
İçindekiler
İki Aşamalı Kümeleme Analizi, SPSS’te yapılabilen 3 temel kümeleme analizinden bir tanesidir. Diğer kümeleme analizlerine göre bazı avantajları ve dezavantajları vardır. Bu yazıda İki Aşamalı Kümeleme Analizi’nin ne olduğunu, SPSS’te nasıl yapılabileceğini, ve sonuç tablo ve grafiklerinin nasıl yorumlanması gerektiğini anlatacağım.
Kümeleme Analizi Nedir?
Kümeleme Analizi, benzer nesneleri veya veri noktalarını özelliklerine veya özelliklerine göre kümeler halinde gruplamak için kullanılan istatistiksel bir tekniktir. Kümeleme analizinin temel amacı, bir veri kümesini, aynı gruptaki nesnelerin diğer gruplardakilere göre birbirine daha fazla benzediği anlamlı gruplara bölmektir.
Kümeleme Analizi süreçleri, gruplandırmalara ilişkin önceden bilgi olmaksızın veya önceden bir beklenti sahibi olarak, veriler içindeki kalıpların veya yapıların tanımlanmasını ve verilerin benzerliklere veya farklılıklara göre kümeler halinde düzenlenmesini içerir.
Mesela, pazar analizinde mevcut müşterileri segmentlere ayırmak için kümeleme analizi kullanılabilir. Eldeki veriye göre müşterilerin cinsiyeti, yaşı, gelir durumu vb. akla gelebilecek her kriteri birlikte kümeleme analizine sokulup müşterilerin bu kriterlerinin benzerliği üzerinden pattern’ler oluşturularak birkaç çeşit kümelere ayrılabilir. Doğru yapılmış bir kümeleme analizi yeni potansiyel müşterilere ulaşmayı daha efektif hale getirmeye yardımcı olur.
İki Aşamalı Kümeleme Analizi Nedir?
İki Aşamalı Kümeleme Analizi (Two-Step Cluster Analysis), bir kümeleme analizi türüdür. İki adımı birleştirir: Önce, kategorik değişkenlere dayalı olarak potansiyel kümeleri belirleyerek veri kümesinin karmaşıklığını azaltmak için bir ön kümeleme aşamasını kullanır. Daha sonra ikinci adımda, önceden kümelenmiş verilere bir kümeleme algoritması uygulayarak kümeleme işlemini tamamlar.
İki Aşamalı Kümeleme Analizi’nin Hiyerarşik Kümeleme Analizi ve K-Means Kümeleme Analizi’ne göre en büyük avantajı, hem kategorik hem de sürekli değişkenleri verimli bir şekilde işleyebilmesidir (diğer ikisinde kategorik veri işlenememektedir). Bu da İki Aşamalı Kümeleme Analizi’ni gerçek dünya uygulamalarında yaygın olarak karşılaşılan çeşitli veri seti türleri için uygun hale getirir. Ayrıca İki Aşamalı Kümeleme Analizi büyük veri setlerini kümelemede diğer iki yöntemden daha isabetli olabilmektedir.
En belirgin dezavantajı ise verilerin kümelenmesi konusunda analizi yapan kişiye (Hiyerarşik veya K-Means Kümeleme Analizi’nin aksine) pek seçim şansı bırakmamasıdır. Bir nevi siyah kutu gibidir, SPSS kendi algoritmasıyla kümelere karar verir ve sadece sonucu gösterir. Bu da, karar verme yeteneğinin analiz yorumlama sürecinin temel bir parçası olan kümeleme analizi gibi bir analiz için ideal değildir. Bir diğer diğer önemli dezavantajıysa, eğer çok veri bulunuyorsa, rastgele dağılımları da bir düzen (pattern) şeklinde algılayıp onları da kümelendirme konusunda bir kriter olarak algılayabilmesidir (buna aşırı uyum denir = overfitting).
Özetle, İki Aşamalı Kümeleme Analizi’nin Hiyerarşik Kümeleme Analizi ve K-Means Kümeleme Analizi’nin bir birleşimi olarak görülebilir. Fakat kullanıcıya daha az kontrol şansı sunduğu için bazen tercih edilmediği de olmaktadır.

SPSS ile İki Aşamalı Kümeleme Analizi Nasıl Yapılır?
Bu örnekte, 152 katılımcıdan oluşan bir grubu, Cinsiyet (erkek-kadın), Ekonomik Durum (Zengin, Orta, Fakir), Depresyon, Stres ve Anksiyete bakımından gruplandırmak için SPSS’te kümeleme analizi yapacağız.
Aşağıdaki adımları takip ederek SPSS’te İki Aşamalı Kümeleme Analizi yapabilirsiniz. Analizi başlatma kısmı nispeten kısadır fakat analizi yorumlama kısmı uzun ve karmaşık olabilir. Başlayalım.
Analyze -> Classify -> Two Step Cluster
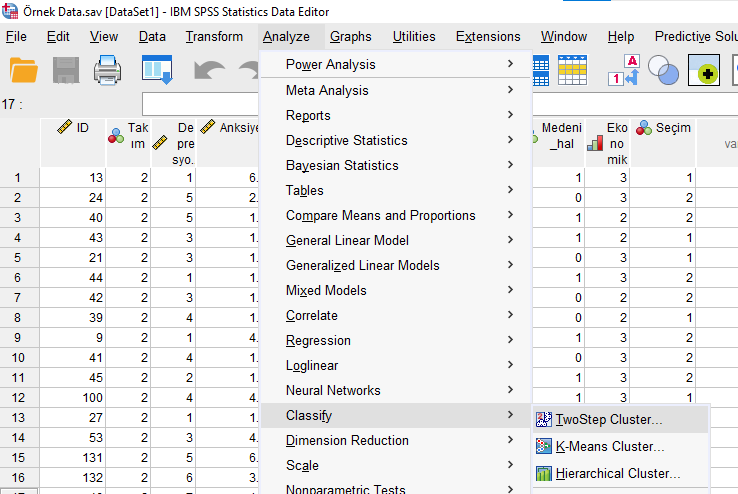
Açılan pencerede kategorik değişkenlerimizi üstteki kutuya, devamlı veri tipindeki değişkenlerimizi alttaki kutuya koyuyoruz.
Devamlı veri tipindeki ölçeklerin hepsinin aynı aralığı ölçmesi şart değildir. Mesela bir ölçek 1-5 arası iken, başka bir ölçek 1-7 arası, diğer 1-100 arası ölçüyor olabilir. SPSS, iki aşamalı kümeleme analizini yaparken bu ölçekleri otomatik olarak standartlaştırıp birbiriyle uygun şekilde karşılaştırılabilecek şekle getirir.
