
İçindekiler
Diskriminant analizi, birçok farklı ölçekten edinilen verilerin sonucunda bir kişinin kategorik bir ölçek üzerinde hangi gruba ait olmasının en yüksek ihtimal olduğunu tahmin etmeye yarayan bir istatistiksel analiz yöntemidir. Özellikle sınıflandırma ve tahmin problemlerinde yaygın olarak kullanılan bir tekniktir. Temel amaç, değişkenler arasındaki ilişkiyi anlamak ve bu ilişkileri kullanarak yeni gözlemleri gruplara atamaktır. Bu yazıda, Diskriminant Analizi’nin ne olduğunu, benzer bir analiz türü olan lojistik regresyon ile olan farklarını ve SPSS ile nasıl yapıldığını göstereceğim.
Diskriminant Analizi Nedir?
Diskriminant analizi, aynı lojistik regresyon analizi gibi, birden çok bağımlı değişkenin değerlerine göre, bir katılımcının hangi gruba ait olması gerektiğini öngörmeye yarayan bir istatistiksel analiz türüdür.
Diskriminant analizinde bağımlı değişken kategorik veridir, bağımsız değişkenler ise sürekli veri olmalıdır. Diskriminant analizi, bağımsız değişkenlerin değerlerine dayanarak bir kişinin grup üyeliğini tahmin edebilen bir diskriminant fonksiyonu veya fonksiyonları yaratıp grup üyeliğini bulmaya yarar.
Doğrusal diskriminant analizi (LDA) ve kuadratik diskriminant analizi (QDA) dahil olmak üzere farklı diskriminant analizi teknikleri vardır. LDA, tahmin edici değişkenlerin normal dağıldığını ve kovaryans matrisinin tüm gruplar için aynı olduğunu varsayarken, QDA eşit kovaryans matrisleri varsayımını gevşeterek modellemede daha fazla esneklik sağlar.
Diskriminant analizinin çeşitli uygulamaları vardır. Psikolojide, psikolojik değerlendirmelere verilen yanıtlara dayalı olarak bireyleri farklı kişilik tiplerine sınıflandırmak için kullanılabilir. Biyolojide, genetik özelliklere dayalı olarak türler arasında ayrım yapılmasına yardımcı olabilir. Pazarlama araştırmalarında, müşteri segmentleri arasında ayrım yapan demografik veya davranışsal özellikleri belirleyebilir.
Diskriminant Analizi’nde 2 veya fazla sayıda sürekli veri tipinde bağımsız değişken ve 1 tane kategorik bağımlı değişken bulunmaktadır. Bu bağımlı değişken 2 veya daha fazla kategoriye sahip olabilir, fark etmez.
Diskriminant Analizi vs. Lojistik Regresyon Farkı
Hem Diskriminant Analizi hem de Lojistik Regresyon bir dizi bağımsız değişkene dayalı olarak bir kişinin hangi gruba ait olması gerektiğini öngörmektedir. Peki o zaman neden iki tane farklı analiz türü var? Bunun sebepleri olan diskriminant analizi ve lojistik regresyon analizi farklarını aşağıda madde madde sıraladım.
- Diskriminant Analizi, Lojistik Regresyon’un yaptığına ek olarak, bir kişinin hangi kategoriye ait olduğunu bulma konusunda hangi bağımsız değişkenlerin diğerlerinden daha çok öneme sahip olduğunu da gösterir.
- Lojistik Regresyon’da bağımsız değişkenler her türlü veri tipinde olabilmekteyken, Diskriminant Analizi’nde bağımsız değişkenler sadece sürekli veri tipinde olabilir.
- Lojistik Regresyon varsayıma ihtiyaç duymaz, fakat Diskriminant Analizi için verilerin normal dağılması, veride uç değerler bulunmaması ve bağımsız değişkenlerin kovaryans matrislerinin homojenliği önemlidir.
- Lojistik Regresyon, küçük örneklemlerin analizinde Diskriminant Analizi’nden daha başarılıdır.
Yani eğer bağımsız değişkenler sürekli veri tipindeyse, veri seti yeterince büyükse ve varsayımlar sağlanıyorsa, Diskriminant Analizi yapmak, bize Lojistik Regresyon’dan daha çok bilgi sunar. Eğer bunlar geçerli değilse o zaman Diskriminant Analizi yerine Lojistik Regresyon analizi yapmak gerekir.

SPSS ile Diskriminant Analizi Nasıl Yapılır?
SPSS ile Diskriminant Analizi aşağıdaki adımlar takip edilerek yapılabilir.
