
İçindekiler
Binary yani İkili Lojistik Regresyon, bir veya daha fazla bağımsız değişkenin ışığında, 2 sonuç kategorisine sahip bir bağımlı değişkenin sonuç kategorileri arasından hangisinin gerçekleşeceğini tahmin etmeye yarayan istatistiksel analiz yöntemidir. Bu yazıda, Binary Lojistik Regresyon Analizi’nin ne olduğundan ve SPSS programında nasıl yapılacağından bahsedeceğim.
Binary Lojistik Regresyon Nedir?
Binary (İkili) Lojistik Regresyon, bir veya daha fazla bağımsız değişkenin, yalnızca 2 kategoriye sahip olan kategorik yapıda bir bağımlı değişken üzerindeki tahmin edici etkisini incelemek için kullanılan bir istatistiksel yöntemdir.
Binary Lojistik Regresyon Analizi’nin amacı, bağımsız değişkenlerin değerlerine dayanarak bağımlı değişkenin belirli bir kategoriye ait olma olasılığını tahmin etmektir. Lojistik regresyon modeli, bağımsız değişkenlerin lineer kombinasyonunu 0 ile 1 arasında bir olasılık skoruna dönüştürmek için lojistik fonksiyonu (veya S şeklindeki sigmoid fonksiyonu) kullanır. Model daha sonra belirlenen bir eşik olasılığına dayanarak gözlemleri iki kategoriye ayırır ve her gözlemin hangi kategoride olmasını beklediğini tahmin eder.
Binary Lojistik Regresyon Analizi, risk faktörlerine bağlı olarak bir hastalığın gerçekleşme ihtimalini tahmin etme, bir müşterinin bankadan aldığı krediyi geri ödeyebilme ihtimalini belirleme gibi amaçlar için kullanılır. Bu gibi açıklayıcı değişkenlere dayanarak bir olayın meydana gelme olasılığını modelleme amacıyla tıp, ekonomi, sosyal bilimler ve pazarlama gibi çeşitli alanlarda yaygın olarak kullanılmaktadır.
Binary Lojistik Regresyon Analizi’nin Çoklu Doğrusal Regresyon Analizi’nden farkı şudur: Çoklu Doğrusal Regresyon Analizi’nde bağımsız ve bağımlı değişkenlerin sayısal veri tipinde olması gerekmektedir. Binary Lojistik Regresyon Analizi’nde ise, bağımlı değişkenin kategorik yapıda olması gerekmektedir ve yalnızca 2 kategoriye sahip olması gerekmektedir. Bağımsız değişkenler her tür veri tipinde olabilir; kategorik ya da sayısal veri tipinde olabilir.
Binary Lojistik Regresyon Analizi yapabilmemiz için bağımlı değişkenin yalnızca 2 kategoriye sahip bir kategorik veri olması şarttır.
Eğer bağımlı değişken 3 veya daha fazla kategoriye sahip bir kategorik veri ise, Binary Lojistik Regresyon yerine Multinominal Lojistik Regresyon Analizi yapmak gerekir.
Binary Lojistik Regresyon Analizi’nde bağımlı değişkenin kategorileri genellikle “Evet – Hayır”, “Başarı – Başarısızlık”, “Sağlıklı – Hasta” gibi olur. Bu kategoriler genellikle “0 – 1” şeklinde kodlanır; genellikle “0” hayır/başarısızlık gibi olumsuz kategoriyi, “1” ise evet/başarı gibi olumlu kategoriyi temsil eder. (Analizin yapılabilmesi için sayı kodlamasının illa 0-1 olmasına gerek yoktur, 1-2 de olabilir.)

Binary Lojistik Regresyon İçin Veriler Nasıl Olmalıdır?
- Yalnızca 1 adet bağımlı değişken olmalıdır.
- Bağımlı değişken yalnızca 2 kategoriye sahip olmalıdır. (mesela evet-hayır ya da hasta-sağlıklı)
- Bağımsız değişkenler 1 veya daha fazla sayıda olabilir.
- Bağımsız değişkenler kategorik yapıda veya sürekli sayısal yapıda olabilirler.
Eğer bağımlı değişken 2 kategoriye değil de 3 veya daha fazla kategoriye sahip ise (mesela telefon-bilgisayar-tablet tercihi) o zaman Binary Lojistik Regresyon yerine Multinominal Lojistik Regresyon analizi uygulamamız gerekir.
Hangi durumda hangi testi seçeceğinizden emin değilseniz “Hangi Test?” başlıklı yazımızı okuyarak doğru testi seçmeyi öğrenebilirsiniz.
Binary Lojistik Regresyon Varsayımları Nelerdir?