Number Of Clusters bölümünde, verimizin kaç kümeye ayrılması konusunda bir seçim yapabiliyoruz. Determine Automatically dersek SPSS kendi algoritması üzerinden uygun gördüğü şekilde verilerimizi kümeleyecek ve uygun gördüğü sayıda küme oluşturacaktır. Burada oluşturması istenen maksimum küme sayısı 15 olarak görünüyor, bu SPSS’in 15 küme oluşturacağı anlamına gelmez, SPSS nadiren bu kadar fazla küme oluşturur, burada yazan sayı kaç olursa olsun SPSS genellikle birkaç küme oluşturacaktır, bu yüzden burayı 15 olarak bırakabiliriz.
Specify Fixed Number dersek de verimizin kaç gruba ayrılmasını istiyorsak o sayıyı yazarak SPSS’e o sayıda küme oluşturması için talimat veriyoruz. 4 dersek kümeleme analizi sonucunda tam olarak 4 grup oluşturmuş olacaktır.
Determine Automatically seçersek hemen üstünde Distance Measure kısmında Log-Likelihood işaretlemeliyiz, Specify Fixed Number seçersek de orada Euclidean işaretlemeliyiz. Bu şekilde SPSS analizi ideal yolla yapar.
Sağ alt köşedeki Clustering Criterion bölümünde BIC ve AIC model uyumu kriter isimleri görünüyor. Genellikle AIC seçmek daha çok tercih ediliyormuş ama muazzam farklar yaratmıyormuş, ben bu örnekte varsayılan olarak seçili gelen BIC’i kullanacağım.
“Output” butonuna basarak, açılacak yeni pencerede “Pivot Tables” seçeneğini işaretliyoruz. Bu, SPSS’in bize vereceği çıktıda kümelere ait frekans tabloları oluşturmasını sağlar.
Ayrıca, “Create cluster membership variable” seçeneğini de işaretleyelim. Bunu işaretlemek, analiz yapıldıktan sonra SPSS veri setimizde Data View sayfasında yeni bir sütun açarak hangi katılımcının hangi kümeye ait olduğunu teker teker görebilmemizi sağlar.
Aynı zamanda, eğer bir değişkeni kümeleme analizinde küme oluşturmak için kriter olarak kullanmak istemiyorsak, fakat analiz sonucunda kümeler oluşturulduktan sonra o değişkenin her kümedeki ortalama skorunu görmek istiyorsak, o değişkeni Variables kutusundan Evaluation Fields kutusuna atabiliriz. Mesela bu örnekte Mutluluk kümeleme analizinde kümelemek için bir kriter olmayacak ama analiz yapıldıktan sonra oluşan kümelerin her birinin ayrı ayrı Mutluluk skorunu tablo üzerinde görebileceğiz. Buraya kategorik veri de atabiliriz ordinal de sürekli veri de.

Continue ve OK’a basarak analizi başlatıyoruz.

İki Aşamalı Kümeleme Analizi SPSS Yorumlama
Analiz sonucu SPSS’in verdiği çıktı önce çok kısa görünecektir. Fakat derinlemesine incelendiğinde çok fazla bilgi içerdiğini göreceğiz. Başlayalım.
Eğer küme sayısını SPSS’in belirlemesi talimatını verdiysek (biz belirlemediysek), SPSS en başta bize bir Auto-Clustering tablosu gösterir. Bu tablodaki Schwarz’s Bayesian Criterion (BIC) değeri, farklı küme sayıları için modelin uygunluğunu değerlendirir. BIC değerlerindeki düşüş, modelin daha fazla kümeye sahipken verileri daha iyi temsil ettiğine işaret eder. Ancak, bir noktadan sonra, BIC değerlerindeki artış, ek kümelerin modeli daha iyi temsil etmediğini gösterir. Bu nedenle, en düşük BIC değerine sahip model genellikle en uygun model olarak kabul edilir.

“Cluster Distribution” başlıklı tabloda, SPSS bize her kümede kaçar eleman bulunduğunu göstermektedir. Hiçbir kümeye ait olmayan elemanlar varsa onlar Excluded Cases satırında görünecektir.

“Centroids” başlıklı tabloda, her kümenin, sürekli veri tipindeki değişkenler bakımından, ortalama ve standart sapma skorlarını görebilmekteyiz.

“Frequencies” başlıklı bölümde ise, her kategorik değişken için, o değişkenin hangi kategorisinde hangi kümeden kaçar elemanın bulunduğunu gösteren birer tablo bulunur.

SPSS’in verdiği geriye kalan çıktı aşağıdaki gibidir. “Model Summary” tablosunda, iki aşamalı kümeleme analizine 5 değişken soktuğumuzu ve SPSS’in bunun sonucunda 5 küme oluşturduğunu görüyoruz (farklı sayıda küme de oluşturabilirdi ama bu veri seti için 5 kümeyi uygun görmüş).
Altındaki “Cluster Quality” görseli, kümeleme analizi sonucunda gruplar oluşturma işleminin ne kadar düzgün sonuç verdiğini göstermektedir. Burada mavi çubuk, Poor ile Fair arasında duruyor. Fena değil ama daha iyi olabilirdi. Yeşil alan Good’u temsil ediyor, eğer mavi çubuk Fair ile Good arasındaki yeşil alana kadar uzanırsa o zaman model daha iyi demek olmuş olurdu.
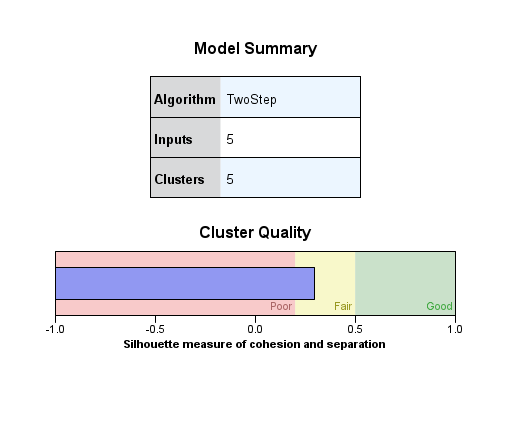
Kümeleme analizi sonuçlarını asıl inceleyeceğimiz nokta buradan sonrası. SPSS’te bu tablo ve grafiğin olduğu alana çift tıklıyoruz ve yeni bir pencerenin içinde yeni bir dünya açılıyor.
Çift tıklanınca açılacak olan “Model Viewer” penceresinde, bir dünya analiz sonucuna bakmak mümkün. Şimdi bunların önemli olanlarını göstereceğim.