Bu sayfada yapacağım Diskriminant Analizi örneğinde, 4 ölçeğin (ölçek adları SDO, EDO, MY, EID) sonuçlarının hangilerinin bir kişinin hangi Cinsiyet’te olduğunu ne ölçüde belirlediğini ve hangi ölçeklerin daha belirleyici olduğunu inceleyeceğiz. Cinsiyet 3 kategoriye ayrılıyor: Erkek, Kadın, Diğer.
Analyze -> Classify -> Discriminant
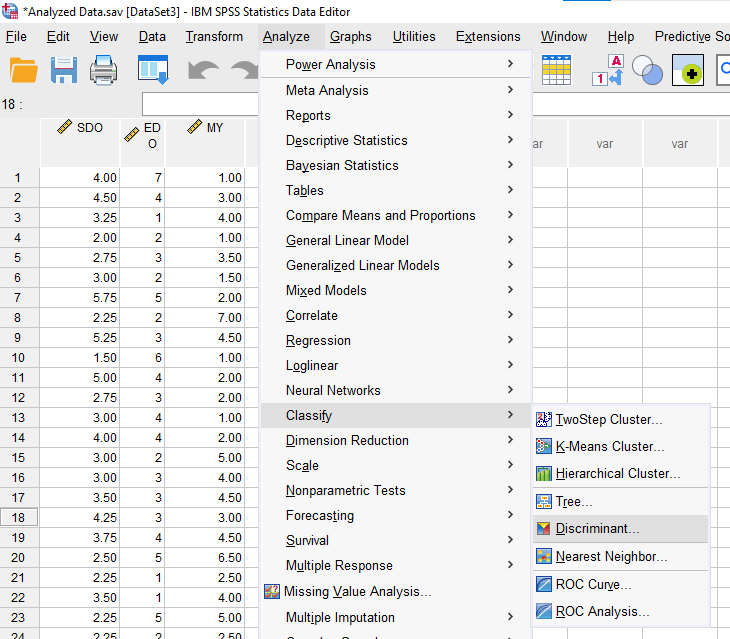
Bağımlı değişkenimizi Grouping Variable kutusuna, bağımsız değişkenlerimizi Independents kutusuna koyuyoruz.
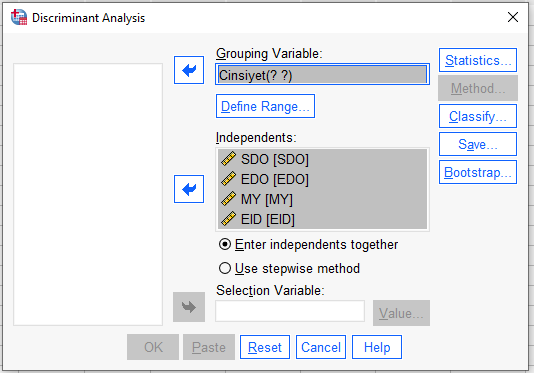
Grouping Variable’a tıklayıp altındaki “Define Range” butonuna tıklıyoruz. Burada, bağımlı değişkenimizin kategori değerleri kaçtan kaça kadar değişiyor bunu belirtmemiz gerekiyor. Bu veri setinde, cinsiyetler Kadın = 5 ve Erkek = 6 ve Diğer = 7 olarak kodlandı. Bu yüzden Minimum 5 ve Maximum 7 yazıyorum. Sizin veri setinizde farklı rakam olacaktır.
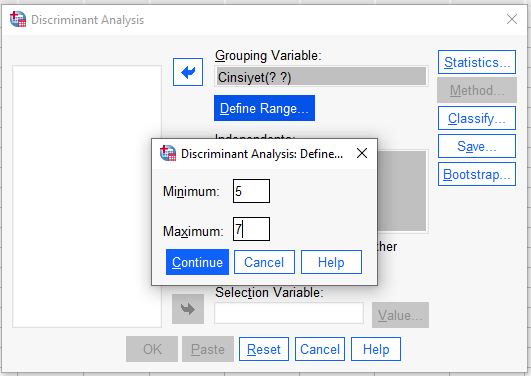
“Statistics” butonuna basıp aşağıdaki kutuları işaretliyoruz.
“Classify” butonuna basıp aşağıdaki seçenekleri işaretliyoruz.
“Save” butonuna basıp üç seçeneği de işaretliyoruz.
Artık bütün ayarlamaları yaptık. OK butonuna basarsak SPSS analizi bizim için başlatacaktır.

Diskriminant Analizi SPSS Tablo Yorumlama
Diskriminant Analizi sonucunda SPSS bize bir sürü tablo sunacaktır. Bu tabloların hangileri önemli ve nerelere bakmak gerekiyor? Aşağıda hepsini anlatıyorum.
