
İçindekiler
Uyum Analizi (Correspondence Analysis), 2 tane kategorik değişkenden oluşan veri setlerindeki değişkenlerin kategorileri arasındaki ilişkileri bir grafik üzerinde görselleştirmek için kullanılan bir istatistiksel yöntemdir. Bu blog yazısında, Uyum Analizi’nin ne olduğunu, neden yapıldığını, ve SPSS kullanarak nasıl Uyum Analizi yapılacağını adım adım göstereceğim.
Uyum Analizi (Correspondence Analysis) Nedir?
Uyum Analizi (Correspondence Analysis), veri analizi ve görselleştirmede sıklıkla kullanılan bir kategorik veri analizi yöntemdir. Bu yöntem, özellikle kategorik verilerin analizinde kullanılır ve değişkenler arasındaki ilişkileri görsel olarak açıklamak için etkili bir araçtır.
Mesela, elimizde her araba satışına ait araba modelinin ve hangi kıtada satış yapıldığının verisi varsa, hangi araba modelinin hangi kıtada daha çok satıldığını görselleştirmek için Uyum Analizi yapabiliriz.
Uyum Analizi (Correspondence Analysis), yalnızca 2 tane kategorik değişkenin birbiriyle ilişkisini görmek için kullanılır. Değişkenlerin kaçar kategoriye sahip olduğu fark etmez.
Eğer 2’den fazla kategorik değişkenin, veya kategorik değişken değil de sürekli (devamlı) veri tipine sahip değişkenlerin (veya nesnelerin) arasındaki benzerlik ve farklılıkları iki boyutlu bir düzlemde görselleştirmek istiyorsanız, Uyum Analizi yerine Çok Boyutlu Ölçekleme analizi uygulamanız gerekmektedir. Onun için ayrı yazdığım Çok Boyutlu Ölçekleme makalesini okuyabilirsiniz.
Uyum Analizi, öncelikle tablo şeklinde sunulan kategorik verilerdeki ilişkileri incelemek ve bu ilişkileri daha kolay anlaşılır hale getirmek için kullanılır. Örneğin, anket verileri veya pazar araştırmalarından elde edilen kategorik veriler (örneğin cinsiyet ve ürün tercihi gibi tüketici tercihleri) üzerinde çalışırken sıkça başvurulan bir yöntemdir.
Uyum Analizi, veri setindeki değişkenler arasındaki ilişkileri temsil etmek için bir grafik oluşturur. Bu grafik genellikle bir “harita” şeklinde yorumlanabilir. Analiz sonucunda, değişkenler arasındaki ilişkilerin doğası ve değişkenlerin birbirleriyle nasıl ilişkili olduğu görsel olarak ortaya konur. Böylece, veri setindeki kategorik yapıların anlaşılması ve yorumlanması kolaylaşır.
Uyum Analizi’nin, Ki-Kare veya Log-Lineer Analiz gibi kategorik veri analizi yöntemlerinden farkı, birbiriyle yakın ilişkiye sahip kategorileri bir grafik üzerinde göstermesi, yani analiz sonuçlarını görselleştirmesidir.
Aşağıdaki Uyum Analizi grafiğinde birbirine yakın olan noktalar birbirleriyle yakın ilişkiye sahip, birbirine uzak olan noktalar birbiriyle daha az ilişkili demektir.
Uyum Analizi’nin avantajları arasında, çok değişkenli verilerdeki karmaşıklığı basitleştirmesi ve veri setindeki desenleri anlama kolaylığı yer alır. Bu yöntem, pazarlama, sosyal bilimler, biyoloji ve diğer disiplinlerde kullanılan kapsamlı ve güçlü bir analiz aracıdır. Veri setindeki değişkenlerin ilişkilerini keşfetmek ve yorumlamak isteyen araştırmacılar için önemli bir bilgi sağlar.

SPSS ile Uyum Analizi (Correspondence Analysis) Nasıl Yapılır?