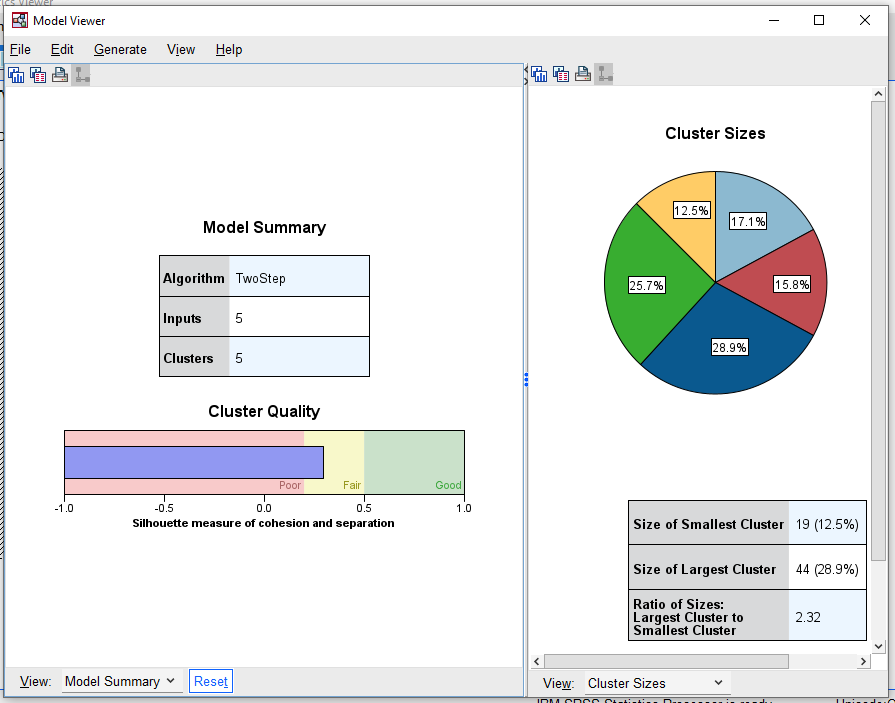
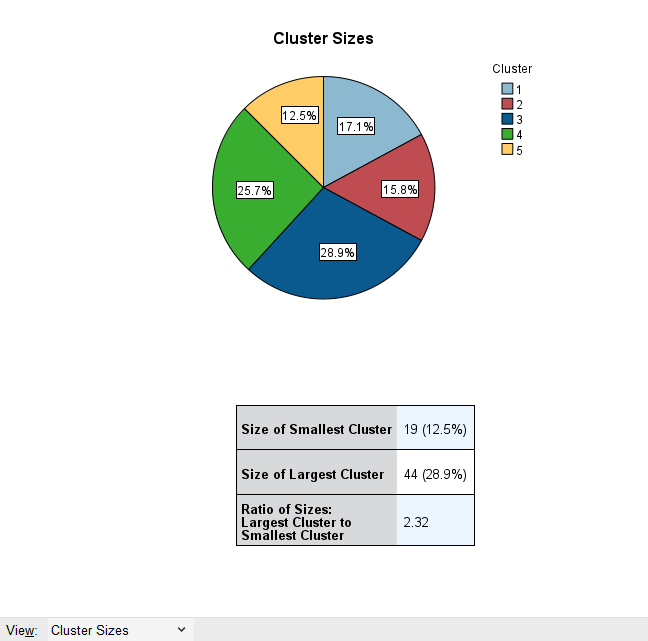
Sağdaki pencerenin en altındaki View menüsünde Cluster Sizes seçili olduğunda, pencerenin içinde bir pasta grafiği görünüyor. Bu tabloda, küme numaraları ve kaçar kişiden oluştuğu görülüyor. Ratio Of Sizes bölümünde 2.32 yazması demek oluyor ki “en büyük küme en küçük kümenin 2.32 katı büyüklükteymiş”. Buradaki oran 2 civarında olursa iyi, bu oran büyüdükçe, kümelerin orantısız büyüklükte dağıldığını gösteriyor, kümelerin büyüklüğünün orantısız olması da pek istenen bir durum değildir.
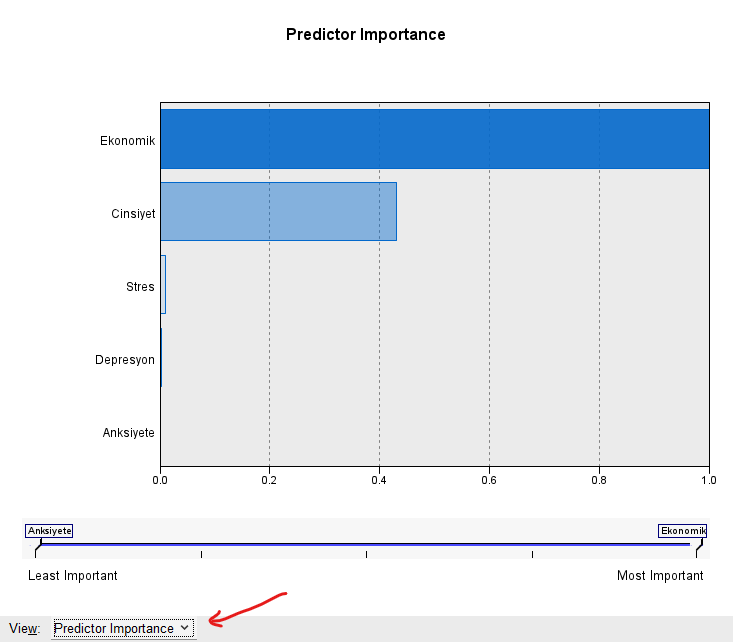
Bu pencerenin en altındaki View menüsünde bu sefer Predictor Importance’ı seçerseniz ekran aşağıdaki gibi görünmeye başlayacak.
Burada, kümeleme analizine soktuğumuz her değişkenin, kümeleme işlemine ne kadar fazla katkısı olduğunu görebiliyoruz.
Eğer kümeleme analizine sürekli veriye ek olarak kategorik veri de soktuysanız, hele ki bu kategorik veriler 2 ya da 3 kategoriye sahipse (erkek-kadın cinsiyet kategorileri gibi), o zaman bu kategorik verilerin modeldeki önemi sürekli verilerin öneminden çok daha yüksek görünür. Bu örnekte 3 sürekli veri (Stres, Depresyon, Anksiyete) ve 2 kategorik veri (Ekonomik Durum, Cinsiyet) koymuştum. Şaşırtıcı olmayan bir şekilde, kategorik verilerin önemi çok daha yüksek göründü.
Bu örnekte en yüksek öneme sahip olan değişken açık ara Ekonomik Durum’muş. Yani SPSS, katılımcıları daha çok ekonomik durumlarına göre kümelemiş. Onu da Cinsiyet takip etmekte. Diğer 3 değişkenin kümeleme analizinde katılımcıları gruplamaya neredeyse hiç etki etmediğini söyleyebiliriz.