Binary Lojistik Regresyon Analizi, oldukça güçlü bir regresyon analizi türüdür. Öyle ki Binary Lojistik Regresyon Analizi yapabilmek için veride sağlanması gereken çok fazla varsayım yoktur. Örneğin bağımsız değişkenlerin kategorik, ordinal veya sürekli veri tipinde olması fark etmez hepsi analize dahil edilebilir. Yalnızca, bağımlı değişkenin 2 kategoriye sahip bir kategorik değişken olması şarttır.
Bunun dışında, sayısal veri tipinde birden fazla bağımsız değişken varsa, bu bağımsız değişkenlerin birbirleriyle çok yüksek korelasyon göstermemesi iyi olur, fakat bu olsa bile çok önemli bir sorun yaratmaz.
Binary Lojistik Regresyon Analizi’ne özel tek varsayım doğrusallık varsayımıdır. (Buna da fazla dikkat edilmez). Lojistik Regresyon Analizi’nde doğrusallık varsayımı, bağımsız değişkenlerin log-odds oranı (logit fonksiyonuyla bulunan) ile doğrusal bir ilişkiye sahip olmasıdır. Bu, analize dahil olan her bir sürekli bağımsız değişkenin, bağımlı değişkenin log-odds değerleri üzerinde sabit ve doğrusal bir etkiye sahip olması gerektiği anlamına gelir. Eğer bu ilişki doğrusal değilse (eğrisel ise), model tahminlerinde yanlılık oluşabilir ve isabetliliği azalabilir. Lojistik Regresyon Analizi’nin doğrusallık varsayımını nasıl test edeceğimizi ayrı bir sayfada anlatıyorum, tıklayıp okuyabilir ve okuduktan sonra buraya geri dönebilirsiniz.
SPSS ile Binary Lojistik Regresyon Nasıl Yapılır?
SPSS’te Binary Lojistik Regresyon Analizi nasıl yapıldığını aşağıda anlatıyorum. Bu sayfadaki örnekte, ihtiyacınız olabilecek bütün türlerde değişkenlere yer verdim. Sizin elinizde hangi tür veri olursa olsun, bu yazıyı sonuna kadar okursanız kendi Binary Lojistik Regresyon analizinizi doğru gerçekleştirebilmek için başka kaynağa bakmaya ihtiyacınız olmayacak.
Bu sayfadaki örnekte, her katılımcı için, gerçekleşebilecek 2 sonuçtan hangisinin gerçekleşmeye daha yakın olduğunu Binary Lojistik Regresyon Analizi yaparak bulmaya çalışacağız.
Analize başlamadan önce, bu örnekte çalışacağımız veri setini kısaca tanıtmak istiyorum. Bu, analizi nasıl yaptığımızı anlamanız için önemli.
Analizde, bir kişinin Cinsiyet, Mutluluk, Medeni Durum, ve Ekonomik Durumuna göre, seçimde Evet oyu mu yoksa Hayır oyu mu vermeye daha yakın olduğunu tahmin etmeye çalışacağım.

Değişkenlerin kodlanması şu şekilde:
- Cinsiyet -> Kategorik veri (5 = Kadın; 6 = Erkek)
- Mutluluk -> Sürekli veri (1’den 7’ye kadar)
- Medeni durum -> Kategorik veri (0 = Bekar; 1 = Evli)
- Ekonomik durum -> Kategorik veri (1 = Fakir; 2 = Orta; 3 = Zengin)
- Seçim -> Kategorik veri (1 = Evet; 2 = Hayır)
SPSS programında Binary Lojistik Regresyon analizi yapmaya Analyze -> Regression -> Binary Logistic düğmelerine basarak başlıyoruz.
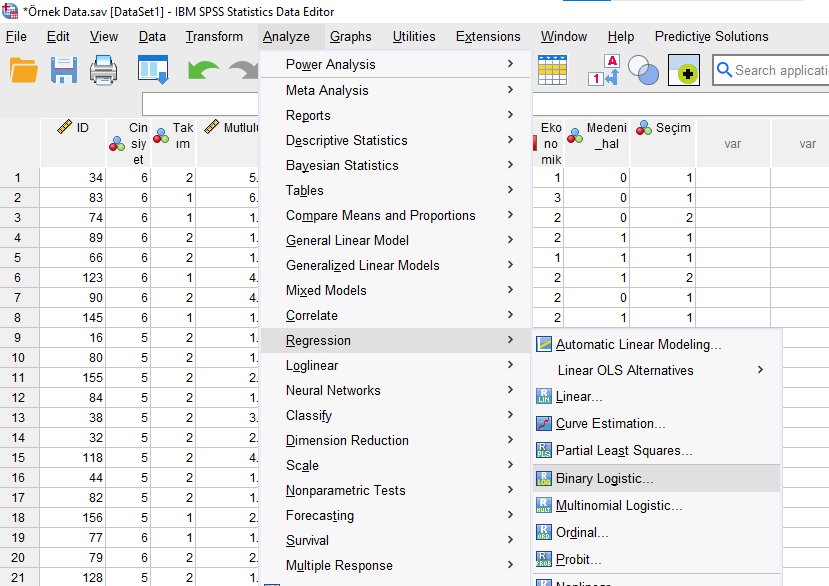
Bağımlı değişkenimizi Dependent kutusuna, bağımsız değişkenlerimizin hepsini Covariates kutusuna koyuyoruz. Hangi sırayla koyduğumuzun önemi yok.