Aşağıdaki adımları izleyerek, SPSS’te kolayca Uyum Analizi (Correspondence Analysis) gerçekleştirebilirsiniz. Başlayalım.
Bu örnekte, değişik vücut bakımı ürünleri, değişik kokular ve hangi kokulu hangi üründen kaç kişinin satın aldığının bilgisi var. Biz bir üretici firmayız ve pazar araştırması yapıyoruz. Hangi vücut bakımı ürünlerinin hangi kokularla daha yakın ilişkili olduğunu Uyum Analizi yaparak bulursak, o ürünlerin o kokulu versiyonlarını daha fazla üretiriz. Bunun için Uyum Analizi yapacağız.
Verimiz SPSS’te aşağıdaki gibi görünmekte.
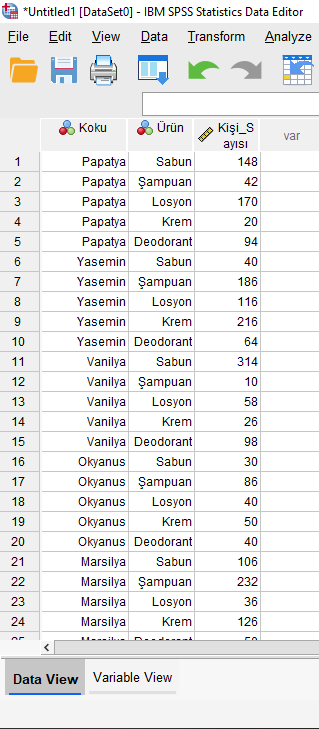
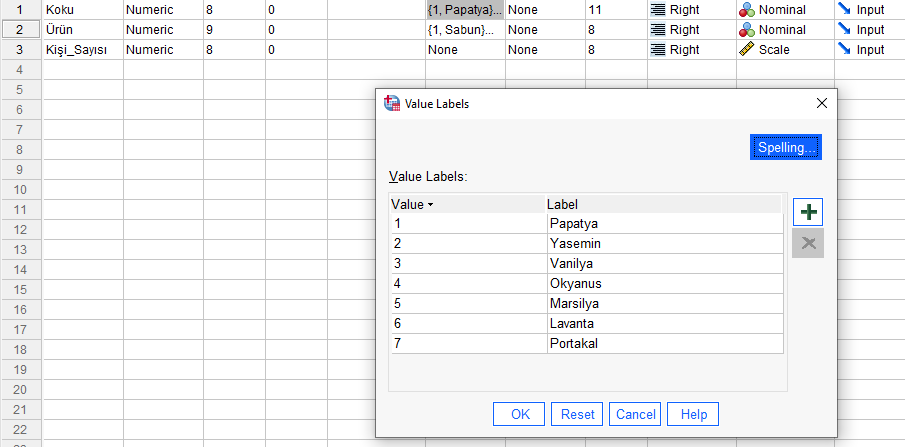
Koku olarak 7 farklı çeşit Koku var, SPSS’te nasıl kodlamış olduğumuzu aşağıda görebilirsiniz.
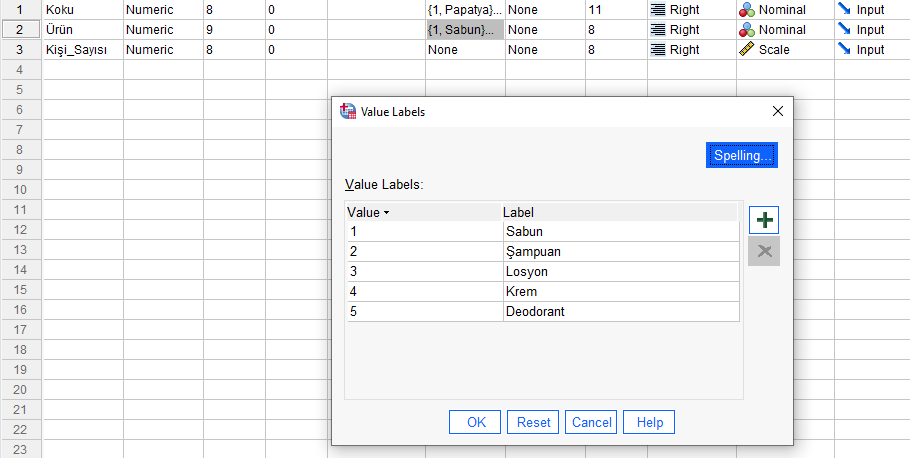
Ürün olarak 7 farklı çeşit Ürün var, SPSS’te nasıl kodlamış olduğumuzu yine aşağıda görebilirsiniz.
