
İçindekiler
Multinominal Lojistik Regresyon, bir veya daha fazla bağımsız değişkenin ışığında, 3 veya daha fazla sonuç kategorisine sahip bir bağımlı değişkenin sonuç kategorileri arasından hangisinin gerçekleşeceğini tahmin etmeye yarayan istatistiksel analiz yöntemidir. Multinominal ifadesi, “çok gruplu” anlamına gelmektedir. Bu yazıda, Multinominal Lojistik Regresyon Analizi’nin ne olduğundan ve SPSS programında nasıl yapılacağından bahsedeceğim.
Multinominal Lojistik Regresyon Nedir?
Multinominal Lojistik Regresyon, iki kategoriden fazla kategoriye sahip olan bir bağımlı değişkenin kategorilerinin gerçekleşme olasılığını bağımsız değişkenlerin ışığında tahmin etmek için kullanılan bir istatistik analizi yöntemidir. Bu, iki kategoriye sahip bir sonuç değişkeninin kategorilerinin gerçekleşme olasılığını tahmin etmek için kullanılan Binary Lojistik Regresyon Analizi’nin daha geniş bir versiyonudur.
Multinominal Lojistik Regresyon analizinde bağımlı değişken üç veya daha fazla sırasız kategoriye sahip kategorik yapıda bir veri olmalıdır. (Mesela bir müşterinin mavi-kırmızı-yeşil renkli giysi alma ihtimali). Bağımsız değişkenler ise kategorik veya sayısal veri şeklinde olabilir. Multinominal Lojistik Regresyon analizinde amaç, bağımlı değişkenin her kategorisinin olasılığını bir referans kategorisine göre modellemektir.
Eğer bağımlı değişken sıralı kategoriye sahip ise (mesela çeşitli bağımsız değişkenlerin etkisine göre “fakir – orta gelirli – zengin” olma ihtimali) o zaman Multinominal yerine Ordinal Lojistik Regresyon analizi yapılmalıdır.
Multinominal Lojistik Regresyon modelinde, başta 1 adet referans kategorisi belirlenir ve diğer her bir kategori, ayrı ayrı olmak üzere, referans kategorisi ile karşılaştırılıp referans kategoriye göre gerçekleşme ihtimali tahmin edilir. Her kategorinin gerçekleşme olasılığı, tahmin edilen olasılıkların tüm kategoriler boyunca 1’e toplandığı softmax fonksiyonu adı verilen bir lojistik fonksiyon kullanılarak tahmin edilir.
Multinominal Lojistik Regresyon Analizi, müşterilerin alışveriş tercihlerini tahmin etme, seçmenlerin hangi adaya oy vereceğini tahmin etme, hastalık türlerini tahmin etme gibi sosyal bilimler ve sağlık bilimlerinin çeşitli alanlarında yaygın olarak kullanılır.
Multinominal Lojistik Regresyon Analizi yapabilmemiz için bağımlı değişkenin en az 3 adet “sırasız” kategoriye sahip bir kategorik veri olması şarttır. 3 veya daha fazla “sıralı” kategoriye sahip bir kategorik verimiz varsa, Multinominal yerine Ordinal Lojistik Regresyon analizi yapmak gerekir.

Multinominal Lojistik Regresyon İçin Veriler Nasıl Olmalıdır?
- Yalnızca 1 adet bağımlı değişken olmalıdır.
- Bağımlı değişken 3 veya daha fazla kategoriye sahip olmalıdır. (mesela havuç-portakal-muz tercihi)
- Bağımsız değişkenler 1 veya daha fazla sayıda olabilir.
- Bağımsız değişkenler kategorik yapıda veya sürekli sayısal yapıda olabilirler.
Eğer bağımlı değişken yalnızca 2 kategoriye sahip olsaydı (mesela evet-hayır) o zaman Binary Lojistik Regresyon analizi yapıyorduk.
Hangi durumda hangi testi seçeceğinizden emin değilseniz “Hangi Test?” başlıklı yazımızı okuyarak doğru testi seçmeyi öğrenebilirsiniz.