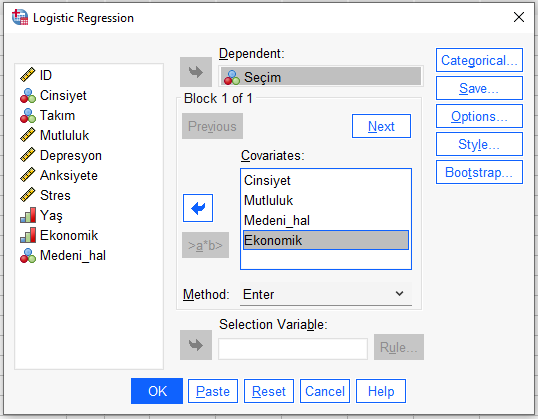
Categorical butonuna basıyoruz. SPSS o kadar da süper otomasyon bir program olmadığı için, kategorik yapıdaki verilerimizi “0 ile 1” formatına çevirip analiz etmesi için bizim ona burada talimat vermemiz gerekiyor. Bunu yapmazsak analiz sonucu hatalı olur.
Yukarıda veri setimizi hatırlarsak, Medeni Hal değişkeni Evli = 1, Bekar = 0 olarak kodlanmıştı. Bu zaten “0 – 1” formatında olduğu için SPSS’e yeniden kodlatmaya gerek yok. Fakat Cinsiyet ve Ekonomik Durum değişkenleri “0 – 1” şeklinde kodlanmamıştı.
Bunları SPSS’in analiz sırasında 0 ve 1 şeklinde kodlamasını sağlamamız gerek. Bu yüzden bu iki değişkeni alıyorum ve Categorical Covariates kutusuna koyuyorum. Reference Category olarak First seçersek, bu kategorilerdeki en küçük sayısal değere sahip olan kategori, referans kategorisi olarak sayılır yani SPSS analiz sonucunda “0” olarak geçer. Diğer değişken 1 olarak geçer. Bunu SPSS tablo çıktılarını aldıktan sonra tekrar göstereceğim.
Medeni Hal değişkeni zaten en baştan 0 ve 1 olarak kodlanmış olduğu için bunu bu adımda ellemeye gerek yok. Eğer baştan 0 ve 1 olarak kodlanmamış olsaydı bunu da aşağıda kutuya atardık.
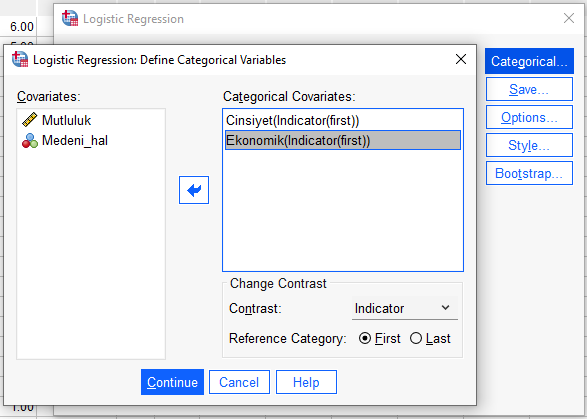
Daha sonra, Save’e basıyorum. Predicted Values kısmında, Probabilities ve Group Membership seçeneklerini işaretliyoruz.
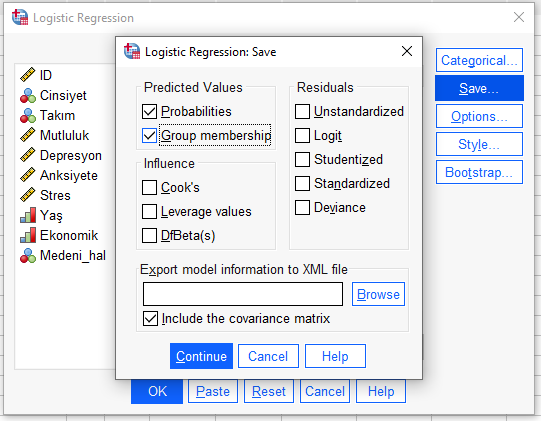
Options butonuna basıyoruz. “Hosmer-Lemeshow Goodness Of Fit” ve “CI For exp(B)” işaretliyoruz.