Verimizi SPSS’te her satırda 1 kişi olacak şekilde girmiş olsaydık, direkt olarak Uyum Analizi’ne başlayabilirdik. Ama bu örnekte “her koku ve her ürün için onu kaçar kişi aldığının” bilgisini girmiş bulunduk. Bunu, SPSS analizine hazır hale getirmek için SPSS’teki Weight Cases fonksiyonunu kullanmamız gerekiyor.
Data -> Weight Cases
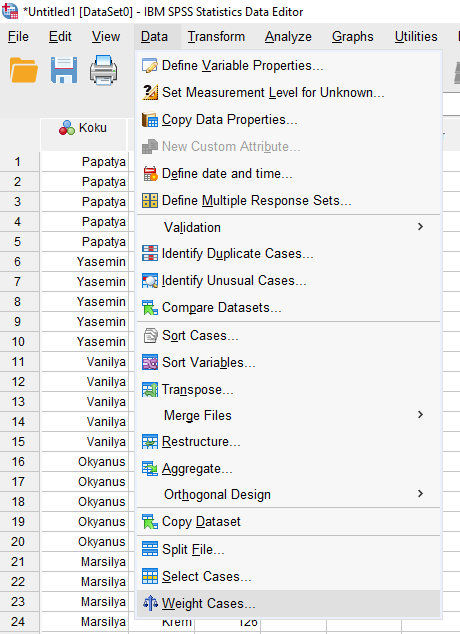
Açılan pencerede, “Weight cases by” işaretleyip Kişi Sayısı değişkenini Frequency Variable kutusuna atıyoruz. Sonra OK’a basıyoruz.
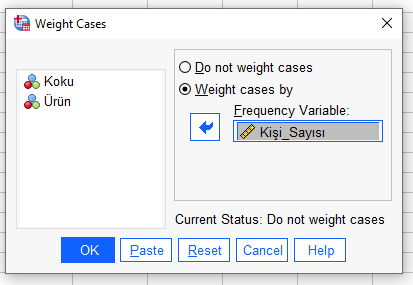
Artık verimiz Uyum Analizi’ne hazır.
Analyze -> Dimension Reduction -> Correspondence Analysis
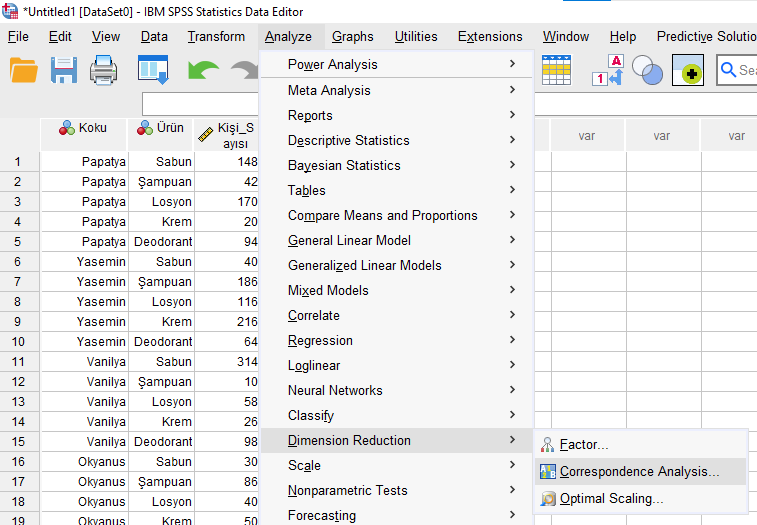
Açılacak kutuya kategorik değişkenlerimizi ekliyoruz. Sonra, her değişken için, “Define Range”e basıyoruz.
