
İçindekiler
SPSS’te Çoklu Doğrusal Regresyon Analizi yapmanın birden fazla yöntemi bulunmaktadır. “Hiyerarşik Çoklu Regresyon” yöntemi, bağımsız değişkenlerin regresyon analizi modeline belli bir sırayla eklenip bağımlı değişken üzerindeki etkilerinin test edildiği Çoklu Regresyon Analizi yöntemidir. Bu yazıda Hiyerarşik Çoklu Regresyon metodunun ne olduğunu, SPSS ile nasıl yapıldığını ve analiz sonuçlarının nasıl yorumlanması gerektiğini anlatıyorum.
Hiyerarşik Çoklu Regresyon Metodu Nedir?
Hiyerarşik Çoklu Regresyon metodu, Çoklu Doğrusal Regresyon Analizi’nin bir türüdür. Hiyerarşik Çoklu Regresyon yönteminde, bağımsız değişkenler belirli bir sıra veya hiyerarşiye göre regresyon analizi modeline eklenir. İlk adımda temel değişkenler eklenir, ardından bir sonraki adımda ise etkisi asıl merak edilen değişkenler eklenir. Bu, her bir adımda modelin daha karmaşık hale getirilmesine olanak tanır. Bu süreç, eklenen her bağımsız değişkenin modeldeki açıklama gücünü ve etkisini kendisinden önce gelen değişkenlerin etkileri göz önünde bulundurularak değerlendirmeyi sağlar.
Mesela diğer bir Çoklu Doğrusal Regresyon Analizi yöntemi olan Forced-Entry Çoklu Regresyon yönteminde bütün bağımsız değişkenler regresyon analizi modeline aynı anda dahil edilirken, Hiyerarşik Regresyon Analizi’nde bağımsız değişkenler belli bir sıraya (hiyerarşiye) göre sırayla dahil edilir.
Hiyerarşik Çoklu Regresyon yönteminin temel avantajlarından biri, değişkenlerin regresyon analizine belirli bir sıra içinde eklenmesi sayesinde farklı bağımsız değişkenlerin birbirleriyle etkileşimi sonucundaki ortak etkileri göz önüne alınarak kurulan çoklu regresyon modelinde çeşitli değişkenlerin modelin tahmin edici gücünü arttırma yeteneğini derinlemesine inceleme olanağı tanımasıdır.
Hiyerarşik Çoklu Regresyon Yönteminin Tercih Edilme Sebepleri
Bağımsız değişkenlerin hepsini aynı anda çoklu regresyon modeline sokmak yerine hiyerarşik regresyon yapmanın 2 tane temel sebebi vardır:
- Yaş, cinsiyet gibi değişkenlerin etkisini kontrol etmek: Bu yöntemde kontrol değişkenleri (yaş, cinsiyet) regresyon modeline önceden sokulur. Bağımlı değişkene etkisini merak ettiğimiz asıl bağımsız değişkenler (mesela stres seviyesi) modele sonradan sokulur. Bu şekilde, asıl incelenmek istenen stres, yaşam doyumu gibi bağımsız değişkenlerin etkileri yaş, cinsiyet gibi kontrol değişkenlerinin etkileri izlenirken bile incelenebilir.Örneğin bir araştırmada anksiyete düzeyi üzerinde sosyal medya kullanım süresinin ve uyku kalitesinin etkilerini incelemek istiyoruz. Ancak anksiyete düzeyi sadece sosyal medya kullanım süresinden ve uyku kalitesinden etkilenmeyebilir; yaş ve cinsiyet gibi demografik özellikler de anksiyete düzeyini sosyal medya kullanım süresi ve uyku kalitesinden ayrı olarak etkileyebilir. Bu yüzden sosyal medya kullanım süresinin ve uyku kalitesinin anksiyete üzerindeki net etkisinin yaş ve cinsiyet faktörlerinin etkisi göz önünde bulundurulduğunda bile anlamlı düzeyde olup olmadığını incelemek için, yaş ve cinsiyet değişkenlerini kontrol ederek hiyerarşik regresyon analizi yapmak isteyebiliriz. Bu doğrultuda hiyerarşik regresyon analizinde ilk adımda yaş ve cinsiyet modele dahil edilir. İkinci adımda ise sosyal medya kullanım süresi ve uyku kalitesi modele eklenir. Böylece yaş ve cinsiyetin etkisi sabit tutulduğunda, sosyal medya kullanım süresi ve uyku kalitesinin anksiyete düzeyini yaş ve cinsiyetten bağımsız olarak kendi başlarına ne kadar açıkladığını görebiliriz.