Eğer kümeleme analizine soktuğunuz kategorik veriler birçok kategoriye sahipse ve bunlarla birlikte birçok sürekli veri tipinde ölçeği de kümeleme analizine sokarsanız, Predictor Importance başlıklı değişkenlerin önem miktarlarını gösteren grafikte farklı değişkenlerin önemleri bu örnektekinden daha dengeli görünecektir.
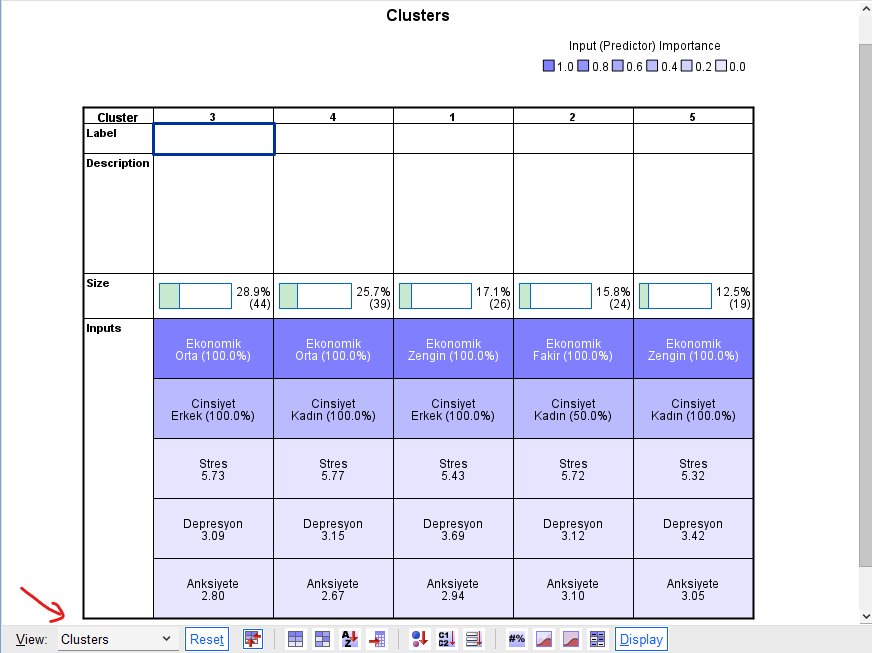
Diğer pencerede bulunan View menüsünde Clusters’ı işaretlersek, aşağıdaki gibi bir tablo pencerede görünmeye başlayacak.
Bu tabloda en üst satırda yazan numaralar küme numarası. Neden 1’den 5’e kadar sırayla gitmiyor çünkü kümedeki kişi sayısı en büyük küme en solda, en küçük küme en sağda. Size satırında her kümede kaçar kişi olduğunu görebilirsiniz.
Inputs bölümünde, kümeleme analizine soktuğumuz her değişken için SPSS’in katılımcıları ne şekilde gruplamış olduğunu görüyoruz. Tablonun sağ üst köşesinde de görebileceğimiz üzere, en koyu mavi renk bir değişkenin en yüksek öneme sahip olduğunu belirtirken, renk açıklaşıp beyaza yaklaştıkça bir değişkenin katılımcıları kümelere ayırmada o kadar düşük öneme sahip olduğu anlamına gelmektedir.
Bu tablodaki Input bölümüne bakınca görüyoruz ki, deminki Predictor Importance grafiğini doğrulayacak şekilde, en yüksek öneme sahip değişken Ekonomik Durum, sonra Cinsiyet orta öneme sahip, diğer 3 değişken ise çok az öneme sahipler.
3 numaralı kümedeki herkes ekonomik durum bakımından Orta seviyedeymiş. Ekonomik Orta %100 yazması bu anlama geliyor. Aynı zamanda 3 no’lu kümedeki herkes Erkek’miş, bir alttaki Cinsiyet kutusundan bunu anlıyoruz. Bu kümedeki kişilerin ortalama Stres seviyesi 5.73, Depresyon seviyesi 3.09, Anksiyete seviyesi 2. 80’miş. Diğer kümeler için de bu değerlere bakabilirsiniz.
Yani bu örneğimizde 3 no’lu kümedeki herkes Orta gelirli Erkek, 4 no’lu kümede herkes Orta gelirli Kadın, 1 no’lu kümede herkes Zengin Erkek, 5 no’lu kümede de herkes Zengin Kadın’mış. 2 no’lu kümede de herkes Fakirmiş, cinsiyetten bağımsız olarak. Bu, pratikte çok faydalı bir kümeleme analizi olmadı çünkü kümeleme analizine 5 değişken sokmuş olmamıza rağmen, SPSS sadece Cinsiyet ve Ekonomik Durum üzerinden katılımcıları kümeledi.
Bu kümeleme analizi örneğimizdeki verimizde yalnızca 2 cinsiyet ve 3 ekonomik durum çeşidi olduğu için, SPSS kümeleme analizinde grupları belirlerken sadece cinsiyeti ve ekonomik durumu kullanmış oldu. Daha fazla kategoriden oluşan kategorik veriye sahip ya da hiç kategorik veriye sahip olmayan veriler ile başka bir kümeleme analizi yaparsak kategoriler bu kadar keskin bir şekilde ayrılmayacaktır.
