
İçindekiler
Kukla değişken, doğrusal (lineer) regresyon analizi yaparak bağımlı değişken üzerindeki etkilerini incelemek istediğimiz bağımsız değişkenlerin arasında kategorik yapıda bir bağımsız değişken bulunduğu durumlarda devreye giren bir istatistik uygulamasıdır. Doğrusal regresyon analizine kategorik yapıda bir bağımsız değişken, 2 kategoriye sahip ise “0 – 1” kodlama biçimine dönüştürülerek dahil edilebilir.
Eğer kategorik yapıdaki bir bağımsız değişken 3 veya daha fazla kategoriye sahipse, yine de “0-1” kodlama biçimine dönüştürülerek dahil edilebilir. Bu yazıda, 3 veya daha fazla kategoriye sahip kategorik bağımsız değişkenlerin kukla değişken haline nasıl dönüştürülüp SPSS’te doğrusal regresyon analizine nasıl dahil edileceğini anlatıyorum.
DİKKAT: Bu sayfada anlatacağım kukla değişken regresyon örneği, 3 veya daha fazla değere sahip olabilen (mesela Hetero Erkek, Hetero Kadın ve LGBT cinsiyet) kategorik değişkenler hakkındadır.
Kukla değişken hakkında ilk kez bilgi öğreniyorsanız, öncelikle yalnızca 2 kategoriye sahip olan kategorik değişkenlerin (mesela Erkek ve Kadın) kukla değişken olarak kodlanıp regresyon analizine dahil edilmesini öğrenmenizi öneririm.
Bu yüzden eğer konuyu ilk kez öğreniyorsanız önce “SPSS ile Kukla Değişken Regresyon (2 Kategori)” başlıklı diğer yazımı okuyup, 2 kategori için kukla değişkeni iyice öğrendikten sonra şu an bulunduğunuz 3+ kategorili kukla değişken sayfasına dönüp okumaya devam etmenizi öneririm.
Kukla Değişken Nedir?
Basit veya Çoklu doğrusal regresyon analizlerinde kukla değişken kavramı İngilizce’de “dummy variable” teriminin karşılığıdır (ayrıca “gösterge değişkeni” olarak da bilinir). Kukla değişken, kategorik yapıdaki bir bağımsız değişkenin regresyon modelindeki kategorilerini temsil etmek için kullanılan bir değişkendir. Kukla değişkenler SPSS’te her zaman ikili (0 veya 1) olarak kodlanır, burada genellikle “0” belirli bir kategorinin yokluğunu ve “1” bu kategorinin varlığını temsil eder.
3 veya daha fazla kategoriye sahip olan bir kategorik değişken için kukla değişken oluşturma işlemi şöyledir:
- Kukla Değişkenlerin Oluşturulması: Diyelim ki üç kategorisi olan “Grup” adında bir kategorik bir değişkenimiz var: A, B ve C. Bu değişkeni SPSS’de bir regresyon analizine dahil etmek için, 1 adet referans kategorisi seçip diğer grupları bu referans kategorisiyle karşılaştırmamız gerekir. Yani 3 gruba sahip bir bağımsız değişken için 2 tane kukla değişken oluşturmamız gerekir. Mesela A, B, C gruplarımız varsa ve A grubunu referans kategorisi olarak seçtiysek, “Kukla_B” ve “Kukla_C” adında iki kukla değişken oluşturmak gerekiyor.
- Kukla Değişkenlerle Regresyon Analizi: Kukla değişkenler oluşturulduktan sonra, SPSS’te diğer bağımsız değişkenlerle birlikte bir regresyon modeline dahil edebiliriz. Örneğin, “Skor” gibi bir sürekli veri tipindeki bağımlı değişkenin “Grup” ve diğer bağımsız değişkenler tarafından nasıl etkilendiğine bakıyorsak, SPSS’te bir regresyon analizi yaparız ve “Skor” bağımlı değişken olarak, “Kukla_B” ve “Kukla_C” (diğer bağımsız değişkenlerle birlikte) bağımsız değişkenler olarak yer alır.
- Katsayıların Yorumlanması: SPSS’teki regresyon çıktısında, her kukla değişkenin kendi katsayısı olacaktır. Bu katsayılar, referans kategorisi (genellikle hiçbir kukla değişken tarafından temsil edilmeyen kategori) ile kukla değişken tarafından temsil edilen kategori arasındaki bağımlı değişkenin ortalama değerindeki farkı temsil eder.