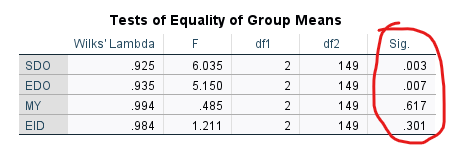
Tests of Equality of Group Means tablosu, MANOVA analizi sonucu baktığımız farklı ANOVA’ların tablosunun aynısıdır. Burada, Sig. p anlamlılık değeri 0.05’ten düşük çıkan bağımsız değişkenler, bir kişinin hangi Cinsiyet kategorisine ait olduğunu tahmin edebilme konusunda faydalı olmuş demektir. Sig. p değeri 0.05’ten büyük olan değişkenler ise modele faydası dokunmayan bağımsız değişkenler olmuştur.
Bu örnekte, SDO ve EDO değişkenleri Cinsiyet’i belirlemeye yardımcı olmuşken, MY ve EID isimli değişkenlerin diskriminant analizine anlamlı bir katkısı olmamıştır.
Aslında anlamlı katkısı olmayan değişkenleri modelden çıkartıp tekrar diskriminant analizi yapmak daha faydalıdır çünkü daha isabetli bir tahmin seti oluşturacaktır. Fakat bu örnekte göstermek adına şimdiki gibi devam edeceğim.
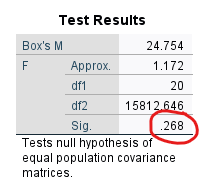
Log Determinants tablosundaki Log Determinant değerleri, her değişken için birbirine yakın olmalıdır. Bu örnekte çok yakın değil, bu ideal bir durum değil. Ama Test Results tablosundaki Box’s M Sig. değeri 0.268 çıkmış, bu değer Box’s M Testi eşik p değeri olan 0.001’den büyük olduğu için bir sorun olmadığı sonucuna varabiliriz.

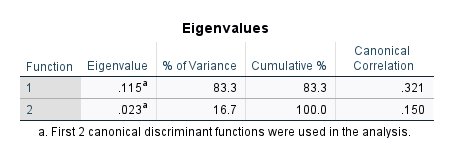
Eigenvalues tablosunda, kaç tane bağımsız değişkenimiz olduğuna ve bağımlı değişkenimizin kaç tane grubu olduğuna göre bir veya birden fazla sayıda diskriminant fonksiyonu oluşturulacaktır. Bu örnekte 2 tane diskriminant fonksiyonu oluşturulmuş. Bu fonksiyonlardan, Eigenvalue’su en yüksek olanı dikkate alacağız bundan sonra. Buradan sonra yapacağımız analiz yorumlamalarında 1. fonksiyon dışındakileri göz önüne almayabiliriz.
(Bağımsız değişken sayımız – 1) ya da (bağımlı değişkenimizin kategori sayısı – 1) bu değerlerden hangisi daha küçük ise o kadar sayıda diskriminant fonksiyonu oluşturulur. Bilmeniz gerekmiyor ama merak ettiyseniz diye yazdım.
Ayrıca bu tabloda seçtiğimiz fonksiyonun (bu örnekte Fonksiyon 1) Canonical Correlation değerinin karesini alırsak diskriminant analizimizin etki büyüklüğünü bulmuş oluyoruz.
Sadece 1 adet diskriminant fonksiyonu oluşturulduğunda analizi okuyup yorumlamak daha kolaydır, bu örnekte 2 fonksiyonlu daha karışık bir örnek gösteriyorum ki analizin tabloları karışık olduğunda da nasıl okumak gerektiğini biliyor olun.
Artık Fonksiyon 1’i göz önüne alacağımıza göre Wilks’ Lambda tablosundaki “1 through 2” satırındaki Sig. değerini okumalıyız. Bu satırdaki Sig. p değeri 0.05’ten küçük çıkmış yani diskriminant analizi ile baktığımız bağımsız değişkenlerin en az 1 tanesi bağımlı değişkendeki doğru kategoriyi tahmin etme konusunda işe yarıyor.
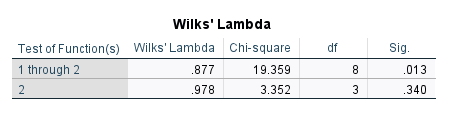
(Sadece Fonksiyon 1’in sütununa bakmanız gerektiğini hatırlatalım.)
Aşağıdaki iki tabloda, aynı değişkenin iki tablodaki değerleri de birbiriyle tutarlı olursa idealdir.