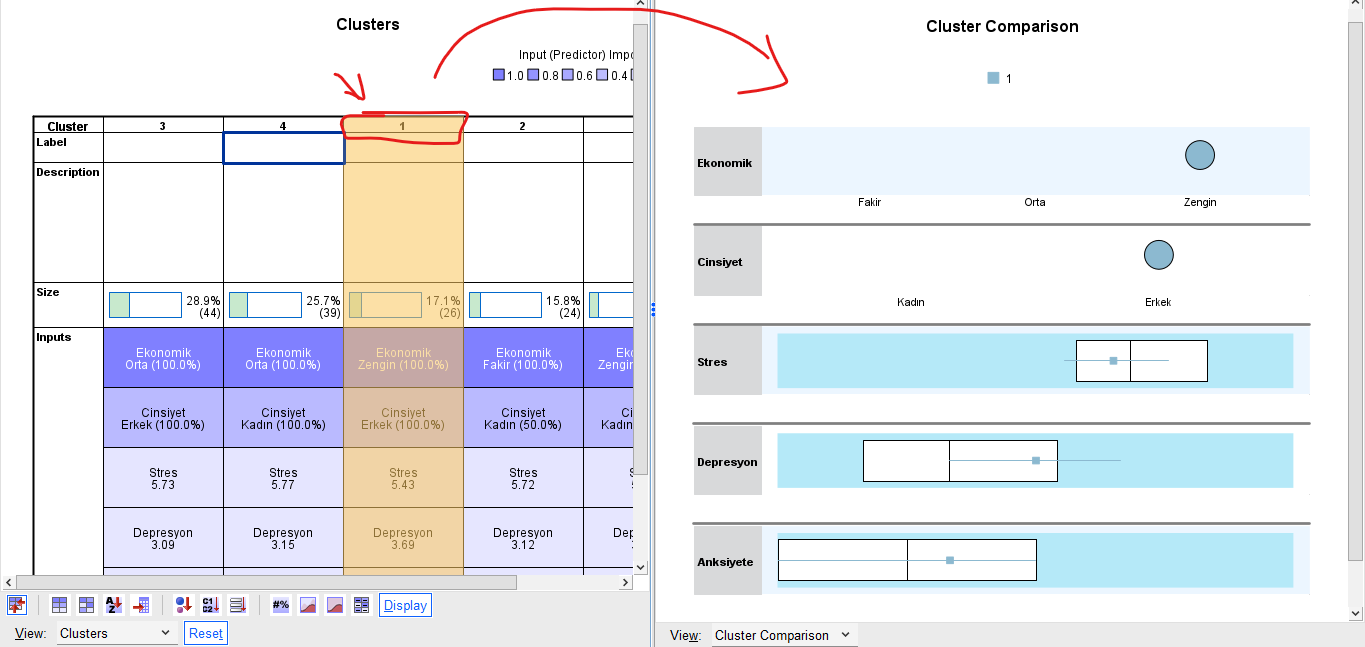
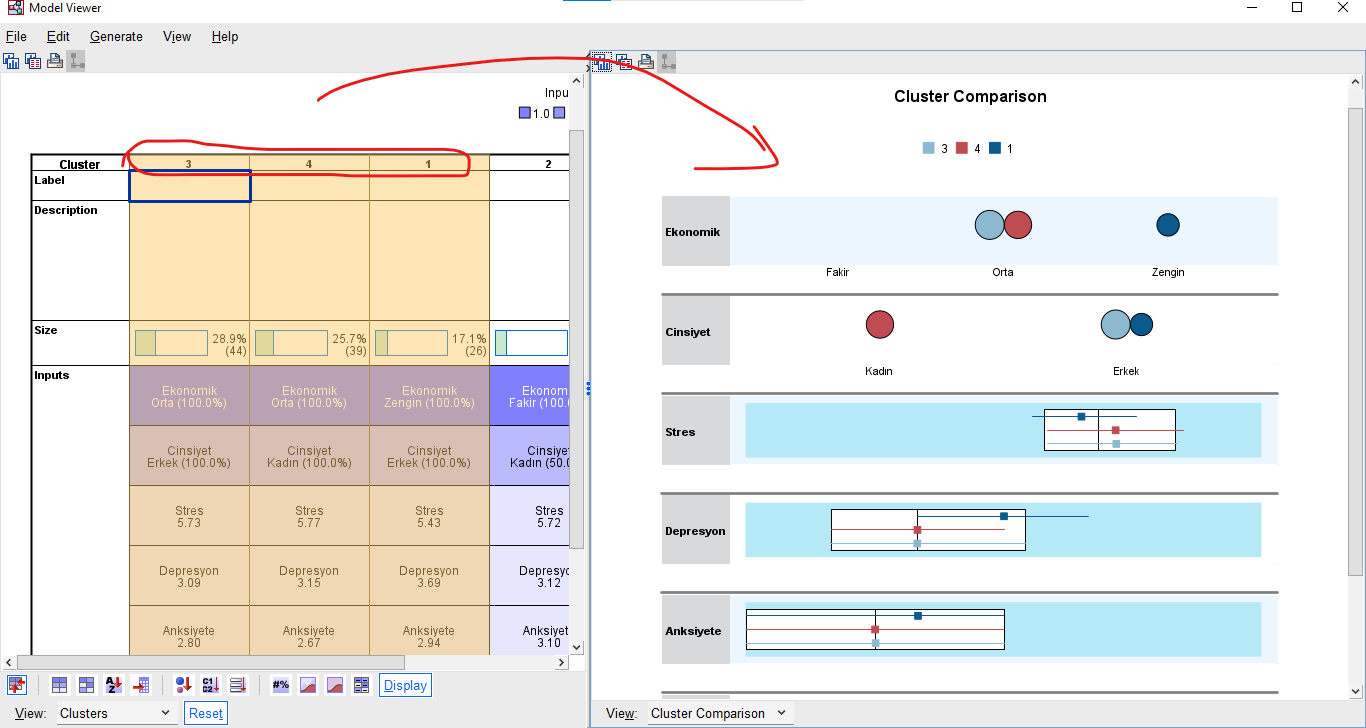
Soldaki Clusters penceresinde, kırmızı kutuyla işaretlediğim Cluster yani küme numarasına tıklarsanız, sağdaki pencerede, aşağıdaki resimde göründüğü gibi, bir Cluster Comparison yani küme karşılaştırma ve analizi tablosu açılacaktır. Solda 1 no’lu kümeye tıkladık ve sağda Cluster Comparison tablosu açıldı, bu tabloyu inceleyelim.
Kategorik verilere bakalım önce.
Ekonomik Durum bakımından, bu kümedeki bütün katılımcılar Zengin’miş. Cinsiyet bakımından hepsi Erkek’miş. Eğer mesela hepsi Erkek olmasaydı o yuvarlak daha küçük görünecekti. Hangi Cinsiyet o grupta en fazla sayıda varsa sadece o Cinsiyete ait yuvarlak olacaktı.
Şimdi de sürekli veri olan değişkenlerimize bakalım.
Stres bölümündeki beyaz kutu, bir boxplot yani kutu grafiğidir. Bu grafikte, katılımcıların en düşük Stres puanına sahip olan %25’lik kısmı ve en yüksek Stres puanına sahip olan %25’lik kısmı çıkartıldıktan sonra geriye kalan katılımcıların Stres puanlarının aralığı, beyaz kutu ile gösterilmektedir. Dikey siyah çizgi medyan değerini yani orta sıradaki (ortalama değil) katılımcının Stres puanının nereye denk geldiğini göstermektedir. Beyaz kutunun anlamı buydu.
Şimdi mavi çizginin anlamına bakalım. Stres bölümünde, mavi çizgi, beyaz kutunun birazcık dışında soldan başlayıp, beyaz kutunun içinde ortanın sağında bitiyor. Bu demek oluyor ki “1 no’lu kümedeki katılımcıların birçoğu Stres bakımından genelde ortalamanın altında, bir kısmı da ortalamanın birazcık üstünde”. Mavi çizginin üzerindeki küçük kare de, 1 no’lu kümedekilerin medyan Stres değerini veriyor.
Fare ile Cluster Comparison tablosunda görünen grafiklerin üzerinde biraz gezinirsek bu bilgilerin daha detaylandırılmış hallerini ekranda görebiliriz.