Bu örnekte A grubu referans kategori olarak seçilmişti.- Örneğin, “Grup_B” için regresyon analizi sonucunda elde edilen regresyon katsayısı 5 ise, bu, ortalama olarak, bağımlı değişkenin kategori B’deki gözlemler için referans kategorisine göre (A grubuna göre) 5 birim daha yüksek olduğu anlamına gelir.
- “Grup_C” için regresyon analizi sonucunda elde edilen regresyon katsayısı -3 ise, bu, ortalama olarak, bağımlı değişkenin kategori C’deki gözlemler için referans kategorisine göre (A grubuna göre) 3 birim daha düşük olduğu anlamına gelir.
Şimdi kafanızda tam oturmadıysa sorun değil, aşağıda adım adım resimlerle göstereceğim zaten.

SPSS’te 3+ Kategori İçin Kukla Değişken Kodlama
Bu örnekte, 3 kategorisi olan Cinsiyet değişkeninin, Depresyon seviyesine etkisini analiz edeceğiz. Kategoriler Hetero Erkek, Hetero Kadın, LGBT şeklinde. Daha okunaklı olması açısından “Hetero Erkek” ve “Hetero Kadın” yerine “Erkek” ve “Kadın” olarak bahsedeceğim.
Öncelikle, kategorik bir değişken olan Cinsiyet’i, yapacağımız bir çoklu doğrusal regresyon analizine dahil edebilmemiz için, bu değişkeni SPSS’te kukla olarak kodlamalıyız (dummy coding). Kukla değişkenin değerleri kesinlikle 0 veya 1 olarak kodlanmalı. Yoksa SPSS analizi düzgün çalıştırmaz.
3 grup olunca “0 – 1” kodlamasını nasıl yapıyoruz aşağıda bakalım:
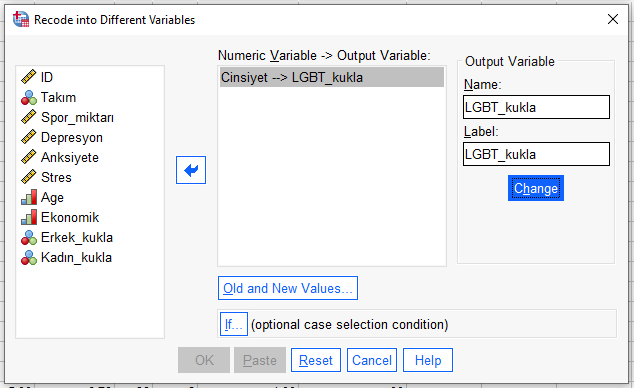
Transform -> Recode into Different Variables
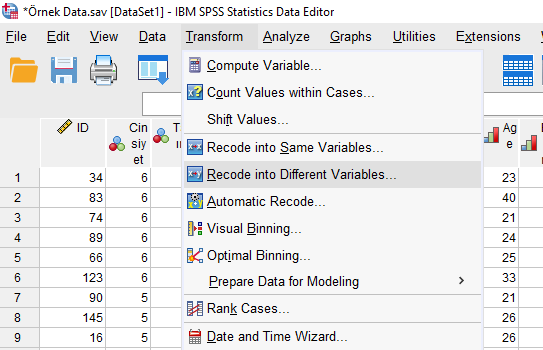
Veri setimizde 3 farklı cinsiyet olduğu için 2 tane farklı kukla değişkeni oluşturmalıyız. Yani 2 kere kukla değişken oluşturma işlemi yapacağız.
Ben burada örnek olsun diye bütün değişkenler için kukla değişken oluşturmayı gösteriyorum. Yani 3 kategori için ben bu sayfada 3 kere kukla değişken kodlama yaptım ama siz 2 kere yapsanız da yeter (yani referans kategorisi olarak seçtiğiniz kategori için kukla değişken oluşturmanıza gerek yok).
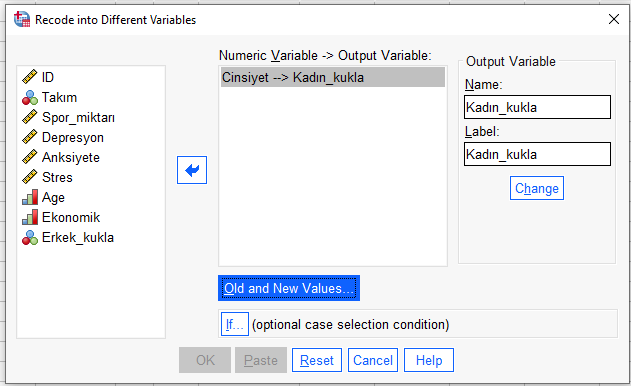
Önce, Erkek cinsiyeti 1, diğer cinsiyetler 0 olarak kukla değişken oluşturma işlemini yapalım.
