çoklu doğrusal regresyon analizi yaparken tercih edilen en popüler yöntem olan “Forced-Entry” yönteminin ne olduğuna, SPSS ile nasıl yapılacağına ve sonuç tablolarının nasıl yorumlanması gerektiğine değineceğiz.
Çoklu Regresyon “Forced-Entry” Metodu Nedir?
Çoklu doğrusal regresyon analizinde amaç, birden fazla bağımsız değişkenin bir adet bağımlı değişken üzerindeki etkisini incelemektir. Forced-Entry metodu, çoklu regresyon modeline tüm bağımsız değişkenlerin aynı anda sokulduğu (önem sırasına bakılmaksızın) analiz yöntemini ifade eder.
Değişkenlerin belirli kriterlere göre sırayla analize eklendiği veya çıkarıldığı hiyerarşik ve stepwise çoklu regresyon yöntemlerinin aksine, Forced-Entry yönteminde, analizde bağımlı değişken üzerindeki etkisi incelenmek istenen tüm bağımsız değişkenler aynı anda regresyon analizine sokulur.
En temel ve en popüler çoklu doğrusal regresyon analizi yapma yöntemi budur.
Basit doğrusal regresyon analizinde 1 adet bağımlı değişken üzerinde yalnızca 1 adet bağımsız değişkenin etkisi inceleniyordu. Çoklu doğrusal regresyon analizinde ise 1 adet bağımlı değişken üzerinde 1’den fazla sayıda bağımsız değişkenin etkisi birlikte incelenebilmektedir.

Forced-Entry Çoklu Regresyon Varsayımları
Linke tıklayarak çoklu doğrusal regresyon varsayımlarını test etme konusunda yazdığım diğer yazıyı okuyabilir ve çoklu regresyon analizinin bütün varsayımlarının SPSS’te nasıl test edileceğini öğrenebilirsiniz.
SPSS’te yapacağımız forced-entry çoklu regresyon analizinde bulduğumuz sonuçlara güvenebilmemiz için, verimizin regresyon analizi öncesinde bazı varsayımları sağlıyor olması gerekir. Önce regresyon analizi varsayımlarının sağlandığından emin olup, regresyon analizini ondan sonra yapmak gerekir. Bu varsayımlar şunlardır:
- Bütün bağımsız ve bağımlı değişkenlerin devamlı sayısal veri tipinde olması gerekir.
- Veride çok değişkenli (multivariate) uç değer olmaması önerilir.
- Gözlenen ile beklenen değerlerin farkının yani “artık değerlerin” (Residual’ların) normal dağılım göstermesi gerekir.
- Bağımsız değişkenlerin hiçbiri, bağımlı değişken ile lineer olmayan bir ilişki göstermemelidir. Yani eğrisel ilişki olmamalıdır. (Doğrusal İlişki Varsayımı)
- Bağımsız değişkenlerin herhangi ikisini ele aldığımızda, bu iki değişkenin birbiriyle 0.70’ten fazla korelasyon göstermemesi gerekir. (Çoklu Bağlantısızlık Varsayımı)
- Hata varyansları bağımsız değişkenlerin büyüklüğüne göre değişkenlik göstermemelidir. (Homoskedastisite)
- Otokorelasyon olmamalıdır. (Durbin-Watson testi)
Çoklu doğrusal regresyon analizinin varsayımlarını test etme işi epey uzundur ve analizin kendisinden daha kafa karıştırıcı olabilmektedir. Bu sayfada hem çoklu doğrusal regresyon analizi yapmayı hem de varsayımları test etmeyi anlatırsam çok kafa karıştırıcı olabilir. Bu sebeple, bu sayfada varsayımların nasıl test edileceğinden bahsetmeden, yalnızca forced-entry metoduyla çoklu regresyon analizi yapmayı ve sonuçları yorumlamayı göstereceğim.