Eğer birden fazla kümeyi aynı anda seçersek (mouse’u basılı tutarak SHIFT’e veya CTRL’ye basarak) sağdaki penceredeki Cluster Comparison başlığı altında, bu seçtiğimiz birden fazla kümenin her değişken bakımından skorlarının karşılaştırmasını görebiliriz. Her renk farklı bir kümeyi temsil etmektedir.
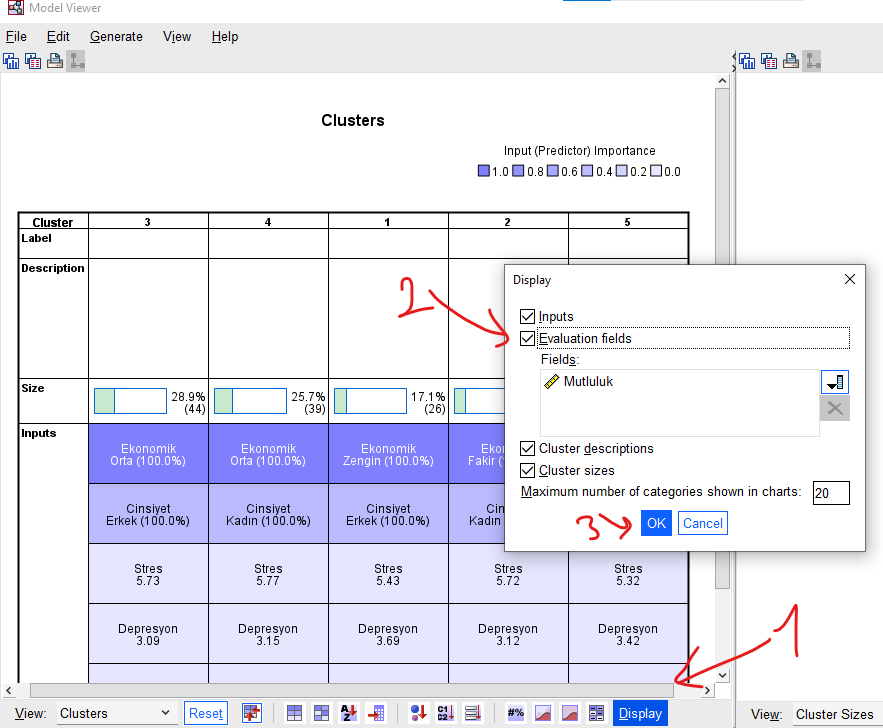
Şimdi de Soldaki Clusters penceresinin altında bulunan “Display” butonuna basalım. Açılacak pencerede “Evaluation Fields”ı işaretleyelim. İşaretledikten sonra kutunun içinde, analizi yapmaya başlarken kontrol amaçlı seçtiğimiz “Mutluluk” değişkeni görünmeye başlayacaktır. Sonra OK’a basalım.
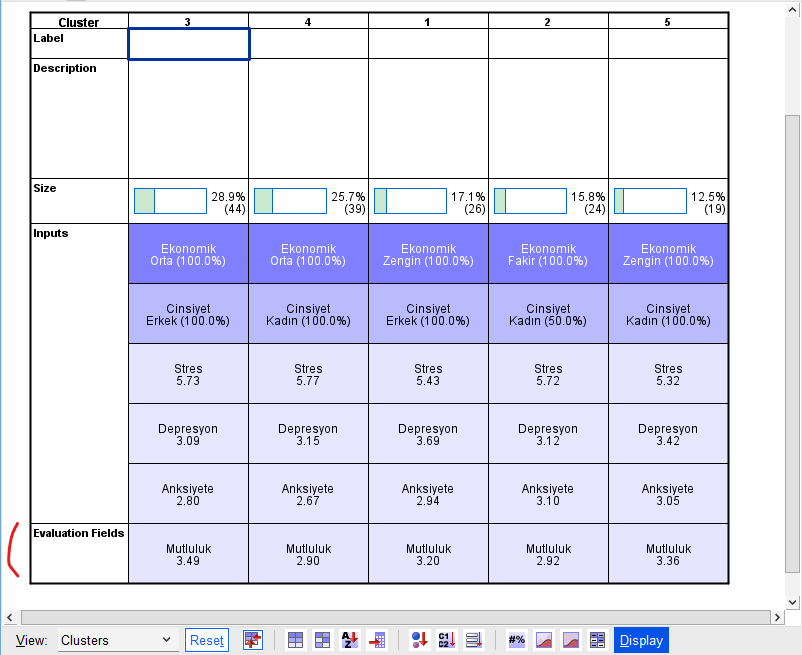
Cluster penceresindeki tablomuzun en altına, Evaluation Fields isimli bir satır gelecektir. Burada, her küme için, o kümedeki katılımcıların ortalama Mutluluk skorlarını görebilmekteyiz. Mesela 3 no’lu kümedekilerin Mutluluk ortalaması 3.49 iken, 4 no’lu kümedekilerin mutluluk ortalaması 2.90’mış. Mutluluk, katılımcıları kümelere ayırma işleminde bir kriter olarak kullanılmadı, sadece kümeler oluştuktan sonra kümeler arasındaki Mutluluk farklarını görmüş oluyoruz bu şekilde.
Bu örnekteki Mutluluk değişkeni sürekli veri tipinde olduğu için kutunun içinde o kümenin ortalama Mutluluk skoru görünüyor. Eğer kategorik veri olsaydı, her küme için o kümede en çok bulunan kategori ve yüzdesi görünecekti.
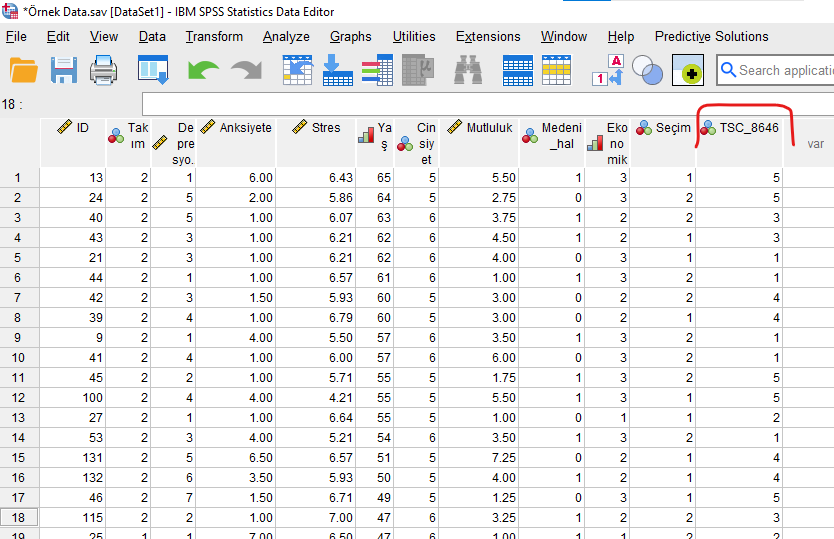
Bu sonuç tablolarını kapatıp SPSS veri setimizin Data View bölümüne gelirsek, en sağ sütunda yeni bir değişken oluşmuş olduğunu göreceğiz. Bu TSC değişkeni, her katılımcının hangi kümeye ait olduğunu gösteriyor. Mesela 1 numaralı katılımcı, 5 numaralı kümeye aitmiş. 8 numaralı katılımcı da 4 numaralı kümeye aitmiş.