Cinsiyet’i soldaki kutudan alıp sağdaki kutuya koyuyoruz. Sonra Erkek değerini kukla değişken yapacağımız için Output Variable bölümüne Erkek_kukla gibi, ayırt edici bir isim veriyoruz. Change’e basıyoruz.
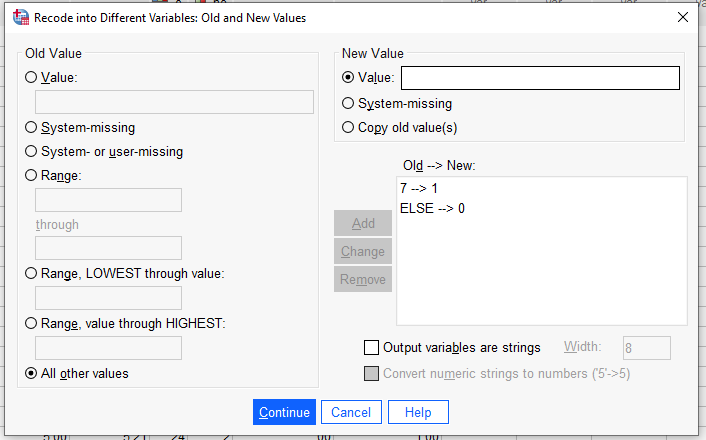
Sonra “Old and New Values” butonuna basıyoruz.
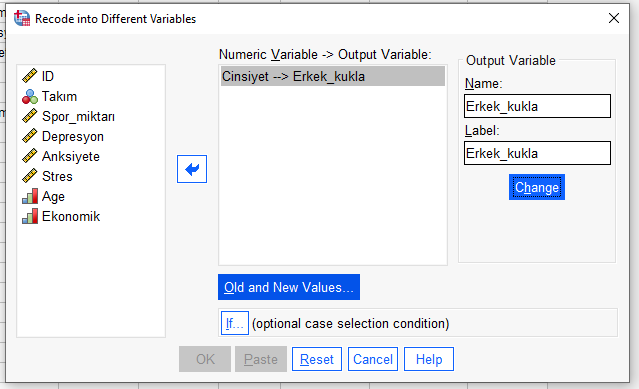
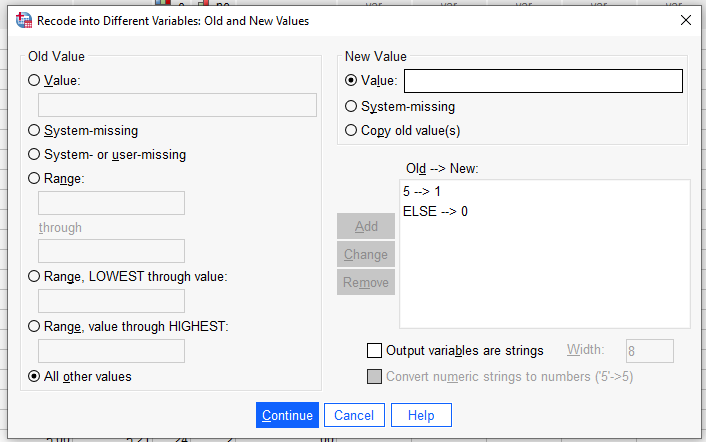
Bu veri setinde Kadın = 5; Erkek = 6; LGBT = 7 olarak kodlanmıştı.
Önce Old Value’ya 6 yazıyoruz, New Value’ya 1 yazıyoruz. Add butonuyla sağ alttaki kutuya ekliyoruz.