Multinominal Lojistik Regresyon Varsayımları
Multinominal Lojistik Regresyon Analizi, oldukça güçlü bir regresyon analizi türüdür. Öyle ki Multinominal Lojistik Regresyon Analizi yapabilmek için veride sağlanması gereken çok fazla varsayım yoktur. Örneğin bağımsız değişkenlerin kategorik, ordinal veya sürekli veri tipinde olması fark etmez hepsi analize dahil edilebilir. Yalnızca, bağımlı değişkenin en az 3 adet sırasız kategoriye sahip bir kategorik değişken olması şarttır.
Mesela mavi-yeşil-kırmızı ya da Galatasaray-Fenerbahçe-Beşiktaş-Trabzonspor şeklinde kategoriler olması Multinominal Lojistik Regresyon Analizi için uygundur. Fakat büyük-orta-küçük ya da fakir-orta-zengin şeklinde sıralı kategoriler olması Multinominal Lojistik Regresyon Analizi için uygun değildir, o zaman Ordinal Lojistik Regresyon analizi yapılmalıdır.
Bunun dışında, veride sayısal veri tipinde birden fazla bağımsız değişken varsa, bu bağımsız değişkenlerin birbirleriyle çok yüksek korelasyon göstermemesi iyi olur, fakat bu olsa bile çok önemli bir sorun yaratmaz.
Multinominal Lojistik Regresyon Analizi’ne özel tek varsayım doğrusallık varsayımıdır. (Buna da fazla dikkat edilmez). Lojistik Regresyon Analizi’nde doğrusallık varsayımı, bağımsız değişkenlerin log-odds oranı (logit fonksiyonuyla bulunan) ile doğrusal bir ilişkiye sahip olmasıdır. Bu, analize dahil olan her bir sürekli bağımsız değişkenin, bağımlı değişkenin log-odds değerleri üzerinde sabit ve doğrusal bir etkiye sahip olması gerektiği anlamına gelir. Eğer bu ilişki doğrusal değilse (eğrisel ise), model tahminlerinde yanlılık oluşabilir ve isabetliliği azalabilir. Lojistik Regresyon Analizi’nin doğrusallık varsayımını nasıl test edeceğimizi ayrı bir sayfada anlatıyorum, tıklayıp okuyabilir ve okuduktan sonra buraya geri dönebilirsiniz.
SPSS ile Multinominal Lojistik Regresyon Nasıl Yapılır?
SPSS ile Multinominal Lojistik Regresyon analizi yapma adımlarını aşağıda anlatıyorum.
Öncesinde, bu örnekte nasıl bir veriyi analiz edeceğimizden bahsedeyim. Bu, analizde neler yaptığımızı anlamanıza yardımcı olacak.
Bu örnekte, ekonomik durumun, sorumluluk duygusunun ve reşit olup olmama durumlarına göre bir insanın restoranda ısmarladığı yemek türünü tahmin etmek için Multinominal Lojistik Regresyon analizi yaparak yemek türü üzerindeki tahmin edici etkileri araştıracağız.
Değişkenler SPSS üzerindeki veride şu şekilde kodlandı:
- Ekonomik Durum -> Kategorik veri (1 = Fakir; 2 = Orta; 3 = Zengin)
- Sorumluluk Duygusu -> Sayısal veri (1’den 7’ye kadar)
- Reşit Olup Olmama -> Kategorik veri (0 = Reşit değil; 1 = Reşit)
- Yemek Seçimi -> Kategorik veri (5 = Hamburger, 6 = Salata, 7 = Yoğurt, 8 = Pizza)
Şimdi, SPSS’te Multinominal Lojistik Regresyon analizine başlayalım.