Linke tıklayarak çoklu doğrusal regresyon varsayımlarını test etme konusunda yazdığım diğer yazıyı okuyabilir ve çoklu regresyon analizinin bütün varsayımlarının SPSS’te nasıl test edileceğini öğrenebilirsiniz.
SPSS ile Forced-Entry Çoklu Regresyon Nasıl Yapılır?
SPSS’te forced-entry yöntemiyle çoklu regresyon analizi yapmak için aşağıdaki adımları takip edebiliriz.
Bu sayfada yapacağımız örnekte, 3 tane bağımsız ve 1 tane bağımlı değişkenimiz var. Depresyon, dayanıklılık ve stres faktörlerinin, yorgunluk seviyesi üzerindeki etkilerine bakacağız.
Analyze -> Regression -> Linear
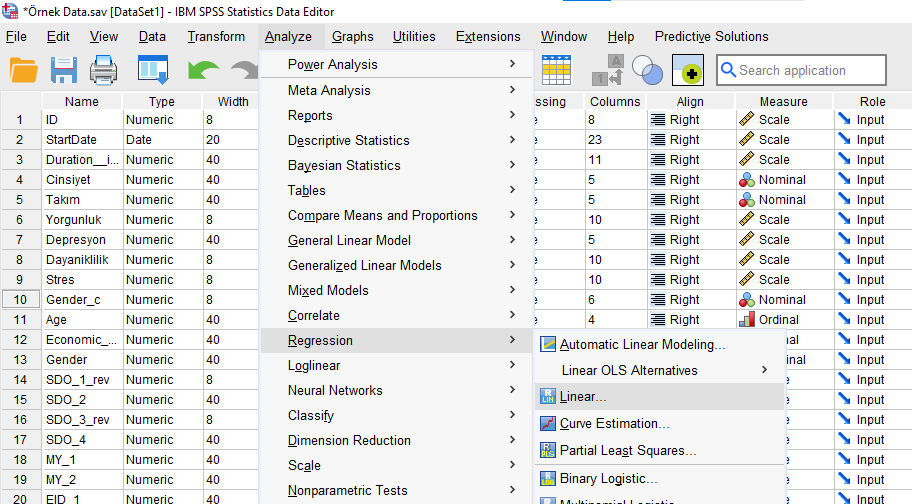
Bağımlı değişkenimizi Dependent kutusuna, bağımsız değişkenlerimizin hepsini tek seferde altındaki Independent(s) kutusuna atıyoruz. Method olarak Enter seçili olmalı.
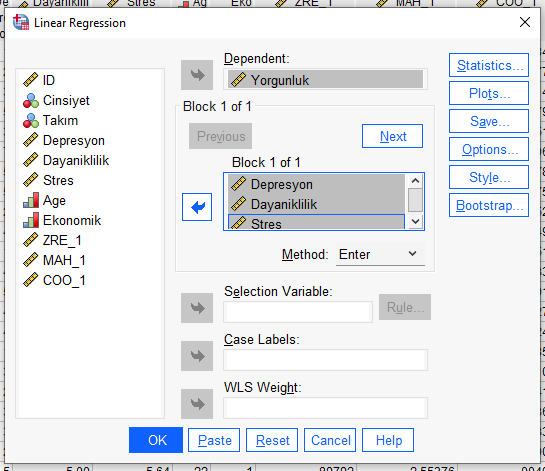
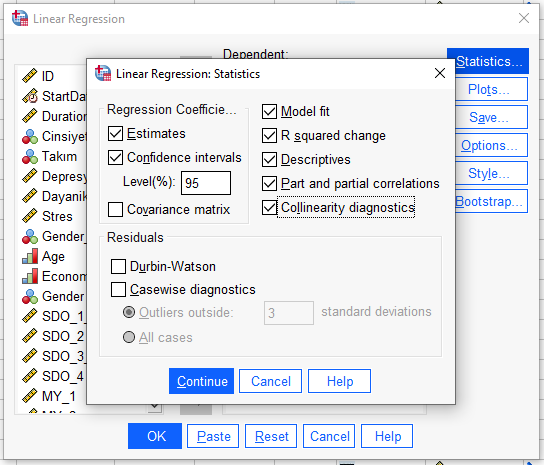
Daha sonra, “Statistics” butonuna basarak, açılan yeni pencerede, aşağıdaki kutucukları işaretliyoruz. Sonra “Continue”ya basıyoruz.