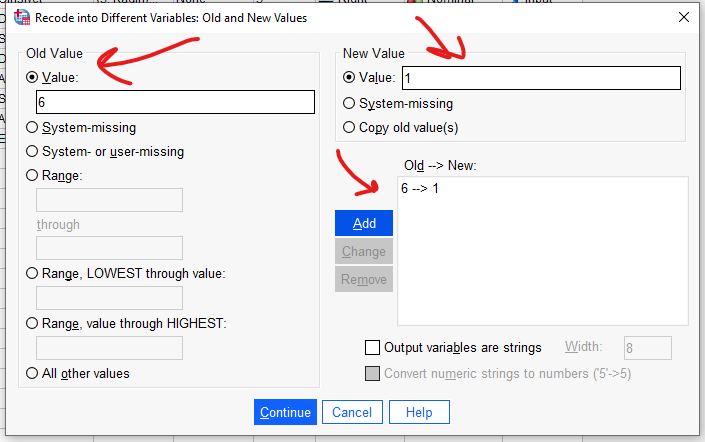
Sonra “All other values”a basıyoruz. New Value olarak 0 belirliyoruz. Add ile sağ alttaki kutuya ekliyoruz.
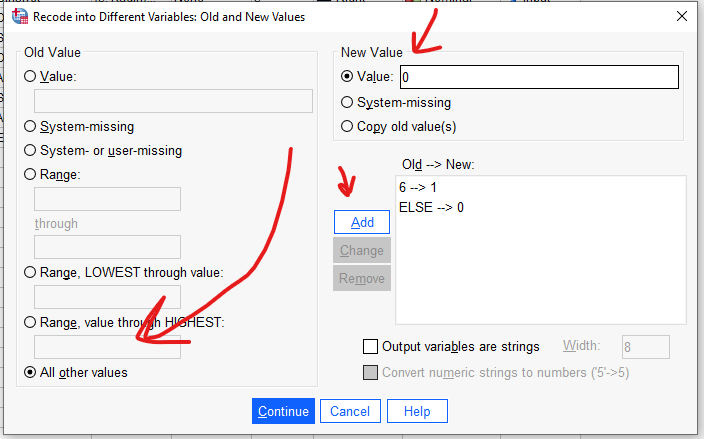
Continue ve OK’a basıyoruz.
SPSS veri setimize geri dönüp baktığımızda en sağ sütunda Erkek_kukla isminde yeni bir değişken oluştuğunu göreceğiz.
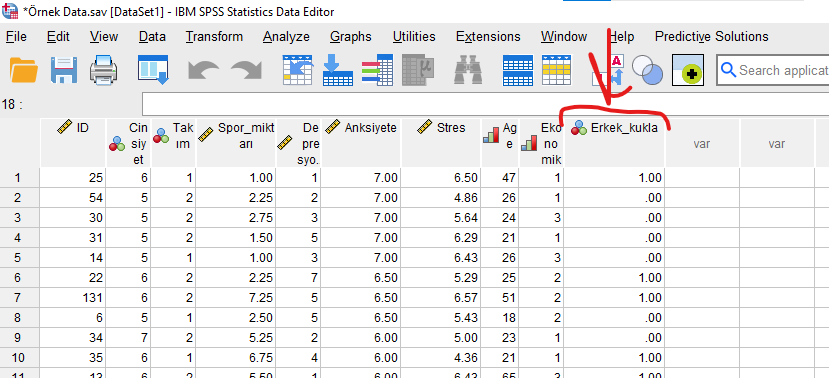
Şimdi aynı işlemi, Kadın ve LGBT cinsiyetleri için de yapmamız gerekiyor.
Reset butonuna basıp sıfırlayalım, sonra aynı işlemi Kadın kategorisiyle baştan yapalım.
LGBT kategorisi için baştan yapalım.
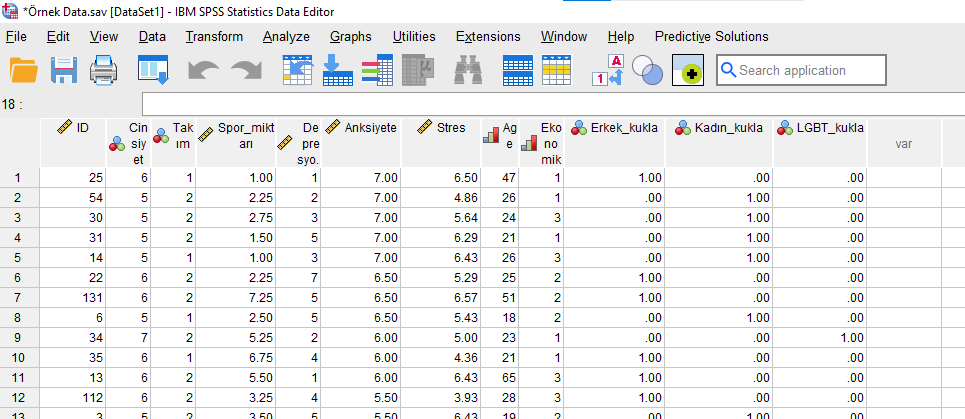
En sonunda, SPSS veri setimizde Erkek, Kadın ve LGBT için 3 yeni kukla değişken tanımlanmış halde olacak.