Analyze -> Regression -> Multinominal Logistic
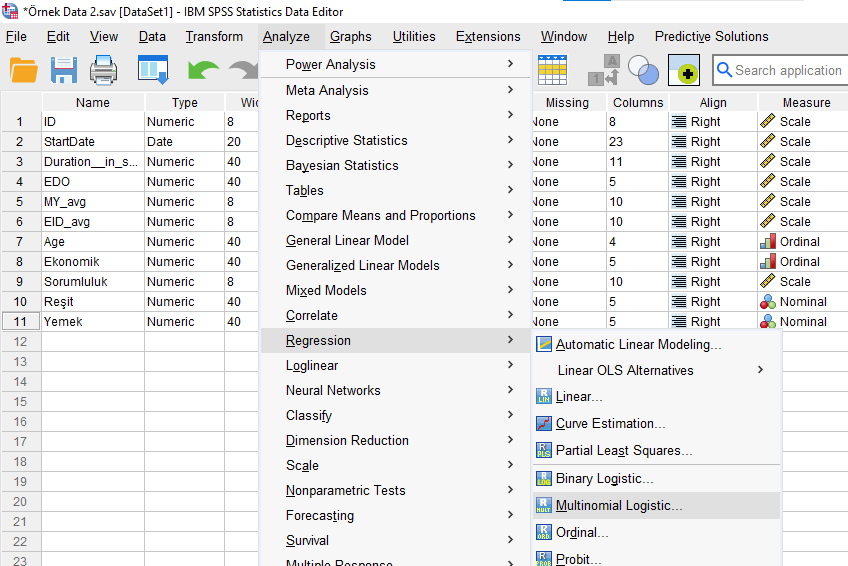
Bağımlı değişkeni Dependent kutusuna atıyoruz.
Bağımsız değişkenlerden, sayısal veri tipinde olanları ve/veya sadece 2 kategoriden oluşan kategorik veri tipinde olanları, en alttaki Covariate(s) kutusuna atıyoruz. Sadece 2 kategoriden oluşan kategorik veriler bunun için analiz öncesinde “0 – 1” şeklinde kodlamış olmalıdır. “1 – 2” veya başka şekillerde kodlanmış olsalardı analiz sonuçlarını yorumlamak için çok uygun olmazdı.
Bağımsız değişkenlerden, 3 veya daha fazla kategoriye sahip olan veya ordinal (sıralı) yapıda olan değişkenleri, ortadaki Factor(s) kutusuna atıyoruz.
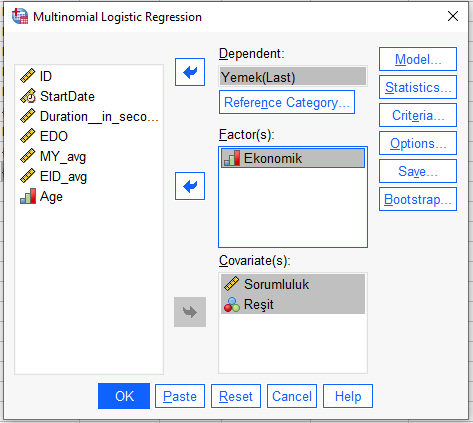
Bağımlı değişkenin kategorilerini nasıl tahmin edeceğimizi belirlemek için 1 adet referans kategorisi belirlemeliyiz. Bunun için “Reference Category” butonuna basıyoruz.
Açılan yeni pencerede herhangi birini işaretleyebilirsiniz ama hangisini işaretlediğiniz aklınızda olsun.
Biz burada Reference Category olarak First Category işaretliyoruz. Hatırlarsanız bağımlı değişkenimiz olan Yemek’i kodlarken 5’ten 8’e kadar değerler kullanmıştık. First Category işaretlediğimizde, referans kategorisi en küçük değer olan kategori oluyor, yani 5 = Hamburger oluyor referans kategorimiz. Diğer bütün yemek türlerini hamburger ile karşılaştıracağız yani analiz sonuçlarını okurken.
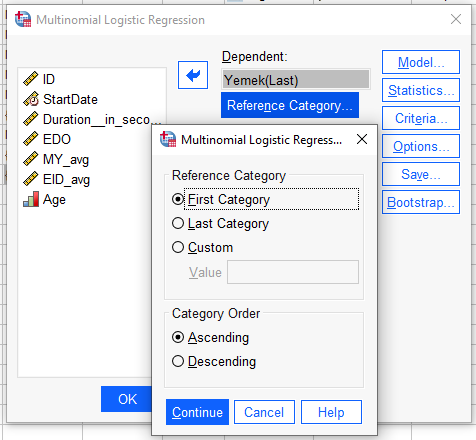
“Statistics” butonuna basıyoruz. Aşağıdaki resimde görünen seçenekleri işaretliyoruz.
“Save” butonuna basıyoruz. Aşağıdaki resimdeki Saved Variables kısmındaki dört seçeneği de işaretliyoruz.