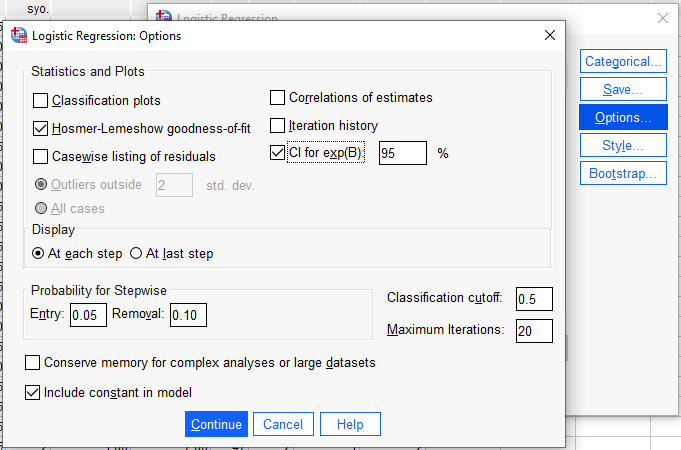
Artık sırasıyla Continue ve OK butonlarına basarsak SPSS bize Binary Lojistik Regresyon Analizi tablolarını sunacak.

Binary Lojistik Regresyon SPSS Tablo Yorumlama
Aşağıda, SPSS’in bize verdiği Binary Lojistik Regresyon tablolarında hangi yerlere bakmak gerektiğini anlatıyorum. Binary Lojistik Regresyon Analizi sonuçlarını yorumlarken büyük ihtimalle bunların dışında bir yere bakmanız gerekmeyecek.
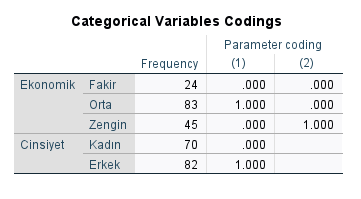
Öncelikle, hatırlarsanız demin SPSS’e Cinsiyet ve Ekonomik Durum kategorik değişkenlerimizi 0 ve 1 olarak kodlatmıştık. Bunu aşağıdaki “Categorical Variables Codings” başlıklı tabloda görebiliriz.
Cinsiyet olarak, artık Kadın = 0; Erkek = 1 şeklinde kodlanmış bulunuyor.
Ekonomik Durum değişkeni için ise 2 sütunda 2 farklı kodlama şekli görüyoruz çünkü bu değişken 3 kategoriye sahip. Fakir grubunu demin First seçerek referans değeri olarak belirlemiş olduğumuz için Fakir grubunun kodu hep 0 değerinde. (Eğer Last seçmiş olsaydık Zengin kategorisi hep 0 değerinde olacaktı.) Bir kodlama şeklinde Fakir = 0; Orta = 1 sayılmış, diğer kodlama şeklinde Fakir = 0; Zengin = 1 sayılmış. Yani birinde Orta gelirli katılımcılar ile Fakir katılımcılar karşılaştırılıyor, diğerinde ise Zengin katılımcılar ile Fakir katılımcılar karşılaştırılıyor. (Orta gelirliler ile Zengin katılımcılar hiç karşılaştırılmıyor)
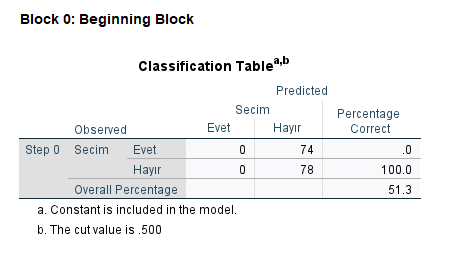
Block 0 başlıklı bölümdeki “Classification Table” başlıklı tabloda, eğer hiçbir istatistiksel tahmin modelimiz olmasaydı, kimin hangi oyu vereceğini rastgele seçseydik, yüzde kaç oranında doğru bileceğimizi görüyoruz. Genelde %50’ye yakın bir değer çıkar burası. Çok da önemli değil bu tablo.
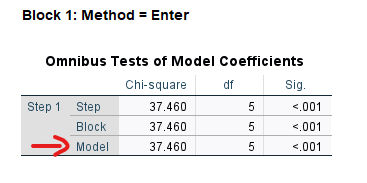
Block 1 bölümüyle birlikte başlayan tablolar daha önemli. Aşağıdaki tablodaki “Model” satırındaki Sig. değeri p değerini gösteriyor, yani yaptığımız Binary Lojistik Regresyon Analizi’nin istatistiksel olarak anlamlı bir sonuç verip vermediğini söylüyor. Eğer p değeri 0.05’ten küçük ise anlamlı demektir. Biz p < 0.001 bulduk, yani bu demek oluyor ki, kurduğumuz Lojistik Regresyon modeline göre bağımsız değişkenlerimizden oluşan analiz modelimiz, bağımlı değişken olan Seçim’deki Evet veya Hayır verme ihtimalini anlamlı olarak doğru tahmin etmeye yarıyor.