- Bağımlı değişkene (mesela depresyon) etkisi önceden bilinen bağımsız değişkenler (mesela stres) modele önce sokulur, etkisi henüz bilinmeyen bağımsız değişkenler (mesela sosyal medya kullanım süresi) modele sonradan sokulur. Bu şekilde de eklenen yeni bağımsız değişkenin modelin tahmin gücünü anlamlı olarak arttırıp arttırmadığı incelenir.Depresyon üzerinde stresin etkisi olduğunu teorik olarak önceden biliyoruz. Diyelim ki sosyal medya kullanım süresinin depresyon üzerinde etkisi olup olmadığından teorik olarak emin değiliz ve bunu araştırıyoruz. O zaman, bir hiyerarşik regresyon analizi yapıp, analiz modeline birinci adımda stres değişkenini, ikinci adımda sosyal medya kullanım süresi değişkenini ekleyebiliriz. Bu sayede, stres düzeyinin depresyon üzerindeki etkisini göz önünde bulundurduktan sonra bile sosyal medya kullanım süresinin depresyon üzerinde anlamlı etkisinin olup olmadığını hiyerarşik regresyon analiziyle görmüş oluruz.

Hiyerarşik Çoklu Regresyon Varsayımları
Linke tıklayarak çoklu doğrusal regresyon varsayımlarını test etme konusunda yazdığım diğer yazıyı okuyabilir ve çoklu regresyon analizinin bütün varsayımlarının nasıl test edileceğini öğrenebilirsiniz.
SPSS’te yapacağımız hiyerarşik çoklu regresyon analizinde bulduğumuz sonuçlara güvenebilmemiz için, verimizin regresyon analizi öncesinde bazı varsayımları sağlıyor olması gerekir. Önce regresyon analizi varsayımlarının sağlandığından emin olup, regresyon analizini ondan sonra yapmak gerekir. Bu varsayımlar şunlardır:
- Bütün bağımsız ve bağımlı değişkenlerin devamlı veri tipinde olması gerekir.
- Veride çok değişkenli (multivariate) uç değer olmaması gerekir.
- Gözlenen ile beklenen değerlerin farkının yani “artık değerlerin” (Residual’ların) normal dağılım göstermesi gerekir.
- Bağımsız değişkenlerin hiçbiri, bağımlı değişken ile lineer olmayan bir ilişki göstermemelidir. Yani eğrisel ilişki olmamalıdır. (Doğrusal İlişki Varsayımı)
- Bağımsız değişkenlerin herhangi ikisini ele aldığımızda, bu iki değişkenin birbiriyle 0.70’ten fazla korelasyon göstermemesi gerekir. (Çoklu Bağlantısızlık Varsayımı)
- Hata varyansları bağımsız değişkenlerin büyüklüğüne göre değişkenlik göstermemelidir. (Homoskedastisite)
- Otokorelasyon olmamalıdır. (Durbin-Watson testi)
Çoklu doğrusal regresyon analizinin varsayımlarını test etme işi epey uzundur ve analizin kendisinden daha kafa karıştırıcı olabilmektedir. Bu sayfada hem çoklu doğrusal regresyon analizi yapmayı hem de varsayımları test etmeyi anlatırsam çok kafa karıştırıcı olabilir. Bu sebeple, bu sayfada varsayımların nasıl test edileceğinden bahsetmeden, yalnızca hiyerarşik çoklu regresyon analizi yapmayı ve sonuçları yorumlamayı göstereceğim.
Linke tıklayarak çoklu doğrusal regresyon varsayımlarını test etme konusunda yazdığım diğer yazıyı okuyabilir ve hiyerarşik çoklu regresyon analizi için bütün varsayımlarının SPSS’te nasıl test edileceğini öğrenebilirsiniz.