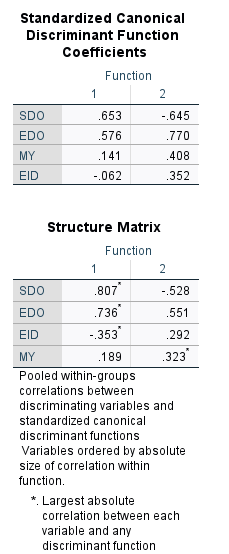
Standardized Canonical Discriminant Function başlıklı tablodaki değerleri okuyarak hangi bağımsız değişkenlerin cinsiyeti tahmin etmedeki benzersiz etkisinin daha güçlü olduğunu görebiliyoruz. Örneğin burada SDO’nun benzersiz etkisi en büyük, EDO’nun benzersiz etkisi ise ikinci sırada geliyor. MY ve EID’in benzersiz etkilerinin 0’a oldukça yakın olduğunu görebiliyoruz; bu mantıklı çünkü bu iki değişkenin cinsiyet tahminindeki etkilerinin anlamlı olmadığını bulmuştuk.
Structure Matrix başlıklı tablodaki değerleri okuyarak her değişkenin toplam ayırma (cinsiyeti tahmin etme) gücünü görebiliyoruz. Bu değerlerin +0.3’ten (veya +0.5’ten) büyük olması gerekiyor normalde. Bu örnekte niye iki değişken +0.5’ten küçük? Çünkü bu iki değişken yukarıdaki tablolardan hatırlayacağımız üzere analize anlamlı bir şekilde katkısı bulunmayan değişkenlerdir. Bu tabloya bakıldığında SDO cinsiyeti ayırmada en güçlü değişkendir, EDO da güçlüdür; MY ve EID ise zayıftır (yani bu tabloda r > 0.50 olanların anlamlı katkı verdiği kabul ediliyor genelde).
Yapısal yükler (Structure Matrix) değişken-fonksiyon korelasyonudur ve çoklu ortaklık etkilerini de içerir; faktör analizindeki “factor loading” gibi yorumlanır. Değişkenin toplam ayırma gücünü görmek için bu tablodaki değerlere bakılır.
Standardize edilmiş katsayılar (Standardized Coefficients) regresyondaki β katsayısına benzer. Bağımsız değişkenlerin “benzersiz katkı”sını görmek için bu tablodaki değerlere bakılır. Değişkenler arası çoklu doğrusallık (multicollinearity) varsa Structure Matrix tablosu ve Standardized Coefficients tablosundaki değerler birbirleriyle tutarsız olabilir; mesela katsayıların işareti tersine dönebilir veya göreceli büyüklükler değişebilir.
Hemen aşağıdaki iki tablonun altında koyduğum tabloda bulunan Standardize edilmemiş katsayılar (Unstandardized Coefficients) ise sadece diskriminant fonksiyonu denklemini kurmak ve kesme değerlerini hesaplamak içindir; hangi bağımsız değişkenlerin cinsiyet tahmininde en önemli olduğunu öğrenmede kullanılmaz.
Aşağıdaki tabloda, aynı regresyon analizinde olduğu gibi, bir y = mx denklemi yazmamız için gereken bilgiler bulunuyor. Bu analiz için şöyle bir denklem yazabiliriz:
Cinsiyet Kategorisi Numarası = (-2.277) + (0.422)*SDO Skoru + (0.339)*EDO Skoru + (0.079)*MY Skoru + (-0.071)*EID Skoru
(Burada Cinsiyet Kategorisi Numarası dediğimiz şey 5 = Kadın; 6 = Erkek; 7 = Diğer olan cinsiyet kategorileri numaralandırmalarıdır. Bu numaralandırmayı SPSS’te veri setini açıp değişkenin değerlerini kontrol ederek bulabilirsiniz.)
Burada MY ve EID’in aslında denkleme sokulmaması da gerekiyor olabilir. Çünkü bu değişkenlerin modelin tahmin gücüne anlamlı bir katkı sağlamadığını deminki tablolardan öğrenmiştik. Zaten bu değişkenlerin aşağıdaki tablodaki katsayılarına bakarsak 0.079 ve -0.071 olan çok küçük değerlere sahip olduklarını görebiliriz. Normalde diskriminant analizini bu iki değişkeni veriden çıkartıp kalan anlamlı değişkenlerle yapmamız gerekiyordu, o zaman formüldeki bütün değerler önemli olmuş olacaktır.
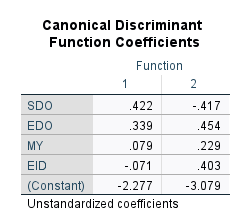
(Yine sadece Fonksiyon 1 sütununa bakmanız gerektiğini unutmayın.)