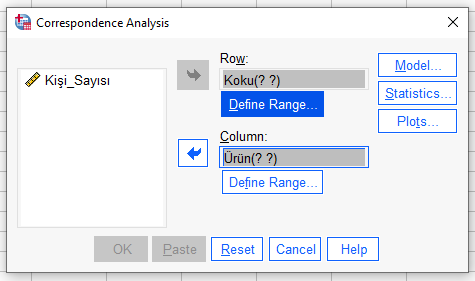
O değişkeni minimum ve maksimum hangi sayılarla kodlamış bulunduysak, o sayıları yazıp “Update” butonuna basıyoruz, sonra da “Continue”ya basıyoruz.
Mesela Koku değişkeni 1’den 7’ye kadar numaralarla kodlanmıştı.
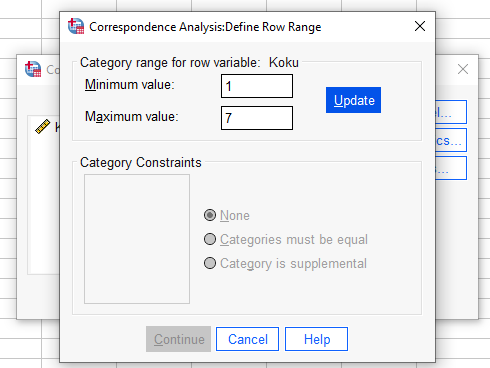
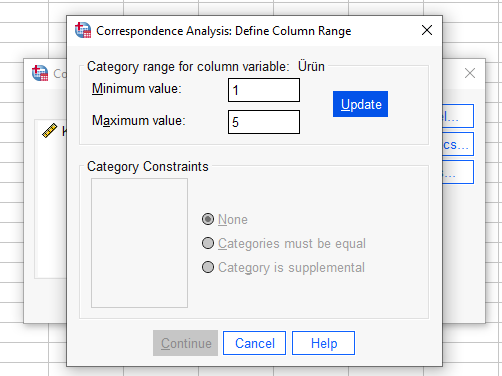
Aynı işlemi Ürün için de yapıyoruz. Bizim verimizde 1’den 5’e kadar 5 tane ürün olduğu için minimum 1 maksimum 5 yazıyoruz.
Sonra, “Plots” butonuna basarak, “Row points” ve “Column points” seçeneklerini de işaretliyoruz. Bunlar, her değişkenin kendi içinde kategorilerinin birbirlerine göre yakınlık-uzaklığını görmemize yarayacak.
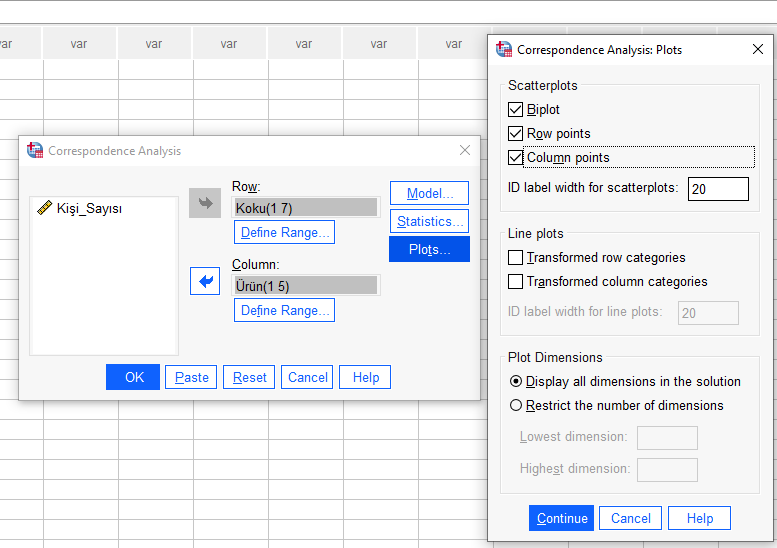
OK butonuna basarak SPSS’in Uyum Analizi’ini başlatmasını sağlayabiliriz.