Son olarak, “OK” butonuna basarak SPSS’te forced-entry çoklu regresyon analizini başlatıyoruz.
Forced-Entry Çoklu Regresyon SPSS Tablo Yorumlama
SPSS’te “forced-entry” metoduyla yaptığımız çoklu doğrusal regresyon analizinin sonucunda 3 tane bakmamız gereken tablomuz olacak. Bunlar regresyon modelinin istatistiksel olarak anlamlı olup olmadığı, bağımsız değişkenlerin bağımlı değişkeni açıklama gücü, regresyon katsayıları ve yönü hakkındadır.
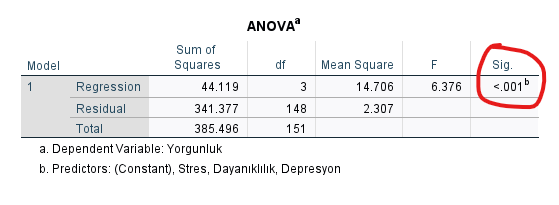
1) ANOVA Tablosu
ANOVA tablosundaki Sig. değeri, p değeridir. Bu değer, SPSS’in kurduğu regresyon modelinin, rastgele bir dağılımdan anlamlı şekilde farklı olup olmadığını belirlemeye yarar. Eğer ANOVA tablosundaki p değeri 0.05’ten küçükse, bağımsız değişkenler, bağımlı değişkenin istatistiksel olarak anlamlı bir miktarını açıklayabiliyor demektir.
Bu tablonun başlığının ANOVA olması bizim gerçek bir ANOVA Testi yaptığımız anlamına gelmez. Sadece “regresyon analizi modelindeki bağımsız değişkenlerin bağımlı değişkeni açıklama miktarının sıfırdan anlamlı olarak daha yüksek olup olmadığını” gösteren regresyon analizi öğesidir bu tablo.
Bu tablodaki p değeri bütün bağımsız değişkenlerin birlikte modele sokulmasıyla yapılan regresyon analizinin anlamlılık değeridir. Eğer bu değer 0.05’in altında ise, regresyon analizi modelimiz istatistiksel olarak anlamlı demektir.
Bu örnekte 0.05’in altında bir p değeri bulduk. Yani Stres, Dayanıklılık ve Depresyon değişkenleri, Yorgunluk bağımlı değişkeninde anlamlı bir açıklayıcı etkiye sahipmiş.
2) Regresyon Model Özeti
“Model Summary” tablosundaki Adjusted R Square değeri (yani düzeltilmiş R-kare değeri), modelin bağımsız değişkenlerinin bağımlı değişken üzerindeki değişimi toplu olarak açıklama gücünü ifade eder.
Bu örnekte Adjusted R Square değeri 0.096 çıkmış, yani “modeldeki değişkenler, Yorgunluk düzeyindeki değişimin %9.6’sını açıklayabiliyor” diyebiliriz. Yorgunluk düzeyindeki kalan %90.4’lük değişim de, bu modelde olmayan, bilinmeyen başka faktörlere bağlıdır.

Basit Doğrusal Regresyon Analizi’nde “R Square” değerine bakıyorduk ama Çoklu Doğrusal Regresyon Analizi’nde “Adjusted R Square” değerine bakıyoruz.
3) Regresyon Katsayıları
Asıl detaylı bakmak gereken tablo bu aslında.