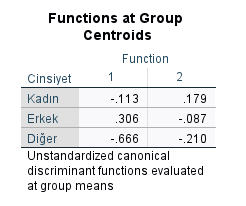
Functions at Group Centroids tablosunda, bağımlı değişkenin her grubu için olan değerlerin birbirinden yeterince farklı olması gerekmektedir. Neyse ki bu örnekteki tabloda yeterince farklı. Demek ki diskriminant analizinde oluşturmuş olduğumuz fonksiyon veri setimizdeki katılımcıların hangi gruba ait olduğunu bulma konusunda çok kötü bir iş yapmamış.
“Classification Results” tablosunda, Original bölümünde gerçekte gözlenen değerleri, Predicted Group Membership bölümünde ise diskriminant analizi sonucunda SPSS’in tahmin etmiş olduğu değerleri görmekteyiz.
Mesela örnek üzerinden gidecek olursak, SPSS, yapılan diskriminant analizi sonucunda, gerçekte Erkek cinsiyetinde olan kişilerin 14 tanesini Kadın olarak tahmin etmiş, 38 tanesini Erkek olarak tahmin etmiş, 18 tanesini ise Diğer cinsiyette olarak tahmin etmiş. Yani 70 tahminin 38 tanesi doğruymuş. Diğer cinsiyet kategorileri için de tabloyu bu şekilde okuyabilirsiniz.
Cross-validated tablosunu çoğu durumda okumak gerekmemektedir.
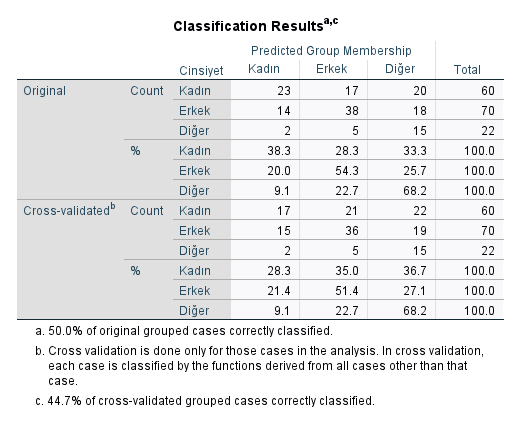
Yukarıdaki tablonun en altında yazan “a. 50% of original grouped cases correctly classified” yazması, şu anlama geliyor: “Demek ki SPSS, diskriminant analizi sonucunda katılımcıların %50’sinin hangi cinsiyette olduğunu doğru tahmin etmiş”. Bu örnekte 3 cinsiyet kategorisi olduğu için rastgele tahmin yapılsaydı %33 doğru tahmin oranı olacağını kolayca hesaplayabiliriz. Ama SPSS diskriminant analizi sonucunda %33 değil, %50 başarılı tahmin oranı yakalamış. %50 çok iyi bir oran olmasa da, %33 rastgele tahmin isabet oranından da daha yüksek bir oran yine de.
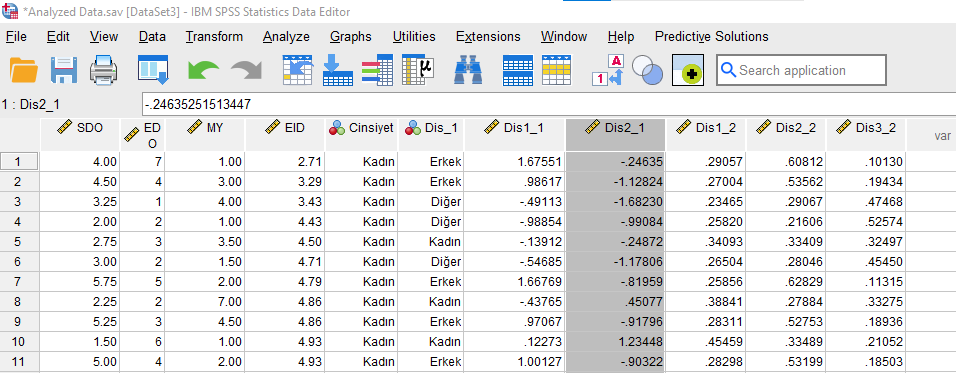
Son olarak, SPSS veri setimizin Data View bölümünde açılmış olan yeni sütunları inceleyelim.
Cinsiyet sütunu zaten vardı, bu sütun, her katılımcının hangi cinsiyette olduğunu gösteriyor. Bu sütunun sağındakiler yeni açılmış olan sütunlardır.
Dis_1 sütunu, SPSS’in, bir katılımcının hangi cinsiyette olduğunu tahmin ettiğini gösteriyor.
Dis1_1, Fonksiyon 1’in bulduğu katsayı. Dis2_1, Fonksiyon 2’nin bulduğu katsayı. Biz, bu örnekte sadece Fonksiyon 1’e bakmamız gerektiğini bulduğumuz için Dis2_1 sütununu silebiliriz.