SPSS, Uyum Analizi sonucu bize tablolar ve grafikler verecek.
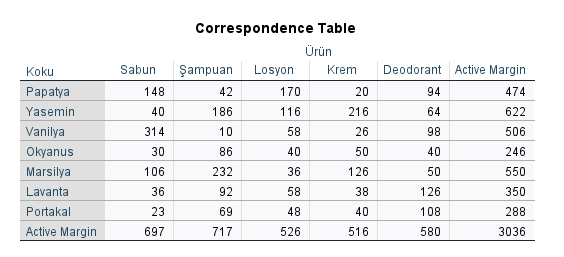
“Correspondence Table” tablosunda, her kategoride kaçar adet eleman olduğunu görebiliyoruz. Mesela, Yasemin kokulu Şampuan’ı satın alan 186 kişi olmuş. Bunun gibi yorumlayabiliriz bu tabloyu.
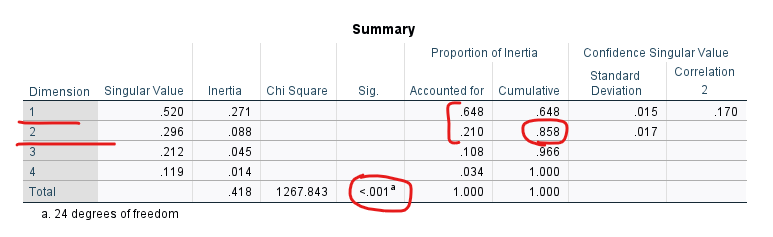
“Summary” tablosu önemli. Biz, Uyum Analizi sırasında, 5 x 7 ‘lik bir tabloyu 2 boyutlu bir düzlemde göstererek değişkenler ve kategorileri arasındaki ilişkileri gösteriyoruz. Yani “boyut azaltmış” oluyoruz. Boyutu azaltırken, gözlemlenen varyansın bir kısmını kaybederiz. Fakat varyansın çoğunu kaybetmemeliyiz.
Aşağıdaki “Summary” tablosunda, 1’den 4’e kadar sayıda boyut oluşturulduğunda, toplam varyansın ne kadarının açıklandığını görebiliriz. Her eklenen yeni boyut için açıklanan varyansın ne kadar değiştiğini de görebiliriz.
Örneğin verilerimiz analiz sonucu 1 boyuta indirgendiğinde, Proportion Of Inertia sütunundaki 0.648 değerinden anlayabileceğimiz üzere, istatistik modelimiz toplam varyansın %64.8’ini açıklamış demek oluyor.
1 yerine 2 boyuta indirgendiğinde, bu sefer 2. boyut gözlemlenen varyansın ekstradan 0.210’unu daha açıklıyor, toplam açıklanan varyans %85.8’e yükseliyor.
3. boyut eklendiğinde, %10.8 daha açıklanıyor ve toplam açıklanan varyans %96.6’ya çıkıyor. Son olarak 4. boyut da eklendiğinde %3.4 varyans daha açıklanıp gözlemlenen bütün varyans açıklanmış oluyor.