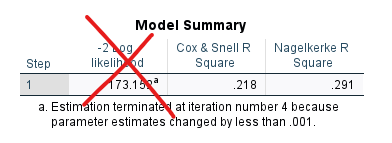
“Model Summary” tablosunda, modelimizin Seçim’deki Evet-Hayır tercihini ne düzeyde tahmin ettiği hakkında bir fikir sahibi olmamıza yardımcı olan değerler görüyoruz. İki tane R Square değeri görüyoruz. Bu değerler, Doğrusal (Lineer) Regresyon Analizi modellerinde kullandığımız R Kare ve Düzeltilmiş R Kare değerlerinin bir analojisi olarak düşünülebilir. İkisinin hesaplanma yöntemleri farklıdır ve ikisi de doğrusal regresyon analizindeki R Kare değeriyle tam olarak aynı şey değildirler.
Doğrusal Regresyon Analizi’ndeki R Kare (R Square) değeri, bağımlı değişkendeki değişkenliğin yüzde kaçının bağımsız değişkenlerle açıkladığını belirtiyordu. Mesela, eğer Doğrusal Regresyon Analizi sonucunda R Kare değerini 0.418 olarak bulursak, bu, o regresyon modelindeki bağımsız değişkenlerin bağımlı değişkendeki değişimin %41.8’ini açıkladığını gösteriyordu.
Fakat Lojistik Regresyon Analizi’ndeki Cox & Snell R Square ve Nagelkerke R Square değerleri, tam olarak bu anlama denk değildirler, çünkü hesaplanma biçimleri R Kare’den farklıdır. Ayrıca Cox & Snell R Square değeri nadir de olsa 1’den büyük olabilir. Nagelkerke R Square ise, Cox & Snell R Square değerinin 0 ile 1 arasında olacak şekilde modifiye edilmiş versiyonudur.
Akademik çalışmalarda istatistiksel analiz sonuçları raporlanırken “Cox & Snell R Square değerine göre modelimiz Seçim tercihindeki değişimin %21.8’ini açıklıyor” veya “Nagelkerke R Square değerine göre modelimiz Seçim tercihindeki değişimin %29.1’ini açıklıyor” şeklinde yorumlar yazılarak raporlanıyor bu değerler. Bu aslında matematiksel olarak yanlış, fakat herkes böyle yaptığı için siz de böyle yapabilirsiniz herhalde.
“Hosmer and Lemeshow Test” tablosunda, Sig. sütununda 0.05’ten büyük bir p değeri çıkmasını istiyoruz. Eğer böyle ise “Lojistik Regresyon modelimiz verimize iyi uyum sağlıyor” demektir.
Hosmer-Lemeshow testi, bir lojistik regresyon analizi modelinin uyum iyiliğini değerlendirmek için kullanılan bir istatistiksel testtir. SPSS’te, Hosmer-Lemeshow testi sonucu bulduğumuz p değeri, testin anlamlılık düzeyini gösterir. 0.05’ten küçük bir p değeri lojistik regresyon modelinin veriye iyi uyum sağlamadığını gösterirken, 0.05’ten büyük bir p değeri modelin veriye iyi uyum sağladığını işaret eder.

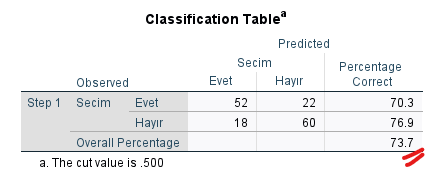
“Classification Table” tablosunda, SPSS’in oluşturduğu lojistik regresyon modelinin, katılımcıların yüzde kaçının Seçim’deki Evet veya Hayır tercihini doğru bildiğini gösteren verileri görebiliriz. “Observed” bölümü gerçek değeri, “Predicted” bölümü modelin tahmin ettiği değeri gösterir.
- Bu örnekte, SPSS Seçim’de Evet oyu veren 74 kişinin 52’sinin Evet oyu vereceğini doğru tahmin etmiş, fakat 22’sinin Hayır oyu vereceğini tahmin etmiş (yani yanlış tahmin etmiş). SPSS’in tahminlerinin %70.3’ü doğruymuş.
- Benzer şekilde, SPSS Seçim’de Hayır oyu veren 78 kişinin 60’ının Hayır oyu vereceğini doğru tahmin etmiş, fakat 18’inin Evet oyu vereceğini tahmin etmiş (yani yanlış tahmin etmiş). SPSS’in tahminlerinin %76.9’u doğruymuş.