Dis1_2, Dis2_2 ve Dis3_2, SPSS’e göre bir katılımcının hangi cinsiyette olması gerektiğinin olasılığını gösteriyor. Her satırdaki katılımcı için, bu üç sütundaki değerlerin toplamı tam 1.00 etmektedir. Bu örnekte Kadın = 5 ve Erkek = 6 ve Diğer = 7 olarak kodlanmış olduğu için, burada Dis1_2 Kadın’ı, Dis2_2 Erkek’i ve Dis3_2 Diğer cinsiyeti temsil etmektedir.
Mesela 1 numaralı katılımcı gerçekte Kadın’dır. SPSS, bu kişinin Kadın olma olasılığını %29, Erkek olma olasılığını %60, Diğer cinsiyette olma olasılığını ise %10 olarak tahmin etmiş. Buna göre bu kişinin Erkek olması ihtimalinin daha yüksek olduğunu düşünüp bu kişiyi Erkek olarak sınıflandırmış. Yanlış bir sınıflandırma yapmış.
10 numaralı katılımcıya bakalım. SPSS, bu kişinin Kadın olma olasılığını %45, Erkek olma olasılığını %33, Diğer cinsiyette olma olasılığını ise %21 olarak tahmin etmiş. Buna göre bu kişinin Kadın olması ihtimalinin daha yüksek olduğunu düşünüp bu kişiyi Kadın olarak sınıflandırmış. Doğru bir sınıflandırma yapmış.
SPSS ile Diskriminant Analizi’nin bütün adımları bu kadardı. Artık siz de kendi diskriminant analizinizi yapıp sonuçlarını yorumlayabilirsiniz.
Diskriminant Analizi Varsayımları
Diskriminant analizinin varsayımlarının doğrulanması önemlidir çünkü bu varsayımlar, modelin doğruluğu ve güvenilirliği üzerinde doğrudan etkili olabilir. Bu varsayımların doğrulanması, modelin yanlış sınıflandırma oranlarını azaltarak daha doğru sonuçlar elde etme olasılığını artırır. Bu da sonuçların yorumlanmasını ve modelin güvenilirliğini artırır.
Diskriminant analizinin varsayımları şunlardır:
- Bütün bağımsız değişkenlerin normal dağılıma sahip olması
- Veride uç değer bulunmaması
- Her kategorinin kendi içinde, bütün bağımsız değişken çiftleri arasında doğrusal bir ilişki olmalıdır
- Bağımsız değişkenler arasında çoklu doğrusallık (multicollinearity) olmamalıdır
SPSS ile Diskriminant Analizi Varsayımlarını Test Etme
Bu sayfada yapacağım Diskriminant Analizi örneğinde, 4 ölçeğin (ölçek adları SDO, EDO, MY, EID) sonuçlarının hangilerinin bir kişinin hangi Cinsiyet’te olduğunu ne ölçüde belirlediğini ve hangi ölçeklerin daha belirleyici olduğunu inceleyeceğiz. Cinsiyet 3 kategoriye ayrılıyor: Erkek, Kadın, Diğer. Varsayımları SPSS’te aşağıdaki gibi test ediyoruz.
1) Normal Dağılım Varsayımı
Bağımsız değişkenlerin hepsini Analyze -> Explore menüsünden normallik testine sokup sonuçları analiz etmek gerekmektedir. Bu sayfanın gereksiz uzamaması adına, normallik testinin nasıl yapıldığını anlattığım yazımın linkini buraya koyuyorum.
2) Uç Değer Olmaması Varsayımı
Diskriminant Analizi, lineer (doğrusal) fonksiyonlar üzerine kurulu olduğu için, verinin içinde uç değerler olmasına karşı hassastır. Güvenilir bir diskriminant analizi sonucu elde etmek için, analize başlamadan önce verideki uç değerleri bulup çıkartmak gerekmektedir. Yine bu sayfayı gereksiz uzatmamak adına uç değer tespiti ve ayıklama işleminin nasıl yapıldığını anlatan yazımın linkini buraya koyuyorum.