Erkek_kukla değişkeninde sadece erkekler 1 ile, Kadın_kukla değişkeninde sadece kadınlar 1 ile, LGBT_kukla değişkeninde sadece LGBT’ler 1 ile gösterilmektedir.

SPSS ile 3+ Kategori İçin Kukla Değişkenli Regresyon Nasıl Yapılır?
Bu örnekte, farklı cinsiyetlerde olmanın Depresyon skorlarını nasıl etkilediğini incelemek için Kukla Değişkenli Regresyon Analizi yapacağım.
Bunun için önce 3 grubun ortalama skorlarını önden kontrol edip, sonra kukla değişkenli regresyon analizini yapacağım. Önden ortalama skorlara bakınca ona göre regresyon analizde referans kategorisini belirlemiş olacağım ve kukla değişkenli regresyon analizini ona göre yapacağım.
Ön Kontrol – Ortalama Skorları İnceleyelim
Regresyon analizine başlamadan önce kısaca göstereceğim bu işlemi yapmayıp direkt regresyon analizini yapmaya geçsek de olur aslında, ama hangi kategoriyi referans kategorisi olarak alacağınıza karar veremediyseniz bu işlemi yapıp önden ortalama skorları görmenizi ve ona göre referans kategoriyi belirlemenizi öneririm. Ayrıca, regresyon analizi sonuçlarını daha kolay okuyup yorumlamamızı sağlayacak bu işlem.
Şimdi, kukla değişkenli regresyon analizini daha kolay yorumlayabilmemiz için, hızlıca cinsiyetlerin Depresyon skoru puan ortalamalarını inceleyelim.
Analyze -> Compare Means -> Means
Açılan kutuda bağımlı değişkenimiz olan Depresyon’u Dependent List kutucuğuna atıyoruz. Bağımsız değişken olan Cinsiyet’i de (kukla olmayan, orijinal halini) Independent List kutucuğuna atıyoruz. Sonra “OK”a basıp analizi başlatıyoruz.
SPSS bize ufak bir Report tablosu verecek. Bu tabloda Kadın, Erkek ve LGBT cinsiyetlerinin ortalama skorlarını Mean sütununda görebiliriz.
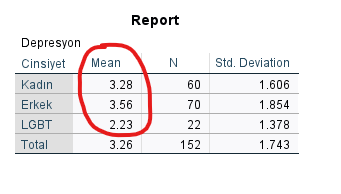
Erkek cinsiyetinin Depresyon ortalamasının en yüksek olduğunu bulduk. Regresyon yaparken bunu referans kategorisi alabiliriz o zaman.
Yani regresyon analizinde Erkek cinsiyetini referans kategori olarak alırsak Kadın ve LGBT cinsiyetlerini Erkek’ler ile karşılaştıracağız demek oluyor.
SPSS ile Kukla Değişkenli Regresyon Analizi Yapmak
Şimdi SPSS’te kukla değişkenli regresyon analizimize başlayalım.
Analyze -> Regression -> Linear
Kukla değişkenli regresyon analizinde eğer 2’den fazla kategoriye sahip (3 veya daha fazla kategoriye sahip) bir kategorik değişken varsa, bu kategorilerden 1 tanesi referans kategorisi olarak alınmalıdır.
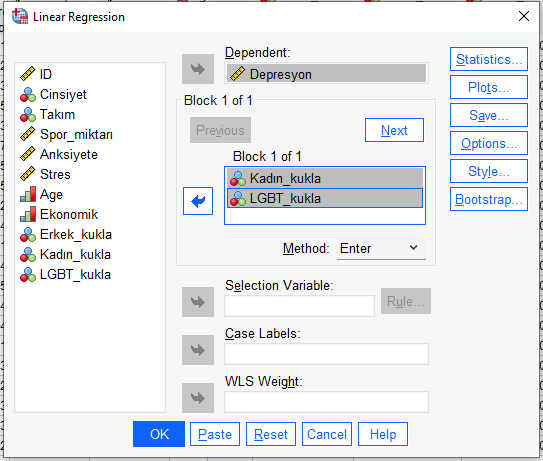
Ben demin Erkek cinsiyetinin ortalama Depresyon puanının en yüksek olduğunu bulduğum için, Erkek kategorisini referans olarak almaya karar verdim.