Bütün veriyi topluca ele alırsak, SPSS’in kurduğu lojistik regresyon modeline göre yaptığı tahminlerin %73.7’si doğruymuş. Baştaki, rastgele tahmin yaparsak yüzde kaçını doğru bileceğimizi söyleyen modelde tahminlerimizin %51.3’ü doğru çıkıyordu. Lojistik Regresyon Analizi sonucu kurduğumuz modelde, doğru tahmin oranımız %51.3’ten %73.7’ye çıktı ve bu istatistiksel olarak anlamlı bir yükseliş (çünkü yukarıda Model’in p değerini 0.05’ten küçük bulmuştuk).
“Variables in the Equation” tablosu en önemli tablo. Burayı doğru yorumlamak çok önemli, hangi değişkenlerin sonucu nasıl etkilediğini bu tabloya bakarak öğrenebiliyoruz. Yorumlamak biraz uzun ama çok zor değil.
Sırayla satır satır yorumlayarak gideceğim.
Öncelikle hatırlayalım ki Seçim tercihleri, bizim verimizde 1 = Evet; 2 = Hayır olarak kodlanmıştı.
Binary Lojistik Regresyon Analizi sonuçları “küçük sayılı kategori yerine büyük sayılı kategorinin gerçekleşme ihtimali” şeklinde okunmaktadır. Yani bu analiz örneğinde analiz sonuçları “1 yerine 2 olma ihtimali” yani “Evet oyu vermek yerine Hayır oyu vermiş olma ihtimali” üzerinden yorumlanıyor.
(Bağımlı değişken bunun yerine 1=Evet; 0=Hayır şeklinde kodlanınca anlaması çok daha kolay oluyor çünkü o zaman “Hayır yerine Evet olma ihtimali” olarak yorumlanırdı yani direkt “olma ihtimali” olarak yorumlanmış olurdu. Ben bu örnekte bağımlı değişkeni evet-hayır 1-2 diye kodladım da siz evet-hayır 1-0 olarak kodlayın, sonuçları yorumlamanız çok daha kolay olur.)
Cinsiyet
Cinsiyet değişkeninin Sig. yani p değeri 0.001’den küçük çıkmış. Yani p değeri 0.05’ten küçük olduğu için istatistiksel olarak anlamlı bir sonuca işaret ediyor. Cinsiyet kategorik bir değişken. Yukarıdan hatırlarsak Kadın = 0; Erkek = 1 olarak yeniden kodlamıştık.
B değeri pozitif. B değeri sadece doğrusal bir fonksiyonda işe yarayan bir katsayıdır. Fakat lojistik regresyon doğrusal bir fonksiyon değil. Bu yüzden B değerini Exp(B) diye başka bir katsayıya çevirip onu yorumlamak gerekiyor. O yüzden biz B yerine Exp(B) değerine bakıp yorumlama yapacağız. Cinsiyet’in Exp(B) değeri 8.695’miş.
Exp(B), bir lojistik regresyon modelinin B katsayısının üstel fonksiyonunu ifade eder. Bu, bir birimlik değişikliğin olasılık oranındaki (Odds Ratio) etkisini temsil eder. Bu yüzden Exp(B) değeri için Odds Ratio terimi de kullanılmaktadır.
Cinsiyet ve Seçim tercihini hangi sayılarla kodladığımızı hatırlarsak, şöyle bir sonuca varabiliriz: “Kadın yerine Erkek olmak, seçimde Evet yerine Hayır oyu verme ihtimalini 8.695 kat arttırıyor. Yani Erkek olmak Hayır oyu verme ihtimalini %869.5 arttırıyor.”
B değeri pozitif ise Exp(B) değeri her zaman 1’den büyük olur, B değeri negatif ise Exp(B) değeri her zaman 1’den küçük olur.
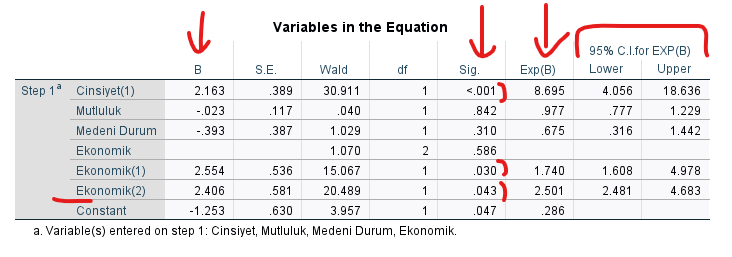
Tablonun en sağında Exp(B) değeri için %95 güven aralığını belirten sayılar var. Soldaki sütun o değişken için olabilecek en düşük Exp(B) değerini, sağdaki sütun da en yüksek Exp(B) değerini gösteriyor. Eğer Sig. sütununda gösterilen p değeri 0.05’ten küçük ise, “%95 CI for Exp(B)” bölümündeki değerlerin ya ikisi de negatif olur, ya da ikisi de pozitif olur. Değerlerin arasına hiçbir zaman “0” sayısı girmez.