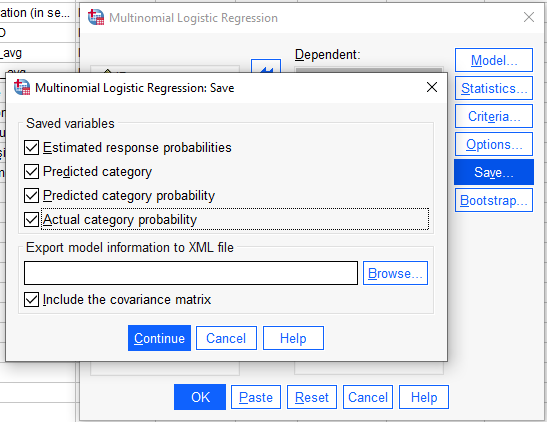
“Continue” ve “OK” butonlarına basarsak SPSS multinominal lojistik regresyon analizimizi başlatacak. Analiz sonuçlarının nasıl yorumlanması gerektiğini aşağıdaki başlığın altında bulabilirsiniz.

Multinominal Lojistik Regresyon SPSS Tablo Yorumlama
Multinominal Lojistik Regresyon analizini başlattıktan sonra, SPSS bize birtakım tablolar verecek.
Model Fitting Information
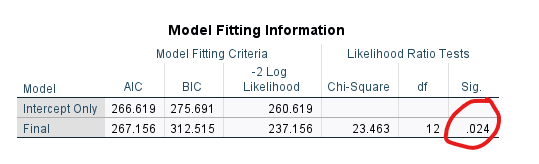
“Model Fitting Information” tablosundaki Sig. değeri, p değerini veriyor. Buraya bakarak, Multinominal Lojistik Regresyon modelimizin p anlamlılık değerini görebiliyoruz. Eğer bu p değeri 0.05’ten küçükse, bu demek oluyor ki regresyon modelimiz, bağımsız değişkenlere dayanarak Yemek Tercihi kategorilerini tahmin etme konusunda istatistiksel olarak anlamlı şekilde başarılı olmuş.
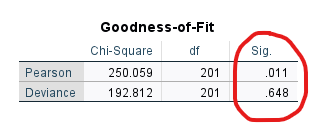
Goodness Of Fit
“Goodness Of Fit” tablosu, SPSS ile kurduğumuz Multinominal Lojistik Regresyon modelimizin bizim verimize ne kadar uyumlu olduğunu gösteriyor. Yeterince uyumlu olmasını istiyoruz. Bunun için buradaki Pearson ve Deviance değerlerinin 0.05’ten büyük olmasını istiyoruz. Eğer 0.05’ten büyük bir değer varsa, bu, bizim regresyon modelimizin veri setimize uyumu iyi demektir.
Bizim örneğimizde Pearson 0.05’in altında çıkmış, Deviance 0.05’in üstünde çıkmış. Bazen Pearson ve Deviance değerleri böyle çelişkili çıkabiliyor. Böyle durumlarda Deviance değeri Pearson’dan daha sağlam olduğu için Deviance değeri neyse onu doğru kabul ediyoruz.
Pseudo R-Square
“Pseudo R-Square” tablosunda üç farklı lojistik regresyon R-Kare değeri gösterilmektedir. Bu değerler, doğrusal regresyon modellerindeki R-Kare değerlerinin analojileridir. Benzer amaçla kullanılırlar ama hesaplanma yöntemleri farklıdır.
Cox and Snell ve Nagelkerke R-Square değerleri, doğrudan modelin bağımlı değişkendeki varyasyonu ne kadar açıklayabildiğini göstermezler fakat çoğunlukla tez-makale istatistik analizi raporlarında bu şekilde raporlanırlar. Buradaki üç Pseudo R-Square değeri arasından Multinominal Lojistik Regresyon analizi için en uygun olan McFadden olduğu için bu daha güvenle kullanılabilir.
Bu örnekteki McFadden Pseudo R-Square değerimiz 0.70, yani “Bağımsız değişkenlerden oluşturduğumuz Multinominal Lojistik Regresyon modeli, Yemek Tercihi bağımlı değişkenimizdeki varyasyonun %7’sini açıklamaktadır.” şeklinde bir yorumlama yapabiliriz.