3) Doğrusal İlişki Varsayımı
Her gruptaki kişiler için, her bağımsız değişken çiftinin skorları arasında doğrusal bir ilişki olmalıdır. Bunu test etmek için SPSS’te şu işlemleri yapıyoruz:
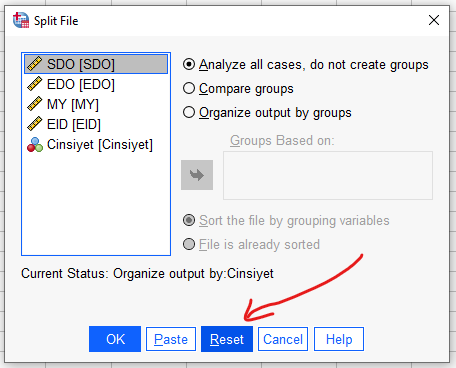
Data -> Split File
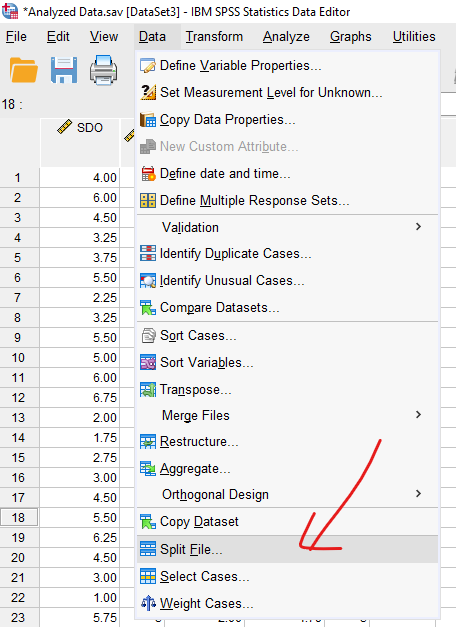
Açılan pencerede “Organize output by groups” seçip bağımlı değişkenimiz olan Cinsiyet’i kutuya koyup OK’a basıyoruz.
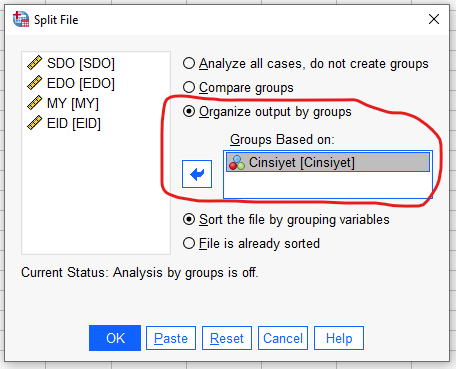
Şimdi verimiz cinsiyetlere göre bölündü.
Graphs -> Scatter/Dot’a basıyoruz.
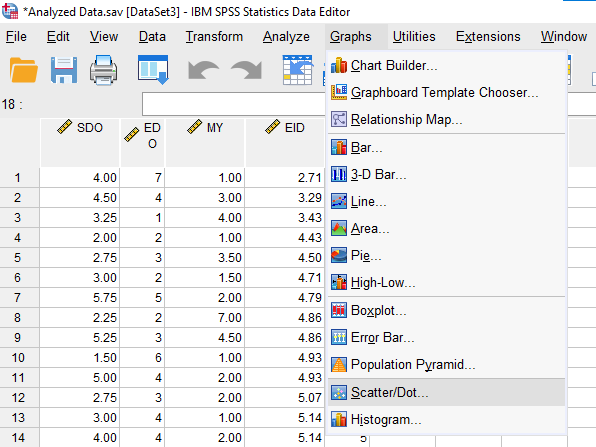
Matrix Scatter’ı seçiyoruz.
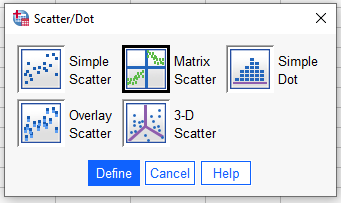
Bağımsız değişkenlerimizin hepsini Matrix Variables kutusuna atıp OK’a basıyoruz.
SPSS, her cinsiyet için bir nokta grafiği çizecek yani bu örnek için toplamda 3 tane. Bu grafiklerde, her cinsiyetin kendi içinde olmak üzere, bağımsız değişkenlerinin birbirleriyle olan ikili korelasyonlarının nokta grafiklerini görmekteyiz.
Bu grafiklerdeki noktaların dağılımı, kırmızı ile çizdiğim gibi, sol alttan sağ üste doğru yayılan (ya da sol üstten sağ alta) noktalar şeklinde olmalıdır. Mükemmel spesifik bir dağılım olması gerekmez ama bir miktar bu şekilde yayıldığını görürsek iyi olur. Bu örnekte de ufak da olsa bir ilişki görebiliyoruz.