Mutluluk
Mutluluk değişkeninin Sig. yani p değeri 0.842 çıkmış. Yani mutluluğun seçimde Evet ya da Hayır oyu verme üzerindeki tahmin edici etkisi istatistiksel olarak anlamlı değil. Bu yüzden normalde bu değişken için tabloyu daha fazla okumaya gerek yok.
Fakat örnek göstermek açısından, eğer istatistiksel olarak anlamlı bir p değeri çıksaydı nasıl olurdu yorumlayalım.
(Hatırlarsak başta Seçim oy tercihi Evet = 1; Hayır = 2 kodlamıştık.)
Yine Exp(B) değerine bakıyoruz. Exp(B) değeri 0.977 çıkmış, B değeri de negatif. Bu şu anlama gelirdi: “Mutluluk puanı arttıkça, Hayır oyu verme oranı azalıyor”. Sayısal olarak detaylıca şöyle yorumlayabiliriz: “Mutluluk’ta eğer 1 puanlık artış meydana geliyor ise, bir katılımcının Evet yerine Hayır oyu verme ihtimali, ilk baştaki ihtimalin %97.7’si kadar oluyor.”
Mutluluk’ta eğer 2 puanlık artış meydana geliyorsa Hayır oyu verme ihtimali, en baştaki ihtimalin %97.7’sinin %97.7’si kadar oluyor yani en baştaki ihtimalin %94.1’i kadar oluyor.
1 – 0.977 = 0.023 yapar diye bir hesap yaparak aynı sonucu farklı kelimelerle de anlatabiliriz: “Mutluluk puanındaki her 1 puanlık artış, bir kişinin seçimde Hayır oyu verme ihtimalini önceki ihtimale göre %2.3 azaltıyor”.
Medeni Durum
Mutluluk değişkeninin Sig. yani p değeri 0.310 çıkmış. Yani sonuç istatistiksel olarak anlamlı değil. Bu yüzden normalde bu değişken için tabloyu daha fazla okumaya gerek yok.
Fakat örnek göstermek açısından, eğer istatistiksel olarak anlamlı bir p değeri çıksaydı nasıl olurdu yorumlayalım.
Medeni Durum en başta 0 = Bekar; 1 = Evli olarak kodlanmıştı. Seçim de 1 = Evet; 2 = Hayır olarak kodlanmıştı.
Exp(B) değeri 0.675 ve B değeri negatif. Şöyle yorumluyoruz: “Bekar yerine Evli olmak, seçimde Hayır oyu verme ihtimalini baştaki ihtimalin %67.5’u kadar yapıyor.”
1 – 0.675 = 0.325
Başka bir deyişle: “Evli olmak, Hayır oyu verme ihtimalini %32.5 oranında azaltıyor.”
Ekonomik Durum
Ekonomik Durum, 3 farklı değer alabilen bir kategorik değişken olduğundan dolayı (Fakir – Orta – Zengin) Fakir’i referans kategorisi olarak ayarlayıp Orta ile ve Zengin ile karşılaştırdığımız 2 tane farklı model oluşturmamız gerekmişti.
1. modele bakarsak, Sig. yani p değeri 0.030 yani istatistiksel olarak anlamlı. 1. modelde Fakir = 0; Orta = 1 diye kodlamıştık. Exp(B) değerine bakarsak, diyebiliriz ki “Fakir yerine Orta Gelirli olmak, seçimde Hayır oyu verme ihtimalini %74 arttırarak %174’e çıkartıyor”.
2. modele bakarsak, Sig. yani p değeri 0.043 yani istatistiksel olarak anlamlı. 2. modelde Fakir = 0; Zengin = 1 diye kodlamıştık. Exp(B) değerine bakarsak, diyebiliriz ki “Fakir yerine Zengin olmak, seçimde Hayır oyu verme ihtimalini %150.1 arttırarak %250.1’e çıkartıyor”.
Not: Burada maalesef Orta ekonomik durumdan Zengin ekonomik duruma geçmek Hayır oyu verme ihtimalini ne kadar arttırıyor direkt olarak göremiyoruz. Bunu görebilmek için Orta’yı referans kategorisi olarak ayarlayıp yeniden aynı lojistik regresyon analizini yapmalıyız. Ancak o zaman görürüz.
Sonuç olarak, diyebiliriz ki “Cinsiyet Erkek olunca ve Ekonomik Durum iyileştikçe seçimde Hayır oyu verme ihtimali istatistiksel olarak anlamlı bir şekilde artıyor.” Her biri için ne kadar arttığını da yukarıda söyledik.