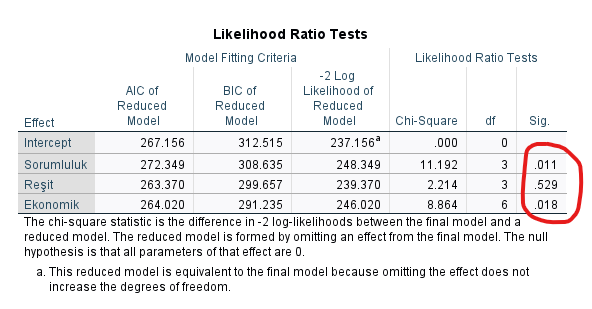
Likelihood Ratio Tests
“Likelihood Ratio Tests” tablosundaki Sig. değeri, p değerini ifade ediyor ve her bağımsız değişkenin ayrı ayrı olarak bağımlı değişkenin kategorilerini istatistiksel olarak anlamlı biçimde tahmin edebilip edemediği hakkında bilgi veriyor. Bu tabloya göre, Sorumluluk değişkeni Yemek Tercihi’ndeki kategorileri istatistiksel olarak anlamlı biçimde tahmin ediyor. Reşit olup olmamak anlamlı biçimde açıklamıyor yani önemsiz. Ekonomik durum da Yemek Tercihi’ndeki kategorileri istatistiksel olarak anlamlı biçimde tahmin ediyor.
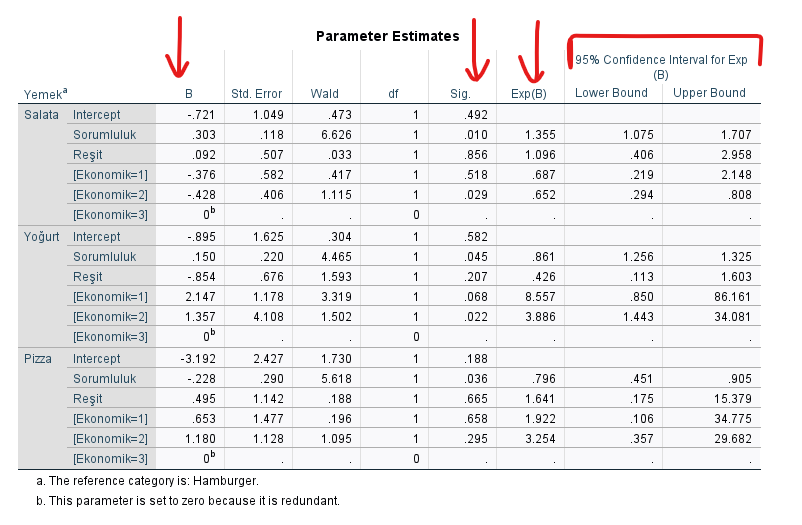
Parameter Estimates
“Parameter Estimates” tablosu, incelemek için en çok zaman harcanacak Multinominal Lojistik Regresyon analiz sonucu tablosudur. Bu tablodaki her satırı ayrı ayrı açıklayacağım sırayla. Böylece farklı durumlarda nasıl farklı yorumlar yapılıyor onu görmüş olacaksınız.
Öncelikle bağımlı değişkenimiz olan Yemek Tercihi’ni nasıl kodlamış olduğumuzu hatırlayalım: 5 = Hamburger, 6 = Salata, 7 = Yoğurt, 8 = Pizza
Hamburger’i referans kategorisi olarak seçmiştik başlangıçta. Bu tabloda, sırayla Salata, Yoğurt, ve Pizza kategorileri, Hamburger kategorisiyle karşılaştırılıyor. (Eğer Salata’yı Yoğurt’la karşılaştırmak istiyorsanız bu ikisinden birini referans kategorisi alan başka bir Multinominal Lojistik Regresyon analizi kurmalısınız.)
Salata – Sorumluluk
Salata’ya ait olan Sorumluluk satırına bakalım. Önce Sig. değerine bakıyoruz. Bu p değerini ifade ediyor. Buradaki değer 0.010 yani 0.05’ten küçük anlamlı bir p değeri. Demek ki Sorumluluk seviyesi Salata ısmarlama ihtimalini anlamlı biçimde tahmin edebiliyor.