SPSS ile Hiyerarşik Çoklu Regresyon Nasıl Yapılır?
SPSS’te Hiyerarşik Çoklu Regresyon Analizi yapmak için aşağıdaki adımları takip edebiliriz.
Bu sayfada yapacağımız örnekte, 3 tane bağımsız, 1 tane bağımlı değişkenimiz var: Depresyon, Dayanıklılık ve Stres faktörlerini sırayla hiyerarşik çoklu regresyon analizi modeline sokup, Yorgunluk seviyesi üzerindeki birbirinin varlığındaki etkilerine bakacağız.
Analyze -> Regression -> Linear
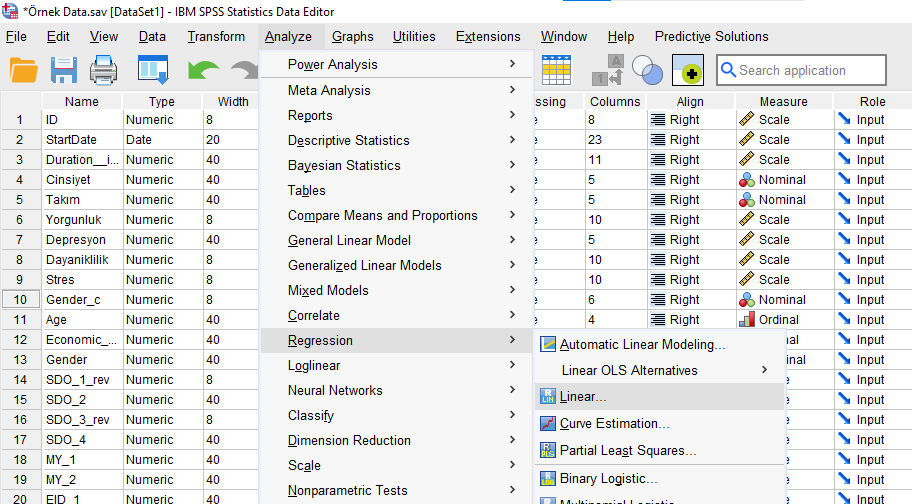
Açılan Linear Regression penceresinde, bağımlı değişkenimizi Dependent kutusuna koyuyoruz. Bağımsız değişkenlerimizden önce sadece 1 tanesini, Independent(s) kutusuna koyuyoruz. Bu kutunun altındaki “Method” kısmında “Enter” seçili olması lazım.
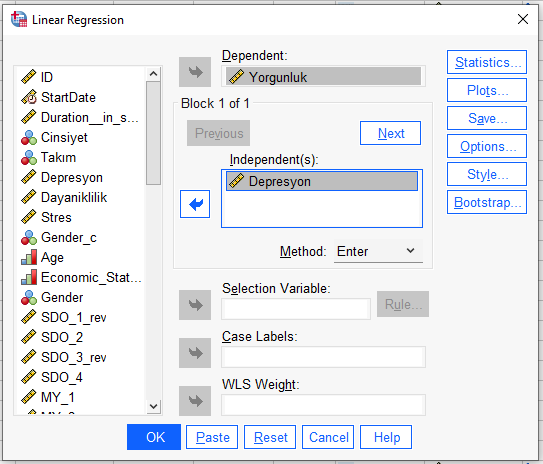
İlk değişkeni koyduktan sonra, “Next” butonuna basıyoruz ve Independent(s) kutusuna ikinci bağımsız değişkeni ekliyoruz.
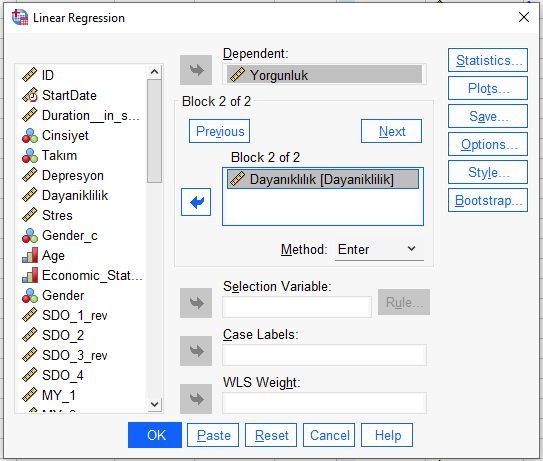
Sonra yine “Next”e basarak, üçüncü bağımsız değişkeni ekliyoruz.