“Coefficients” tablosundaki Sig. değerleri, çoklu regresyon analizindeki her bir bağımsız değişkenin ayrı ayrı bağımlı değişken üzerindeki etkisinin p değerini yani istatistiksel anlamlılık düzeyini gösteriyor. Bu tabloya göre Depresyon, Yorgunluk üzerinde anlamlı bir etkiye sahipmiş (çünkü p değeri 0.006 yani 0.05’ten küçük). Dayanıklılık, Yorgunluk üzerinde anlamlı bir etkiye sahip değilmiş (p = 0.580). Stres de Yorgunluk üzerinde anlamlı bir etkiye sahipmiş (p = 0.012).
- Tablodaki B değerine bakarak “Depresyon seviyesinde 1 puanlık artış, Yorgunluk seviyesinde 0.202 puanlık bir artışı anlamlı şekilde öngörmektedir.” veya “Stres seviyesinde 1 puanlık artış, Yorgunluk seviyesinde 0.372 puanlık bir düşüşü anlamlı şekilde öngörmektedir.” şeklinde yorumlar yapabiliriz.
“Dayanıklılık arttıkça yorgunluk artar” gibi bir yorumlama yapamıyoruz çünkü p değerini 0.580 bulmuştuk yani Dayanıklılık’ın Yorgunluk üzerindeki etkisi anlamsızdır (p değeri 0.05’ten büyük olduğu için). Etki istatistiksel olarak anlamsız olunca da doğal olarak “etkisi var” diyemiyoruz.
- Beta değerlerine bakarak da “Depresyon seviyesinde 1 standart sapmalık artış, Yorgunluk seviyesinde 0.220 standart sapmalık bir artışı anlamlı şekilde öngörmektedir.” veya “Stres seviyesinde 1 standart sapmalık artış, Yorgunluk seviyesinde 0.204 standart sapmalık bir düşüşü anlamlı şekilde öngörmektedir.” şeklinde yorumlar yapabiliriz.
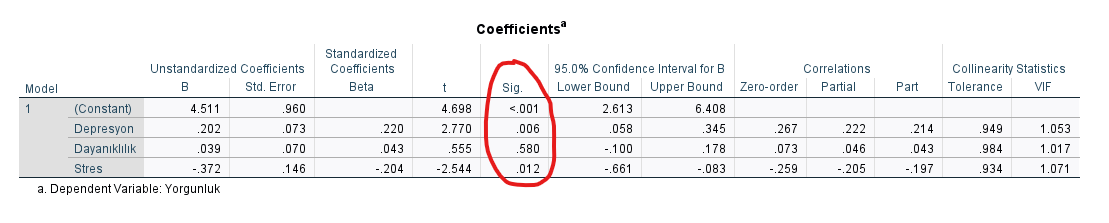
Sonuç olarak hem Depresyon, hem de Stres, Yorgunluk düzeyini anlamlı olarak etkiliyormuş. Peki hangisinin Yorgunluk üzerindeki etkisi diğerinden daha büyük? Bunu da bu tablodan bulabiliriz.
B ile gösterilen düz regresyon katsayısı eksi sonsuzdan artı sonsuza kadar her sayı olabilirken, Beta değeri yani standardize edilmiş regresyon katsayısı yalnızca -1 ile +1 arasında değer alabilir. Beta değeri bu sayede ölçüm aralığı farklı olabilen iki veya daha fazla bağımsız değişkenin bağımlı değişken üzerindeki etkisini karşılaştırmaya yarar.
Beta değeri 0’a daha uzak olan (-1’e veya +1’e daha yakın olan) bağımsız değişkenin bağımlı değişken üzerindeki etkisi daha büyüktür.
B değeri ölçüm aralığından etkilendiği için iki veya daha fazla bağımsız değişkenin bağımlı değişken üzerindeki etkisini karşılaştırmak için B değerine bakmak uygun değildir. Beta değerine bakılmalıdır.
Mesela, bu örneğimizde Depresyon’un Yorgunluk üzerindeki etkisi, Stres’in Yorgunluk üzerindeki etkisinden daha büyükmüş çünkü Beta değeri daha büyük. (Beta değerinin – ya da + olması fark etmez, 0’a uzaklığı önemlidir)
Bonus Ek Bilgi:
Bu tabloda Correlations bölümündeki Partial sütunu, kısmi korelasyonu (yani diğer değişkenlerin etkileri kontrol edildiğinde bir bağımsız değişkenin bağımlı değişken üzerindeki etkisini) göstermektedir.