Sig. sütunundaki p değeri 0.05’ten küçük ise “anlamlı etkiliyor”, p değeri 0.05’ten büyük ise “anlamlı etkilemiyor” şeklinde yorumluyoruz.
B değeri pozitif. B değeri sadece doğrusal bir fonksiyonda işe yarayan bir katsayıdır. Fakat lojistik regresyon doğrusal bir fonksiyon değildir. Bu yüzden B değerini Exp(B) diye başka bir katsayıya çevirip onu yorumlamak gerekiyor. O yüzden biz B yerine Exp(B) değerine bakıp yorumlama yapacağız. Salata için Sorumluluk’un Exp(B) değeri 1.355’miş.
Exp(B), bir lojistik regresyon modelinin B katsayısının üstel fonksiyonunu ifade eder. Bu, bir birimlik değişikliğin olasılık oranındaki (Odds Ratio) etkisini temsil eder. Bu yüzden Exp(B) değeri için Odds Ratio terimi de kullanılmaktadır.
1.355 olan Exp(B) değeri şu anlama geliyor: Sorumluluk puanı arttıkça, Hamburger yerine Salata tercih etme oranı artıyor. Sayısal olarak detaylıca şöyle yorumlayabiliriz: “Sorumluluk’ta eğer 1 puanlık artış meydana geliyor ise, bir katılımcının yemek olarak Hamburger yerine Salata seçme ihtimali, Hamburger seçme ihtimalinin %135.5’i kadardır.”
Sorumluluk’ta eğer 2 puanlık artış meydana geliyorsa Salata seçme ihtimali, Hamburger seçme ihtimalinin %135.5′inin %135.5′i kadar oluyor yani en baştaki ihtimalin %183.6’sı kadar oluyor…
B değeri pozitif ise Exp(B) değeri her zaman 1’den büyük olur, B değeri negatif ise Exp(B) değeri her zaman 1’den küçük olur.
Salata – Reşitlik Durumu
Reşit Olup Olmama değişkeninin Sig. yani p değeri 0.856 çıkmış. Yani p değeri 0.05’ten büyük olduğu için istatistiksel olarak anlamlı değil. Bu yüzden normalde bu değişken için tabloyu daha fazla okumaya gerek yok.
Fakat örnek göstermek açısından, eğer istatistiksel olarak anlamlı bir p değeri çıksaydı nasıl olurdu yorumlayalım.
Reşitlik durumu en başta 0 = Reşit Değil; 1 = Reşit olarak kodlanmıştı. Yemek de 5 = Hamburger, 6 = Salata olarak kodlanmıştı.
Exp(B) değeri 1.096 ve B değeri pozitif. Şöyle yorumluyoruz: “Reşit olmak, yemek olarak Hamburger yerine Salata seçme ihtimalini baştaki ihtimalin %9.6’sı kadar arttırarak %109.6’sı yapıyor.”
Salata – Ekonomik Durum
Ekonomik Durum değişkeni 3 kategoriye sahip bir kategorik değişken. Bunu incelemek için de 1 adet referans kategorisi seçerek diğer kategorileri o referans kategoriyle karşılaştırmalıyız. Ekonomik Durum değişkenini başlangıçta 1 = Fakir; 2 = Orta; 3 = Zengin kodlamıştık. Parameter Estimates tablosuna bakarsak SPSS’in Zengin’i referans kategorisi olarak atadığını görüyoruz.
1. modele bakarsak, Sig. yani p değeri 0.518 çıkmış, bu p değeri 0.05’ten büyük olduğu için istatistiksel olarak anlamlı değil. Bu yüzden bu satırı daha fazla okumaya gerek yok.
2. modele bakarsak, Sig. yani p değeri 0.029 çıkmış, bu p değeri 0.05’ten küçük olduğu için istatistiksel olarak anlamlı. 0.652 olan Exp(B) değerine bakarsak, diyebiliriz ki “Zengin yerine Fakir olmak, Yemek olarak Hamburger yerine Salata seçme ihtimalini Hamburger seçme ihtimalinin %65.2’si kadar yapıyor.” Başka bir deyişle: “Zengin yerine Fakir olmak, Hamburger yerine Salata seçme ihtimalini %34.8 azaltıyor.”
(100 – 65.2 = 34.8 işlemini yaptık bu hesabı yaparken.)