(Daha fazla bağımsız değişkeniniz varsa tüm bağımsız değişkenleri eklemiş olana kadar böyle yapın.)
(İlla her seferinde 1 adet bağımsız değişken eklemek zorunda değilsiniz. Mesela “yaş ve cinsiyetin etkisinin kontrol edildiği koşulda stres ve depresyon düzeyinin yorgunluk üzerindeki etkilerine bakmak istediğimiz başka bir analiz modeli düşünelim. O zaman ilk aşamada yaş ve cinsiyeti, ikinci aşamada da stres ve depresyon değişkenlerini modele eklerdik. Böyle bir hiyerarşik regresyon analizi yapmış olurduk. Değişkenlerin hiyerarşik regresyon analizi modeline eklenme sırası tamamen size kalmış.)
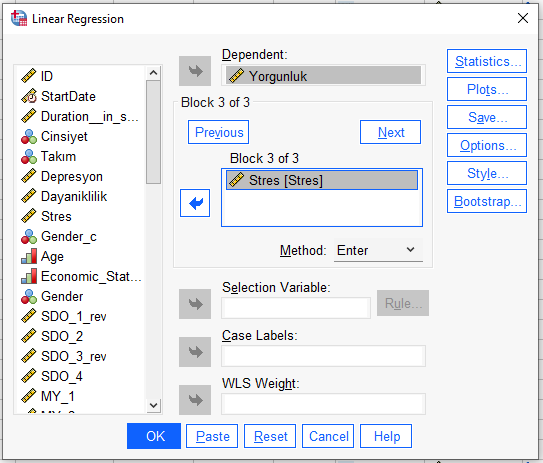
Daha sonra, “Statistics” butonuna basarak, açılan yeni pencerede, aşağıdaki kutucukları işaretliyoruz. Sonra “Continue”ya basıyoruz.
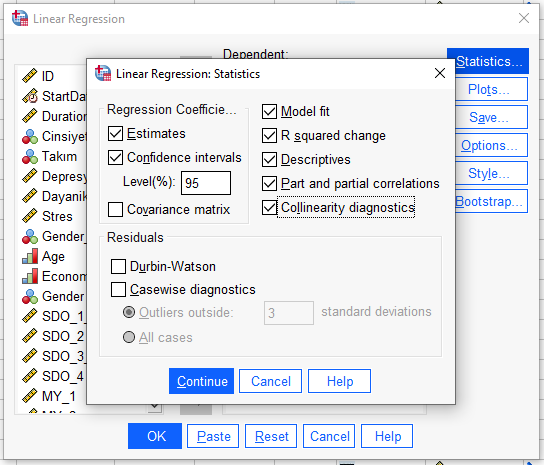
Son olarak, “OK” butonuna basarak SPSS’te Hiyerarşik Çoklu Regresyon analizimizi başlatıyoruz.

Hiyerarşik Çoklu Regresyon SPSS Tablo Yorumlama
Hiyerarşik Çoklu Regresyon analizi sonucu SPSS birtakım tablolar verecektir. Eğer bağımsız değişkenleri modele 3 ayrı aşamada yerleştirmişsek (bu örnekte yaptığım gibi) o zaman her tabloda 3 ayrı bölümde 3 ayrı model gösterilir. (5 ayrı aşamada yerleştirmişsek 5 model gösterilir). Model numarası her tablonun en sol sütununda rakamla gösterilir.
Bizim örneğimizde:
- Birinci model sadece Depresyon’un Yorgunluk üzerindeki etkisine bakan modeldir.
- İkinci model Depresyon ve Dayanıklılık’ın Yorgunluk üzerindeki birlikte etkisine bakan modeldir.
- Üçüncü model Depresyon, Dayanıklılık ve Stres’in Yorgunluk üzerindeki birlikte etkisine bakan modeldir.