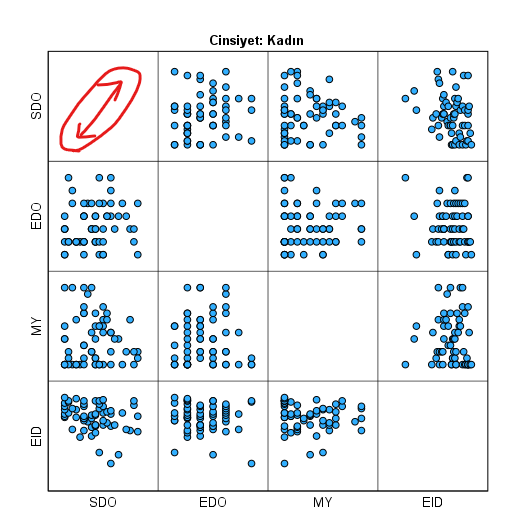
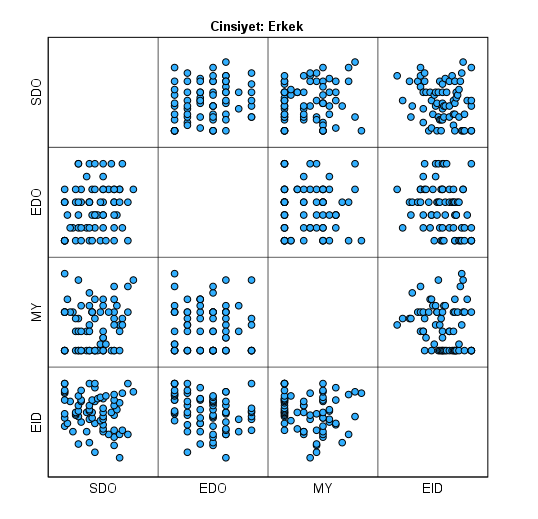
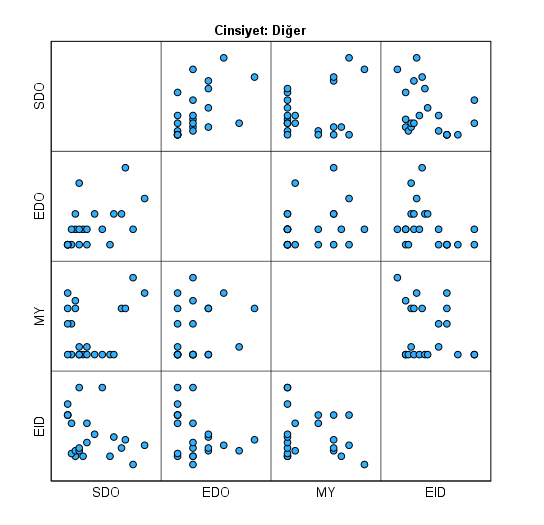
UNUTMAYIN! Doğrusal ilişki incelememiz bittikten sonra, tekrardan Data -> Split File bölümüne gelip açılan pencerede “Reset” butonuna basmalıyız. Bunu yapmazsak bundan sonraki bütün analizlerimiz her cinsiyet için ayrı ayrı 1’er kere yapılır (yani her analiz toplam 3 kere) ve bu yanlış olur.
“Reset” butonuna basıp sonra “OK” butonuna basarak analizlerimize kaldığımız yerden devam edebiliriz.
4) Çoklu Doğrusallık Varsayımı
Bu varsayımı da aşağıdaki gibi kolayca test edebiliyoruz.
Analyze -> Correlate -> Bivariate
Bütün bağımsız değişkenlerimizi Variables kutusuna atıyoruz. Correlation Coefficients’ta Pearson seçili olacak şekilde “OK”a basıyoruz.
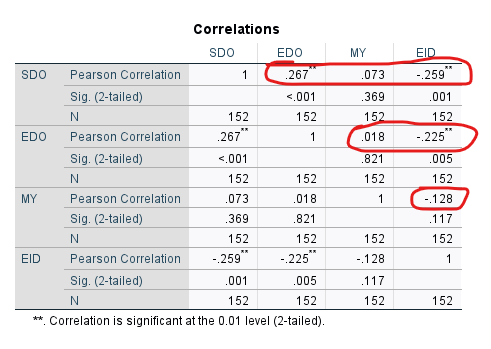
Correlations tablosunda, Pearson Correlation satırlarında, kırmızı işaretlediğim yerlerdeki korelasyon katsayılarının hiçbirinin 0.8 veya daha büyük olmaması gerekiyor. Eğer bu olursa çoklu doğrusallık yani multicollinearity olmuş olur ve bu durum diskriminant analizi sonuçlarının doğruluğunu azaltır. Bu tabloya göre çoklu doğrusallık görülürse birbiriyle çok yüksek korelasyona sahip değişkenlerden birini veriden çıkartıp diskriminant analizini o değişkensiz yapmak gerekir.
SPSS ile Diskriminant Analizi varsayımlarının kontrol edilmesi kısmı bu kadardı. Bütün varsayımları başarıyla doğruladığımıza göre, artık asıl Diskriminant Analizi kısmına geçebiliriz.
Bir yanıt bırakın