Not: Burada maalesef Fakir ekonomik durumdan Orta ekonomik duruma geçmek Salata seçme ihtimalini ne kadar arttırıyor direkt olarak göremiyoruz. Bunu görebilmek için Fakir veya Orta bu ikisinden birini referans kategorisi olarak ayarlayıp yeniden lojistik regresyon analizi yapmalıyız. O zaman görürüz.
Yoğurt ve Pizza
Bağımsız değişkenlerin durumunun Yoğurt ve Pizza seçimini tahmin edebilip edemediğini de, aynı yukarıda Salata seçme ihtimalini incelediğimiz şekilde incelemek gerekiyor. Yaşanabilecek bütün tipte örnekleri (kategorik ve sürekli veri tipindeki pozitif ve negatif B değerlerini, 1’den büyük ve küçük Exp(B) değerlerini) yukarıdaki örneklerde gösterdim. Aynı mantığı kullanarak analiz tablolarını okumaya devam edebilirsiniz.
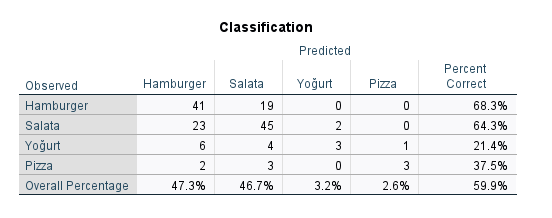
Classification Tablosu
Son olarak, “Classification” tablosuna bakalım. “Observed” bölümündekiler gerçek değerlerdir ve “Predicted” bölümünde bulunan değerler SPSS’in, kurduğu Multinominal Lojistik Regresyon modeli üzerinden tahmin ettiği değerlerdir.
Burada ilk satıra bakarsak, SPSS’in Hamburger seçen toplam 60 kişiden 41’ini Hamburger seçiyor olarak, 19’unu ise Salata seçiyor olarak bulduğunu görüyoruz. Yani 60 kişiden 41’inin tercihini doğru bilmiş. %68.3 oranla doğru bilmiş.
Yine benzer şekilde Salata seçen toplam 70 kişiden 45’inin Salata seçeceğini doğru bilmiş SPSS. %64.3’lük bir isabetli tahmin oranı var.
Yoğurt ve Pizza’yı ise epey başarısız tahmin ettiğini görüyoruz; tahminlerin isabet oranı birinde %21.4 birinde de %37.5. Bu durum Multinominal Lojistik Regresyon analizlerinde normaldir. Yoğurt ve Pizza seçen kişi sayıları, Hamburger ve Salata seçen kişi sayılarına göre çok az olduğundan, SPSS, Multinominal Lojistik Regresyon modelini Hamburger ve Salata seçimlerine uydurmaya Yoğurt ve Pizza’dan daha çok çalışmıştır. Bu yüzden az kişinin seçtiği kategorileri doğru tahmin etme oranı genelde düşük olmaktadır.
Bizim için genelde pratikte çok katılımcının tercih ettiği değerleri başarılı şekilde tahmin etmek daha önemli oluyor. Bu yüzden az katılımcının tercih ettiği değerlerin Multinominal Lojistik Regresyon analizinde SPSS tarafından düşük isabetle tahmin edilmiş olması büyük bir sorun değil.
Multinominal Lojistik Regresyon analizi sonucu SPSS tablolarını yorumlama kısmı bu kadardı. Son olarak, veri setinde bir şeyi daha göstermek istiyorum.
SPSS’te regresyon analizine başlarken “Save” kısmında dört farklı seçenek işaretlemiştik. Bu işaretlediğimiz seçenekler SPSS veri setimizde yeni sütunlar açılmasına yol açtı. Bu sütunları ve her katılımcı için değerlerini SPSS Variable View penceresinde en sağ tarafta görebilirsiniz. Bunlar ne demek bakalım:
- EST = Estimated Response Probabilities (tahmini cevap olasılığı)
- PRE = Predicted Category (beklenen kategori)
- PCP = Predicted Category Probability (beklenen kategori olasılığı)
- ACP = Actual Category Probability (gerçek kategori olasılığı)
Aşağıda, bunların sırayla ne demek olduğunu ve neden kullanışlı olduğunu açıklayıp yazıyı bitireceğim.