Bu kümeleri, ANOVA gibi analizler yapmak için kullanabiliriz artık. “Hangi kümedeki katılımcıların X ya da Y değişkenindeki skoru daha yüksek?”, “5 no’lu kümedeki katılımcıların kendi arasında Anksiyete ve Stres skorları korelasyon gösteriyor mu?”, “3 ve 5 numaralı kümeler arasında Evli veya Bekar olma oranları anlamlı farklılık gösteriyor mu?” gibi soruların cevaplarını bulmak için bundan sonra bu sütundaki küme bilgilerini bağımsız değişken olarak kullanarak yeni ANOVA, regresyon, ki kare ve benzeri analizler yapabiliriz.

Kümeleme Analizi Sonrası En Uygun Küme Sayısını Bulma
SPSS bu örnekte bize yaptığı İki Aşamalı Kümeleme Analizi sonrası 5 tane küme oluşturdu. Acaba 5 küme gerçekten en iyisi mi diye kontrol etmek istersek bunu yapabiliriz.
Analyze -> Classify -> Two Step Cluster butonlarına basıp kümeleme analizi penceremizi yeniden açıyoruz. “Output” butonuna basıp, açılacak yeni pencerede “Pivot tables” işaretliyoruz. Sonra Continue ve OK’a basıp analizi tekrar başlatıyoruz.
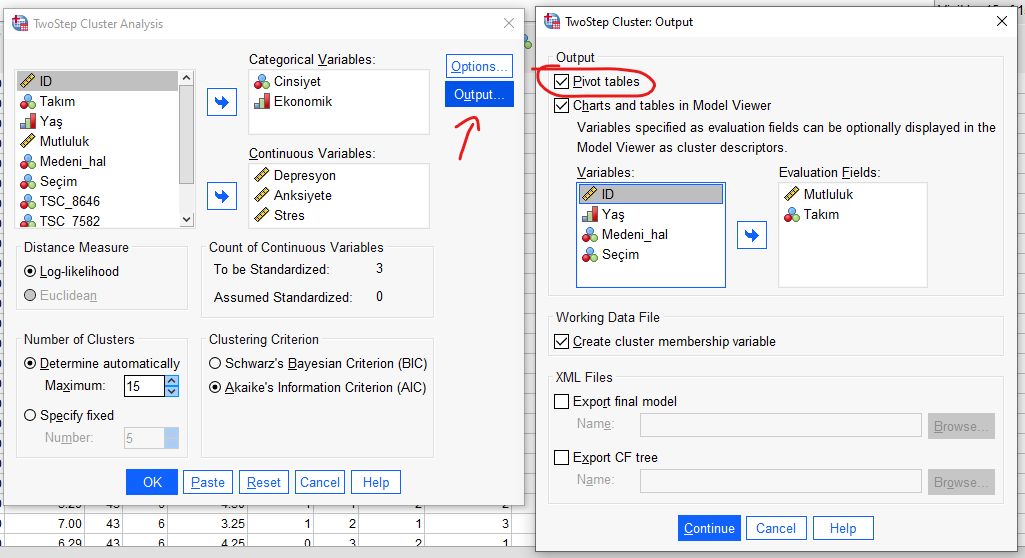
“Create Pivot Table”ı seçtiğimiz için, SPSS bize birtakım tablolar da sunacaktır. Karşımıza çıkan tablolardan Auto-Clustering başlıklı tabloya çift tıklıyoruz. Burada, BIC ya da AIC yazan sütuna (hangisini seçmiş olduğunuz pek fark etmez) gelip bütün küme numaralarını yukarıdan aşağı mouse ve shift tuşuna basarak seçiyoruz. Sonra üzerine sağ tıklayıp Create Graph -> Line butonlarına basıyoruz.
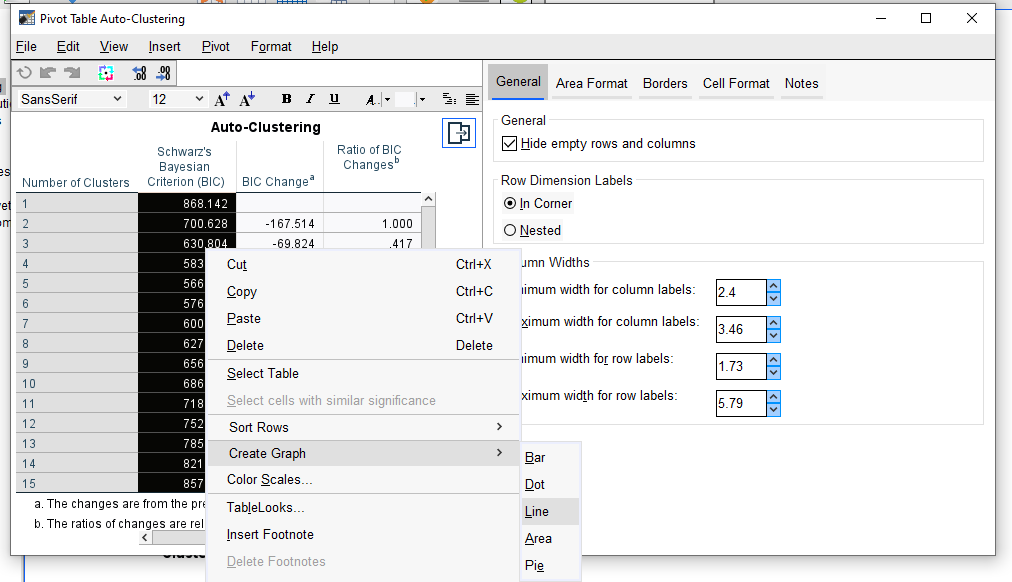
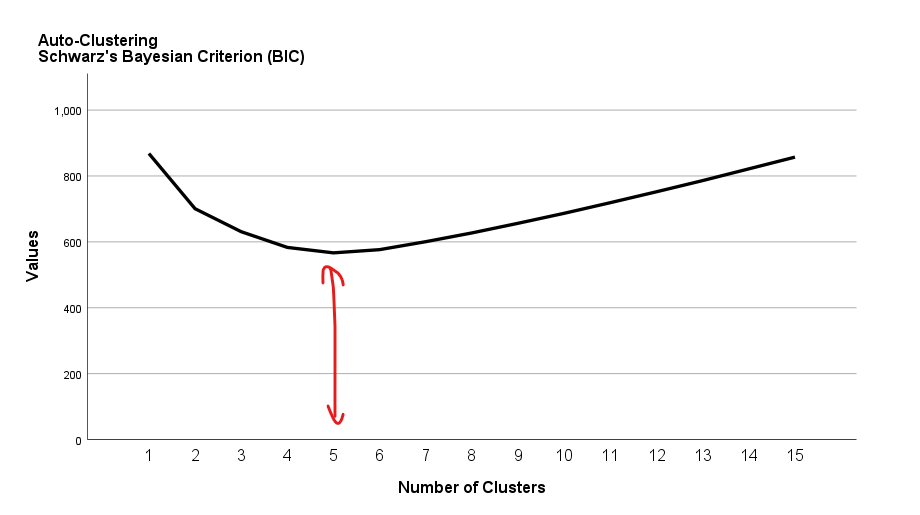
Bir çizgi grafiği çıkacak. Burada, SPSS’in oluşturmuş olduğu çeşitli farklı kümeleme modellerinin uyum oranları görünmektedir. Bu kriter, SPSS tarafından model seçimi için kullanılmaktadır. Buradaki Value sütununa göre değer ne kadar küçükse modelin uyum miktarı o kadar iyidir.