Bağımlı değişkeni Dependent kutusuna koyduktan sonra, referans kategorisi olan kategori hariç diğer Cinsiyet kategorilerini (Kadın ve LGBT) Independent(s) kutusuna atıyoruz.
Statistics butonuna basıyoruz. Aşağıdaki resimdeki işaretli seçenekleri işaretliyoruz.

“Continue” ve “OK”a basarak analizi başlatabiliriz.

3+ Kategori Kukla Değişken Regresyon SPSS Tablo Yorumlama
SPSS kukla değişkenli regresyon analizi sonucunda bize birtakım tablolar verecek.
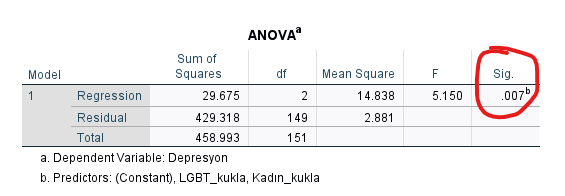
ANOVA Tablosu
“ANOVA” tablosundaki Sig. sütununda bulunan p değerine bakarsak, regresyon modelimizin Depresyon skorlarını anlamlı şekilde açıklayıp açıklamadığını görebiliriz. Bizim örneğimizde Sig. yani p değeri 0.007 çıkmış, yani Cinsiyet değişkeni Depresyon skorunu anlamlı olarak açıklayabiliyormuş demek.
Model Summary Tablosu
“Model Summary” tablosundaki Adjusted R Square değeri 0.52, yani Cinsiyet’in Depresyon skorundaki değişimi açıklama oranı %5.2 demek oluyor. Depresyon skorundaki diğer %94.8 değişim başka sebeplerden veya şans eseri oluyor demektir bu.

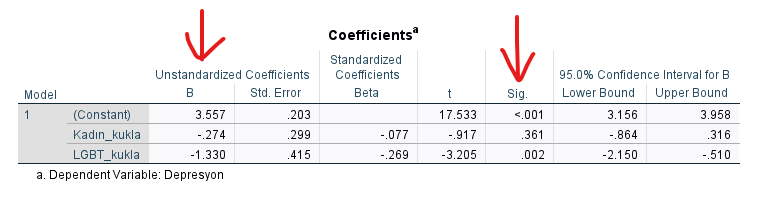
Coefficients Tablosu
En önemli tablo olan “Coefficients” tablosuna bakalım. Bu tabloyu doğru yorumlamak çok önemli. Bu örnekteki kukla değişkenli regresyon analizinde referans kategorimizin Erkek olduğunu unutmayalım.
“Coefficients” tablosundaki Sig. sütununda bulunan p değerlerine bakmalıyız önce.
- Kadın kategorisinin Sig. yani p değeri 0.05’in üzerinde çıkmış (p = 0.361). Demek ki Erkek yerine Kadın cinsiyetinde olmak, Depresyon skorlarını anlamlı olarak etkilemiyormuş.
- LGBT kategorisinin Sig. yani p değeri 0.05’in altında çıkmış (p = 0.002). Demek ki Erkek yerine LGBT cinsiyetinde olmak, Depresyon skorlarını anlamlı olarak etkiliyormuş.
Yine bu aynı tablodaki B değerine bakarsak, şöyle yorumlayabiliriz: “Erkek yerine LGBT cinsiyetinde olmak, Depresyon skorunda 1.330’luk bir düşüşe karşılık gelmektedir.”
Çok karışık olmayan bir 3+ kategorili kukla değişken (dummy variable coding) regresyon analizi bu kadardı. Bu regresyon analizinde yalnızca kukla değişkenleri analize koyduk ve başka bağımsız değişkenleri (anksiyete, motivasyon vb) analize dahil etmedik. Başka bağımsız değişkenleri de analize dahil ederek aynı bir Çoklu Doğrusal Regresyon Analizi yapar gibi analiz yapıp sonuçları yorumlayabiliriz yine.
Ayrıca, mesela diğer Cinsiyet karşılaştırmalarıyla ilgileniyorsanız (mesela Kadın yerine LGBT olmanın Depresyon skorları üzerindeki etkisi), o zaman Erkek yerine Kadın cinsiyetini referans kategorisi olarak seçerek regresyon analizini yeniden çalıştırabilirsiniz. Bu sayfadaki adımları takip etmeniz yeterli.
Bir yanıt bırakın