Bu modellerin her birinde model uyumundaki değişimi ve modelde önceden bulunan bağımsız değişkenlerin etkileriyle anlamlılık durumundaki değişimi incelerken, aynı zamanda modele sonradan eklediğimiz değişkenlerin etkilerini ve anlamlılık durumlarını da inceliyor olacağız.
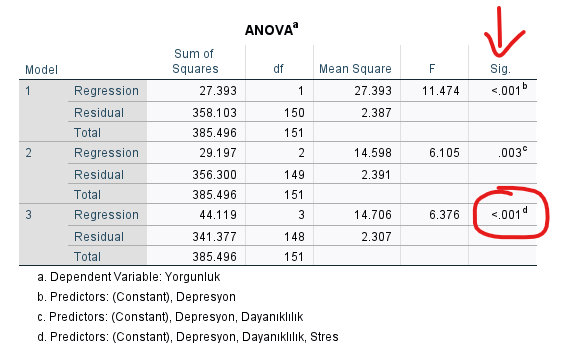
1) ANOVA Tablosu
ANOVA tablosundaki Sig. değeri, p değeridir. Bu değer, SPSS’in kurduğu regresyon modelinin, bağımlı değişken üzerinde anlamlı bir açıklama gücüne olup olmadığını belirlemeye yarar. Her bir model için ayrı ayrı olmak üzere, bir modeldeki p değeri 0.05’ten küçükse, o modeldeki bağımsız değişken(ler) bağımlı değişkenin anlamlı miktarını açıklamaktadır anlamına geliyor.
p değeri 0.05’ten küçükse “istatistiksel olarak anlamlı” kabul ediyoruz bütün analizlerde.
İlk satırdaki p değeri, tek bağımsız değişkenin (Depresyon) modele sokulmasıyla yapılan regresyon analizinin Yorgunluk üzerindeki açıklayıcı etkisine dair anlamlılık değeridir. İkinci satırdaki p değeri, iki tane bağımsız değişkenin (Depresyon ve Dayanıklılık) modele sokulmasıyla yapılan regresyon analizinin Yorgunluk üzerindeki açıklayıcı etkisine dair anlamlılık değeridir. Son satırdaki p değeri de bütün bağımsız değişkenlerin (Depresyon, Dayanıklılık, Stres) birlikte modele sokulmasıyla yapılan regresyon analizinin Yorgunluk üzerindeki açıklayıcı etkisine dair anlamlılık değeridir.
Bu örnekte 3 modelde de 0.05’in altında bir p değeri bulduk. Demek ki hiyerarşik regresyon analizi kapsamında kurduğumuz her model Yorgunluk düzeyinin anlamlı bir kısmını açıklayabilmektedir.
2) Modellerin Karşılaştırılması
Aşağıdaki “Model Summary” tablosunda kırmızı yuvarlak içine aldığım yerlere ve mavi yuvarlak içine aldığım yerin solundaki R Square sütununa bakalım. (Mavi yuvarlağa bakmıyoruz yani onu yanlışlıkla seçtim)
- R Square, R Kare demektir ve bağımsız değişkenlerin toplu olarak bağımlı değişkendeki değişimi açıklama gücünü ifade eder.
- R Square Change, modele dahil olan her yeni değişkenin modelin açıklama gücünü eski modele göre ne kadar iyileştirdiğini gösterir.
- Sig F Change ise yeni modelin eski modele göre istatistiksel olarak anlamlı şekilde daha yüksek açıklama gücü olup olmadığını belirlemeye yarayan p değeridir.
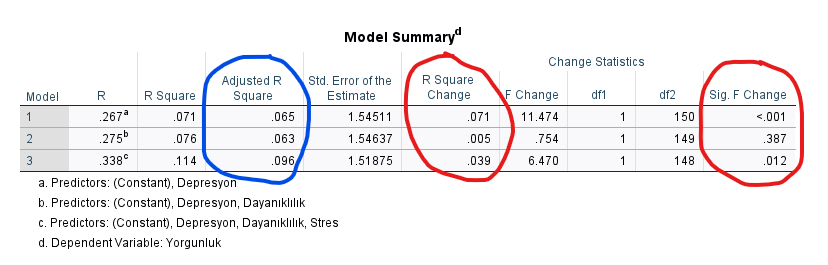
- Bu örnekteki tabloyu inceleyecek olursak, modele sadece Depresyon dahilken R Kare değeri 0.071 olmuş. Depresyon’un regresyon modeline dahil edilmesi, istatistiksel olarak anlamlı bir şekilde (çünkü 1. satır için p < 0.001) R Kare’yi arttırmış. Yani Yorgunluk seviyesini tahmin etmede Depresyon’un anlamlı bir etkisi olmuş.