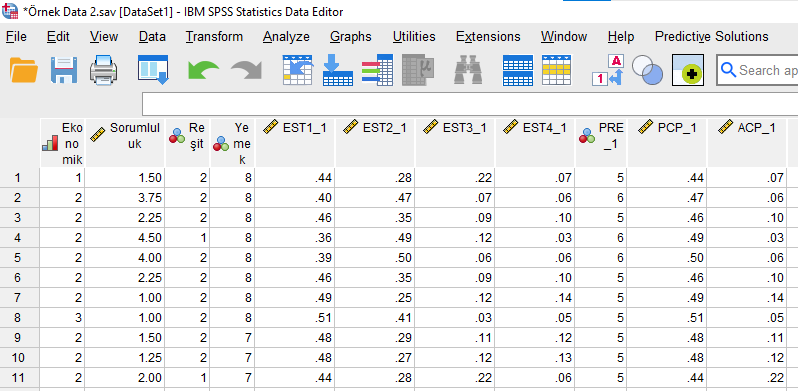
Hatırlarsak bağımlı değişken olan Yemek kategorilerini şu şekilde kodlamıştık: 5 = Hamburger, 6 = Salata, 7 = Yoğurt, 8 = Pizza. Küçükten büyüğe sıralandığında EST_1 Hamburger’e, EST_2 Salata’ya, EST_3 Yoğurt’a, EST_4 de Pizza’ya karşılık gelmektedir. Her satır bir katılımcıyı ifade ediyor. Her satırda bu dört sütunda SPSS’in, kurduğu lojistik regresyon modeline göre o katılımcının seçeceği Yemek çeşidinin SPSS’in tahmin ettiği olasılıkları görünüyor.
Mesela en üst satırdaki katılımcının Ekonomik Durum, Sorumluluk, ve Reşit olup olmama durumuna göre Hamburger, Salata, Yoğurt, ve Pizza seçimi ihtimallerini SPSS şöyle tahmin etmiş: 1. katılımcı %44 Hamburger, %28 Salata, %22 Yoğurt ve %7 Pizza seçer diye tahmin etmiş. Bunların arasında en yüksek ihtimal Hamburger olduğu için, PRE sütununda 5 yazıyor yani Hamburger’in kodu. PCP’de o satırdaki en yüksek ihtimalli kategorinin ihtimali kaç ise o yazar. ACP kategorisinde ise gerçekte bu katılımcının seçtiği gerçek yemeğin oranı yazar. Bu katılımcı SPSS’in %7 ihtimal verdiği Pizza yemeğini seçmiş. Yani bu katılımcının ne yemek seçtiğini SPSS yanlış tahmin etmiş.
Bu şekilde bütün katılımcılar için SPSS’in yaptığı tahmin ve gerçek değeri karşılaştırdığımızda, SPSS’in toplam bütün tahminlerinin %59.9’u doğru isabetli olmuş olacak, Classification tablosundan bunu biliyoruz.
Son bir yorum daha: Verimizdeki bütün katılımcılar kapsamında düşündüğümüzde, PCP sütunundaki Predicted Category Probability yani beklenen kategori olasılığı değerleri genel olarak ne kadar büyükse SPSS ile kurduğumuz multinominal lojistik regresyon modeli o kadar başarılıdır ve iyi çalışmaktadır diyebiliriz.
SPSS programında Multinominal Lojistik Regresyon Analizi yapması ve sonuçlarını yorumlaması bu kadardı. Artık yaptığımız analizi raporlama işlemini yapabiliriz. Yazıyı baştan sona okuduysanız, analiz yapma ve yorumlama kısmında hiçbir sorun yaşamıyor olmanız lazım.
Eğer buradaki gibi 3+ sırasız kategoriye sahip olan değil de 3+ sıralı kategoriye sahip olan bir bağımlı değişkenin kategorilerini tahmin etmek nasıl yapılıyor merak ediyorsanız bunun için Ordinal Lojistik Regresyon analizi yapmanız gerekmektedir. Bu analizi öğrenmek için de “SPSS ile Ordinal Lojistik Regresyon Analizi” yazımızı linke tıklayarak okuyabilirsiniz. Şimdilik görüşmek üzere.
Bir yanıt bırakın