Part değerinin karesini alırsak da, o satırdaki bağımsız değişkenin tek başına bağımlı değişkendeki varyansın yüzde kaçını açıklayabiliyor olduğunu buluruz. (Mesela depresyon için hesaplarsak 0.214 * 0.214 = 0.046 yani “depresyon bağımlı değişken olan yorgunluktaki varyansın %4.6’sını tek başına açıklayabiliyor” şeklinde yorumlayabiliriz.)Bu tablonun Part-Partial bölümü hakkında detaylı bilgi merak ediyorsanız onun hakkında yazdığım diğer yazıyı okuyabilirsiniz.

Tekrar SPSS’te Forced-Entry Regresyon (Sadece Anlamlı Bağımsız Değişkenlerle)
İlk başta test ettiğimiz modelde 3 tane bağımsız değişken vardı: Depresyon, Dayanıklılık, Stres. Yukarıda yaptığımız forced-entry regresyon analizinde bunlardan sadece Depresyon ve Stres’in bağımlı değişken olan Yorgunluk üzerinde anlamlı etkisi olduğunu bulduk. Şimdi, bir tane forced-entry regresyon analizi daha yapalım, bu sefer sadece deminki analizde anlamlı çıkan değişkenler olsun (yani Depresyon ve Stres). Bu adım öncekilere göre baya kısa sürecek.
(Aslında deminki analizi yaptıktan sonra anlamsız olan bağımsız değişkeni çıkartıp yeniden analiz yapmaya gerek yok, fakat konuyu öğretirken faydalı oluyor diye bir örnek daha yapmış olmak adına aşağıdaki analiz örneğini de göstermek istedim.)
Yine Analyze -> Regression -> Linear basıyoruz.
Dayanıklılık değişkenini analiz kutusundan çekip soldaki kutuya geri atıyoruz. Başka hiçbir değişiklik yapmadan “OK”a basıyoruz ve analizi başlatıyoruz.
Tablolardan ANOVA tablosundaki Sig. sütunundaki değer yani p değeri 0.001’den küçük çıkmış. Bu p değeri 0.05’ten küçük olduğu için 2 bağımsız değişkenli yeni regresyon modelimiz de hâlâ istatistiksel açıdan anlamlı.
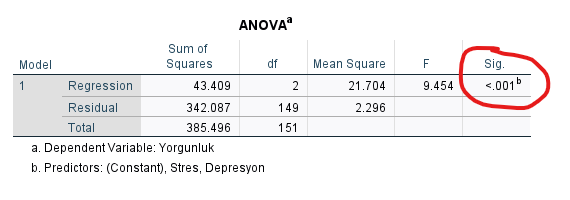
“Model Summary” tablosundaki Adjusted R Square değeri, modelin bağımsız değişkenlerinin bağımlı değişken üzerindeki değişimi açıklama gücünü ifade eder demiştik. Bu yeni regresyon analizi tablosunda 0.101 çıkmış (eskisi 0.096’ydı), yani yeni modeldeki iki değişken, Yorgunluk üzerindeki değişimin toplam %10.1’sını açıklayabiliyor.
Demin 3 değişkenle yaptığımız ilk forced-entry regresyon analizindeki model, Yorgunluk üzerindeki değişimin %9.6’sını açıklıyordu. Yeni yaptığımız 2 değişkenli regresyon modeli, Yorgunluk üzerindeki değişimi daha iyi açıklamış. O zaman “ikisi de anlamlı etkiye sahip 2 değişkenle yaptığımız regresyon analizi, biri anlamsız ikisi anlamlı 3 değişkenle yaptığımız regresyon analizinden daha iyi bir tahmin gücüne sahiptir” diyebiliriz.