- Bunun üzerine Dayanıklılık modele eklendiği zaman R Kare değeri 0.071’den 0.076’ya çıkmış. Dayanıklılık’ın regresyon modeline dahil edilmesi, istatistiksel olarak anlamlı bir şekilde R Kare’yi arttırmamış (çünkü 2. satır için p = 0.387). Yani Yorgunluk seviyesini tahmin etmede Dayanıklılık’ın ekstradan anlamlı bir katkısı olmamış.
- Bunun üzerine Stres modele eklendiği zaman R Kare değeri 0.076’dan 0.114’e çıkmış. Stres’in regresyon modeline dahil edilmesi, istatistiksel olarak anlamlı bir şekilde R Kare’yi arttırmış (çünkü 3. satır için p = 0.012). Yani modele Stres’in dahil edilmesi, Yorgunluk seviyesini tahmin etmede Depresyon’a ek olarak anlamlı bir katkı sağlamış ve modeli iyileştirmiş.
Yani buradan, “Depresyon ve Stres, bağımlı değişken olan Yorgunluk üzerinde anlamlı bir etkiye sahiptir” sonucunu çıkartabiliriz. Dayanıklılık’ın ise Yorgunluk üzerinde istatistiksel olarak anlamlı bir etkisi yokmuş.
Bunun sağlamasını R Square Change değerlerine bakarak da yapabiliriz. Depresyon, modeldeki R Kare değerini 0.071 miktarında arttırmış. Sonra modele eklediğimiz Dayanıklılık, modeldeki R Kare’yi sadece 0.005 arttırmış. Modele en son eklediğimiz Stres ise, modeldeki R Kare’yi 0.039 arttırmış. Bu tablodaki Sig. F Change sütunundaki p değerlerine bakarak da, hangi R Kare artışlarının istatistiksel olarak anlamlı olduğunu görmüş olduk.
3) Regresyon Katsayıları
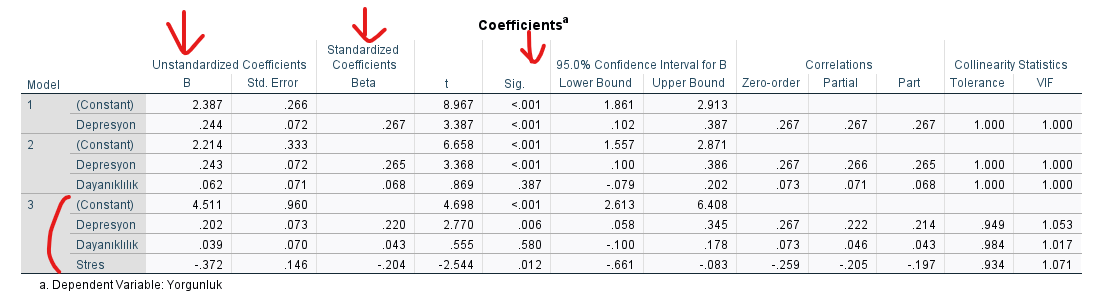
Aşağıdaki “Coefficients” başlıklı tabloda 1., 2. ve 3. modellere ait bağımsız değişkenleri ve onların regresyon katsayılarıyla diğer bilgilerini görebilirsiniz. Bir üstteki “Model Summary” tablosunda gördüğümüz üzere modeli anlamlı olarak iyileştiren en son model 3. model olduğu için, biz bu örnekte nihai sonuçları 3. modelin olduğu bölümden okumalıyız.
Eğer yine bu örnekteki gibi 3 modelimiz olsaydı fakat bu örnektekinin aksine Model Summary tablosundaki sonuçlara göre 2. modelin anlamlı olarak iyileşme sağladığını ve 3. modelin anlamlı iyileşme sağlamadığını bulsaydık, o zaman regresyon katsayılarını 2. model sonuçlarına bakarak yorumlamamız daha sağlıklı olacaktı.
