
Veri setinizdeki gözlemlenen değerlerin beklenen değerlerden farklı dağılıp dağılmadığını görmek için ki kare uygunluk testi (chi-square test of goodness of fit) kullanabilirsiniz. Bu test, gözlemlenen ve beklenen frekanslar arasındaki farkın istatistiksel olarak anlamlı olup olmadığını değerlendirmenize olanak tanır. Test sonucunda elde edilen p-değerine bakarak, gözlemlenen ve beklenen frekanslar arasındaki farkın rastgele olup olmadığını belirleyebilirsiniz.
Eğer test sonucunda bulduğunuz p-değeri belirli bir anlamlılık düzeyinden (genellikle 0.05) küçükse, gözlemlenen ve beklenen frekanslar arasında istatistiksel olarak anlamlı bir fark olduğu söylenebilir. Bu durumda, hangi kategorilerde fark olduğunu belirlemek için ayrıntılı bir post hoc analiz yapabilirsiniz. Bu analiz, farklı kategoriler arasındaki karşılaştırmaları içerebilir ve farklı kategoriler arasındaki farkın kaynağını anlamak için daha fazla bilgi sağlayabilir.
Bu sayfada bunun SPSS programıyla nasıl yapıldığını anlatıyorum. Biraz uzun fakat istatistiksel açıdan güçlü bir yöntemdir.

SPSS ile Ki Kare Uygunluk Testi Post Hoc Analizi Nasıl Yapılır?
UYARI: Bu yöntem, sadece bütün değerlerin beklenen frekanslarının birbirine eşit olduğu durumda işe yarayan bir yöntemdir.
Ki kare uygunluk testi için post hoc analizimizi, SPSS ile bütün takım çiftleri için binom testi (binomial test) yaparak gerçekleştireceğiz. Aşağıdaki adımları düzenli şekilde takip ederseniz siz de zorlanmadan yapabilirsiniz.
Bu örnekte post hoc analizini yapacağımız ki kare uygunluk testimizde, verimizdeki katılımcılar 5 farklı takımdan birini tutuyorlardı: Galatasaray, Fenerbahçe, Beşiktaş, Karşıyaka, Göztepe. Bunların aralarında nasıl ikili kombinasyonları olabilir diye önce bir tablo yapıp bakalım. (Bu tabloyu siz de oluşturun ve sonra silmeyin, lazım olacak)

Bu örnek veri setinde değişkenler SPSS’e şu şekilde kodlanmıştı:
1 = Galatasaray
2 = Fenerbahçe
3 = Beşiktaş
4 = Karşıyaka
5 = Göztepe
Takım çiftlerini ikili olarak karşılaştırmadan önce, her seferinde, verimizde karşılaştıracağımız takım çifti dışındaki takımları geçici olarak veriden çıkartmak gerekiyor. Bunu Data -> Select Cases ile yapıyoruz.

“If condition is satisfied” seçerek “If…” butonuna basıyoruz.

Boşluğa, değişkenimizin ismini girip aşağıdaki gibi bir ifade yazıyoruz. Büyük küçük harflere ve noktalama işaretlerine dikkat edin.

“Continue”ya basıyoruz.
SPSS, veri setimizde, sadece seçtiğimiz değerlere sahip katılımcıları aktif olarak bırakacak ve diğer değerlere sahip katılımcıları analize sokulmayacak şekilde geçici olarak devre dışı bırakmış olacak.

Şimdi, Analyze -> Nonparametric Tests -> Legacy Dialogs -> Binomial butonlarına basıyoruz.

Açılan pencerede “Test Variable List” kutusuna değişkenimizi koyuyoruz. Test Proportion 0.50 olmalı, çünkü 2 değişkeni karşılaştıracağız ve normalde ikisinin de eşit olmasını bekliyoruz.

Binomial Test tablosuna çift tıklıyoruz.

Açılan pencerede, “Sig.” değerine çift tıklayarak gerçek değerini görüyoruz. Bunu kopyalıyoruz.

Kopyaladığınız bu değeri, demin oluşturduğumuz tabloda, karşılaştırdığımız değişkenlerin yan sütununa yapıştırıyoruz.

Sonra yine “Select Cases” yapıp deminki gibi diğer iki takımı seçiyoruz. Bütün takım çiftleri için bu aşamaları yapıyoruz ve tabloyu dolduruyoruz.


En sonunda aşağıdakine benzer bir p değeri tablomuz olması gerekiyor:

Burada kullandığımız standart istatistiksel anlamlılık p değeri eşiği 0.05 oldu. Fakat burada 10 kere ayrı bir test yaptığımız için eğer 0.05 anlamlılık değerini kullanırsak, Tip I hata yapma yani gerçekte var olmayan bir etkiyi varmış gibi görme şansımız çok yükseliyor. Tip I hata oranını kontrol altında tutmak ve aslında var olmayan etkileri varmış gibi bulmamak için anlamlılık eşik değerine Bonferroni düzeltmesi yaparsak daha sağlıklı olur.
Bonferroni düzeltmesi yapmak çok basit. 10 tane test yaptığımız için 0.05’i 10’a bölüyoruz, yeni istatistiksel anlamlılık eşik p değerimiz 0.005 oluyor. (Tabloda kırmızı renkli yer)
Yeni anlamlılık değerimiz 0.005 olduğuna göre bizim demin SPSS’te bulup tablomuza yazdığımız p değerleri arasından 0.005’ten küçük olan değerler, istatistiksel olarak anlamlıdır diyebiliriz.
Eğer tabloda istatistiksel olarak anlamlı bir p değeri varsa, ilgili değişkenlerin ikisi de beklenen değerden anlamlı bir şekilde farklıdır diyebiliriz. Mesela bizim bu sayfadaki örneğimizde 2 tane p değeri 0.005 anlamlılık seviyesine göre anlamlı çıkmış: Galatasaray – Fenerbahçe (p=0.0008) ve Galatasaray – Göztepe (p=0.002). Bu demek oluyor ki Galatasaray, Fenerbahçe ve Göztepe takımını tutan kişi sayısı, ki kare uygunluk testi sonucunda, beklenen değerden istatistiksel olarak anlamlı bir biçimde farklı çıkmış.
Bunu, aşağıdaki tabloda “Observed N” ve “Expected N” sütunlarını karşılaştırarak göz kararı bakarak da anlayabilirdik. Tabloda da Galatasaray’ı tutan kişi sayısı ortalamadan çok fazla, Fenerbahçe ve Göztepe’yi tutan kişi sayısı ortalamanın çok altında. Fakat istatistiği kullanarak bu sayıların şans eseri olup olmadığından emin olduk.
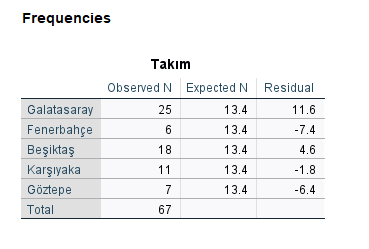
Ki kare uygunluk testi sonrası post hoc analizi bu kadardı. Verideki bütün değer çiftlerini binom analizi ile karşılaştırıp p değeri buluyoruz ve yeni hesapladığımız p eşik değeriyle karşılaştırıyoruz. Yeni eşik değerinden düşük çıkan p değerlerine sebep olan veriler de beklenen değerden farklı demek oluyor. Bu post hoc analizini yaparak, ki kare uygunluk testi sonucu bulduğumuz istatistiksel anlamlılığa hangi verilerin sebep olduğunu öğrenmiş olduk.
Bir yanıt bırakın