En son modelimiz Yorgunluk üzerindeki değişimin %10.1’sını açıklayabiliyorsa, Yorgunluk’taki kalan %89.9’luk değişim, bu modelde olmayan bilinmeyen başka faktörlere bağlıdır.
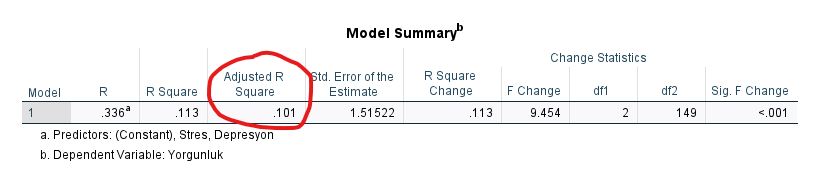
“Coefficients” tablosundaki Sig. sütunu p değerlerini göstermektedir. Bu sütundaki değerler, her bir bağımsız değişkenin, bağımlı değişken üzerinde anlamlı bir etkisi olup olmadığının bilgisini verir. Eğer bir satırdaki p değeri 0.05’ten küçük ise o satırdaki bağımsız değişkenin bağımlı değişken üzerindeki etkisi anlamlı demektir. Bu tabloya göre hem Depresyon hem de Stres, bağımlı değişken olan Yorgunluk üzerinde anlamlı bir değişime sebep olmaktadır (çünkü p değerleri sırayla 0.006 ve 0.009).
B değeri, her bağımsız değişkenin ölçüldüğü ölçekteki 1 birimlik değişimin, bağımlı değişken üzerinde kaç birimlik değişime sebep olduğunu söylüyor. Örneğin:
- Depresyon’daki 1 puanlık değişim, Yorgunluk’ta 0.201 puanlık bir artışa sebep oluyor.
- Stres’teki 1 puanlık değişim, Yorgunluk’ta 0.382 puanlık azalışa sebep oluyor.
Beta değeri ise, farklı değişkenlerin ölçeklerinin standardize edilmesiyle bulunan bir değerdir. Burada, değerlerin kendisi değil de standart sapmaları üzerinden bir yorumlama yapılmaktadır. Beta değerleri şöyle okunur:
- Depresyon’daki değerde 1 standart sapmalık artış, Yorgunluk’ta 0.219 standart sapmalık artışa sebep oluyor.
- Stres’teki 1 standart sapmalık artış, Yorgunluk’ta 0.209 standart sapmalık azalışa sebep oluyor.
Beta değerlerini karşılaştırarak, Depresyon’un Yorgunluk üzerindeki etkisi Stres’in Yorgunluk üzerindeki etkisinden biraz daha fazladır şeklinde düşünebiliriz.

Son olarak, modelimizdeki hangi bağımsız değişkenlerin bağımlı değişkene ne kadar etki ettiğini bulmak için Coefficients tablosundaki Part sütununa bakıyoruz.
Part değerinin karesini alıp sonra onu yüzde cinsinden yazarsak, o bağımsız değişkenin, tek başına bağımlı değişkendeki değişimi yüzde kaç açıkladığını öğreniyoruz.
- Bu örnekte Depresyon’un Part değeri 0.214. Karesini alırsak 0.046 ediyor. Yani Depresyon, Yorgunluk’taki değişimin %4.6’sını açıklıyormuş.
- Benzer şekilde Stres’in Part değeri -0.204. Karesini alırsak 0.041 ediyor. Yani Stres, Yorgunluk’taki değişimin %4.1’ini açıklıyormuş.
Yorgunluk seviyesi üzerinde depresyon faktörünün etkisinin stres faktörüne göre daha yüksek olduğunu Beta katsayısının yanı sıra buradan da anlayabiliriz.
SPSS programında Forced-Entry metoduyla Çoklu Doğrusal Regresyon Analizi yapmak hakkında anlatmak istediğim her şey bu kadardı. Artık analiz sonuçlarının raporlanmasına geçilebilir. Okuduğunuz için teşekkürler, kolay gelsin.
Bir yanıt bırakın