Sig. sütunundaki değer yani p değeri, her bağımsız değişkenin, bağımlı değişkendeki değişim üzerinde anlamlı bir etkisi olup olmadığı bilgisini verir. Eğer p değeri 0.05’ten küçük ise anlamlı demektir. Bu örnekte Depresyon ve Stres’in, bağımlı değişken olan Yorgunluk üzerinde anlamlı bir etkisi bulunmaktadır (çünkü p değerleri sırayla 0.006 ve 0.012), fakat Dayanıklılık Yorgunluk üzerinde anlamlı bir etkiye sahip değildir (çünkü p değeri 0.580).
- B değeri, her bağımsız değişkenin ölçüldüğü ölçekteki 1 puanlık değişimin, bağımlı değişken üzerinde kaç puanlık değişime sebep olduğunu söylüyor. Örneğin Depresyon’daki 1 puanlık artış, Yorgunluk’ta 0.202 puanlık bir artışa sebep oluyor. Stres’teki 1 puanlık artış, Yorgunluk’ta 0.372 puanlık azalışa sebep oluyor. Dayanıklılık satırındaki p değeri istatistiksel olarak anlamsız olduğu için (p değeri 0.05’ten büyük diye) bu değişkendeki artış veya azalışın Yorgunluk’ta ne kadar artış veya azalışa sebep olduğunu yorumlamıyoruz.
- Beta değeri ise, farklı değişkenlerin ölçeklerinin standardize edilmesiyle bulunan bir değerdir. Burada, değerlerin kendisi değil de standart sapmaları üzerinden bir yorumlama yapılmaktadır. B değeri eksi sonsuzdan artı sonsuza kadar her sayı olabilirken, Beta değeri yalnızca -1 ile +1 aralığında bir sayı olabilir. Beta değerleri şöyle okunur: “Depresyondaki değerde 1 standart sapmalık artış, Yorgunlukta 0.220 standart sapmalık artışa sebep olur; Stresteki 1 standart sapmalık artış, Yorgunlukta 0.204 standart sapmalık azalışa sebep olur”.
İki bağımsız değişkenin bağımlı değişken üzerindeki etkisi anlamlıysa, hangi bağımsız değişkenin bağımlı değişken üzerinde daha büyük etkisi olduğunu incelemek istersek B değil Beta değerine bakmalıyız. Beta değerinin eksi ya da artı işaretli olması fark etmez, sıfır sayısına uzaklığı daha fazla olan bağımsız değişkenin etkisi daha büyük deriz. Yani bu örnekte Depresyon’un Yorgunluk üzerindeki etkisi, Stres’in Yorgunluk üzerindeki etkisine göre anlamlı olarak daha büyüktür.
Ek Bilgi:
Bu tabloda Correlations bölümündeki Partial, kısmi korelasyonu (yani diğer değişkenlerin etkileri kontrol edildiğinde bir bağımsız değişkenin bağımlı değişken üzerindeki etkisini) göstermektedir.
Part değerinin karesini alırsak ise, o satırdaki bağımsız değişkenin tek başına bağımlı değişkendeki varyansın yüzde kaçını açıklayabiliyor olduğunu buluruz. (Mesela 3 numaralı modelde depresyon için hesaplarsak 0.214 * 0.214 = 0.046 yani “depresyon bağımlı değişkendeki varyansın %4.6’sını tek başına açıklayabiliyor” şeklinde yorumlayabiliriz.)Bu tablonun bu bölümü hakkında detay merak ediyorsanız part-partial tablosu hakkında yazdığım diğer yazıyı okuyabilirsiniz.
Hiyerarşik Çoklu Doğrusal Regresyon Analizi yaptık ve sonucunda gördük ki Depresyon ve Stres değişkenleri Yorgunluk üzerinde anlamlı etkiye sahipken, Dayanıklılık değişkeni Yorgunluk üzerinde bir etkiye sahip değilmiş. Artık yaptığımız hiyerarşik regresyon analizi sonucunda bulduğumuz değerleri raporlama aşamasına geçebiliriz.
Bir yanıt bırakın