Aşağıdaki tabloya bakarsak, sadece 1 kümeden oluşan kümeleme analizi modelinin yeterince uyumlu olmadığını görebiliriz. Küme sayısı 2’ye çıktığında modelin uyum oranı iyileşmiş. Küme sayısı 3, 4 ve 5 oldukça uyum oranı giderek artmış. Küme sayısı 5’ten fazlalaştıkça, modelin uyum oranı azalmaya başlamış. Yani SPSS’e göre en ideal uyumlu küme sayısı 5 kümeden oluşan kümeleme analizi modelidir.
Uyum oranı en yüksek olan kümeleme analizi modeli 5 kümenin yer aldığı modeldir, fakat 5 kümeden oluşan bir veri setini yorumlamak biraz karmaşık olabilir, daha az küme var olmasını tercih edebiliriz. Aşağıdaki çizgi grafiğine göre küme sayısı 1’den 2’ye çıktığında model çok iyileşmiş, sonra 2’den 3’e ve 4’e çıktığında da model gayet iyi miktarda iyileşmiş, sonra 4’ten 5 kümeye çıktığında modelin iyileşme miktarı yavaşlamış. Bu durumu, analiz ettiğimiz verinin ne üzerine olduğuna ve kaç kümeye ayırmak istediğimize (belki sadece 3 kümeye ayırmak için herhangi bir sebebimiz olabilir) bağlı olarak, “4 kümeye ayırmak belki daha iyi olurmuş” şeklinde yorumlayabiliriz. Böyle yorumlarsak, bundan sonra SPSS’e tam olarak 4 küme oluşturması talimatını verdiğimiz yeni bir İki Aşamalı Kümeleme Analizi gerçekleştirebiliriz.
Kümeleme Analizi Sonrası Nokta Grafiği Oluşturma
SPSS’in Data View bölümünde en sağda yeni sütun oluştuktan sonra, kümeleme analizi sonucu bulduğumuz kümeleri kullanarak güzel estetik bir nokta grafiği oluşturma işlemini de artık yapabileceğiz.
Graphs -> Chart Builder butonlarına basalım.
Sol aşağıda Scatter/Dot seçip sonra sağındaki ilk baştaki kutuyu üst ortadaki boşluğa taşıyoruz.
Sonra yeni oluşmuş olan küme sütunu değişkenini Variables sütunundan alıp bu grafik taslağının sağ üst kısmındaki Set Color bölümünün içine taşıyoruz. X ve Y eksenlerine de Variables kısmında istediğimiz değişkenleri taşıyıp koyuyoruz. Sonra OK’a basıyoruz.
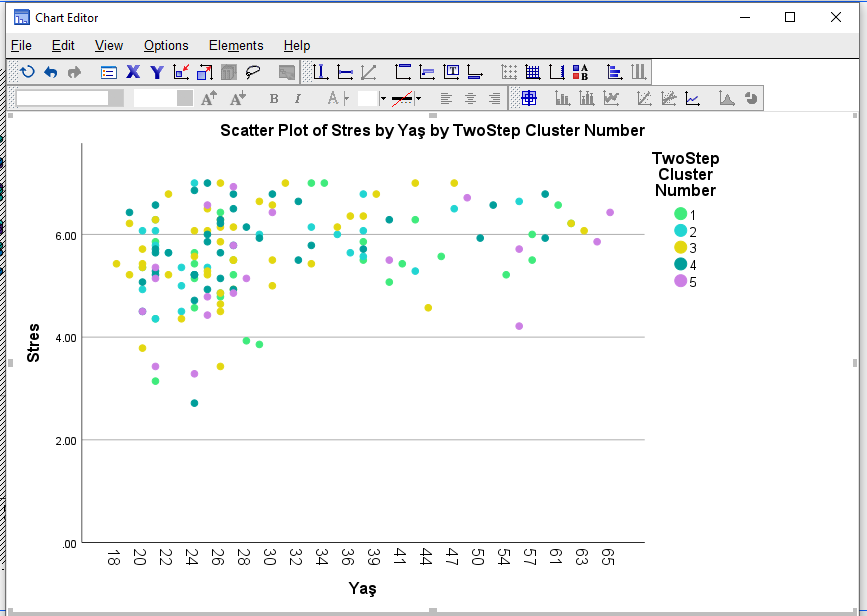
SPSS bize bu şekilde bir nokta grafiği gösterecek. Burada yatay X eksenine Yaş’ı, dikey Y eksenine de Stres seviyesi değişkenini koydum. Grafikteki her renk, demin yapmış olduğumuz kümeleme analizine göre başka bir kümeye ait katılımcıları gösteriyor. Grafiğe çift tıklayarak açabileceğimiz Editor penceresinde, kümeleri temsil eden noktaların renklerini değiştirebilir, istemediğimiz kümelerin grafikte görünmesini engelleyebiliriz.
Eğer bu örnekte kümeleri daha çok temsil eden bir devamlı değişkenimiz olsaydı, kümelere ait noktalar bu grafikte yan yana aynı kümeyi temsil eden aynı renkli noktalar birbirine yakın olarak kümelenmiş halde görünecekti.
Bir yanıt bırakın