Bonus: Veri Seti Üzerinde Tahminleri Görme
Binary Lojistik Regresyon Analizi yapıp SPSS’in verdiği sonuç tablolarını yorumlama işlemi bu kadardı. Buradan itibaren anlattığım aşağıdaki kısım analiz raporlama için bilmek gereken bir şey değil. Sadece bonus bilgi.
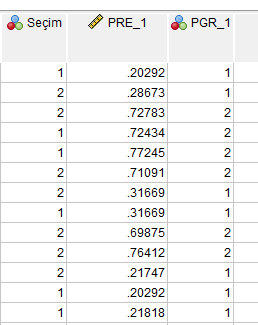
Son olarak, SPSS’teki veri setimiz üzerinde bir şeyi daha göstermek istedim. Analizi ilk yaparken analiz penceresinde “Save” butonuna basarak “Predicted Values” kısmındaki “Probabilities” ve “Group Membership” seçeneklerini işaretlemiştik. Bu, SPSS veri setimizde en sağdaki sütunun sağında iki yeni sütunda iki yeni değişken oluşmasına sebep oldu: PRE_1 ve PGR_1. Bu iki değişkene bakarak, SPSS’in, veri setimizdeki her katılımcı için bir değer hesaplayıp o değere göre o katılımcının hangi grupta olduğunu (hangi oyu verdiğini) nasıl tahmin ettiğini görebiliyoruz.
- PRE_1 = Predicted Value yani Tahmini Değer
- PGR_1 = Predicted Group Membership yani Beklenen Grup
Her satırda, SPSS o katılımcının Cinsiyet, Mutluluk, Medeni Durum ve Ekonomik Durum değerlerine göre bir tahmini değer hesaplıyor. O değere göre de o katılımcının Evet mi Hayır mı oy vermesi gerektiğini tahmin ediyor (Evet = 1; Hayır = 2).
Predicted Value (PRE_1) değeri 0.50’den küçükse Predicted Group (PGR_1) otomatikman 1 olur; Predicted Value (PRE_1) değeri 0.50’den büyükse Predicted Group (PGR_1) otomatikman 2 olur.

Aşağıya deminki görselin biraz daha büyük halini koydum.
Seçim sütununda her katılımcının gerçekte verdiği oy görünüyor. PGR_1 sütununda ise SPSS’in o katılımcının hangi oyu verdiğini tahmin ettiği görünüyor.
Örneğin 1. satırda katılımcı Evet oyu vermiş. SPSS de o kişinin incelediğimiz dört bağımsız değişkeninin durumuna bakarak o kişinin Evet oyu verdiğini tahmin etmiş. Doğru tahmin etmiş.
2. satırda katılımcı Hayır oyu vermiş. SPSS o kişinin incelediğimiz dört bağımsız değişkeninin durumuna bakarak o kişinin Evet oyu verdiğini tahmin etmiş. Yanlış tahmin etmiş.
Örneğin 3. satırda katılımcı Hayır oyu vermiş. SPSS de o kişinin incelediğimiz dört bağımsız değişkeninin durumuna bakarak o kişinin Hayır oyu verdiğini tahmin etmiş. Doğru tahmin etmiş.
Yukarıda SPSS’in verdiği ilk sonuç tablolarından hatırlarsak, SPSS’te oluşturduğumuz Lojistik Regresyon modeline göre bağımsız değişkenlerin değerlerine göre bağımlı değişkenin kategorisini doğru tahmin etme oranı %73.7’ydi. Bu şekilde, verimizdeki herkes için SPSS’in yaptığı tahminlerin doğruluğunun oranına bakarsak, bütün katılımcılar için toplam tahminlerin %73.7’sinin doğru olduğunu görebiliriz.
SPSS programında Binary Lojistik Regresyon Analizi yapması ve sonuçlarını yorumlaması bu kadardı. Artık yaptığımız analizi raporlama işlemini yapabiliriz. Yazıyı baştan sona okuduysanız, analiz yapma ve yorumlama kısmında hiçbir sorun yaşamıyor olmanız lazım.
Eğer buradaki gibi 2 kategoriye sahip olan değil de 3 veya daha fazla kategoriye sahip olan bir bağımlı değişkenin kategorilerini tahmin etmek nasıl yapılıyor merak ediyorsanız bunun için Multinominal Lojistik Regresyon (Multinomial Logistic Regression) yapmanız gerekmekte. Bu analizi öğrenmek için de “SPSS ile Multinominal Lojistik Regresyon Analizi” yazımızı linke tıklayarak okuyabilirsiniz. Şimdilik görüşmek üzere.
Bir yanıt bırakın