Burada, genellikle veri analizi sonucu veri 2 boyuta indirgenmek istenir. 2 boyuta indirgenmiş halinin de varyansın en az %80’ini açıklıyor olması istenir. Bu örnekte, model 2 boyuta indirgendiğinde gözlemlenen varyansın %85.8’ini açıklayabiliyor olduğu için, bu 2 boyutlu Uyum Analizi modelimiz istediğimiz kadar iyi bir modeldir diyebiliriz.
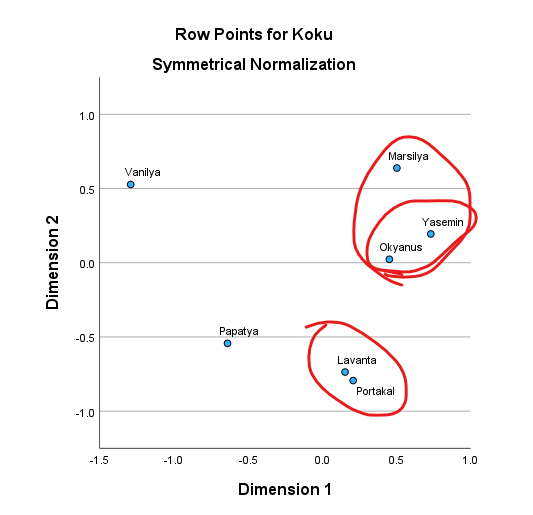
İki değişkenin birlikte uzaklık-yakınlık mesafe ilişkilerine bakmadan önce, her değişkenin kendi içinde kategorilerinin birbiriyle ilişkilerine bakalım.
Örneğin, bu verimizde, Lavanta ve Portakal birbiriyle çok yakın ilişki gösteriyormuş. Bu demek oluyor ki, Lavanta kokulu ürün alan müşteriler ve Portakal kokulu ürün alan müşterilerin satın alma davranışı birbirlerine çok benzemektedir.
Bir diğer örnek olarak, grafiğin sağ üst kısmında Okyanus ve Yasemin kokularının birbirine çok yakın olduğunu, Marsilya kokusunun da bunlara birazcık yakın olduğunu görebiliyoruz. Bu da demek oluyor ki Okyanus ve Yasemin kokulu ürün alan müşterilerin satın alma davranışı birbirlerine benzemekte, aynı zamanda Marsilya kokulu ürün alan müşterilerin de davranışı onlara benzemekte ama daha az benzemektedir. Yine de Marsilya kokulu ürün alan müşterilerin davranışı bu ikisine diğer kokulu ürün alan müşterilerden daha çok benzemektedir.
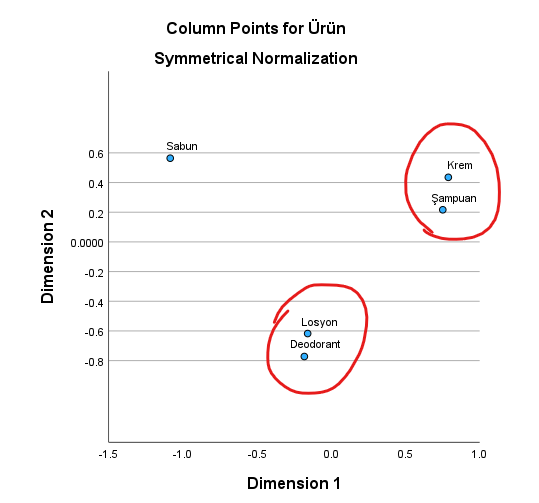
Aynı şekilde farklı ürün türlerini alan müşteriler için de bunun gibi yorumlamalar yapabiliriz. Krem ve Şampuan alan müşterilerin satın alma davranışı birbirlerine yakınmış. Aynı zamanda Losyon ve Deodorant alan müşterilerin de satın alma davranışı birbirine yakınmış. Ama Krem-Şampuan’dan birini alan ve Losyon-Deodorant’tan birini alan müşterilerin davranışları, birbirlerine benzememekteymiş.
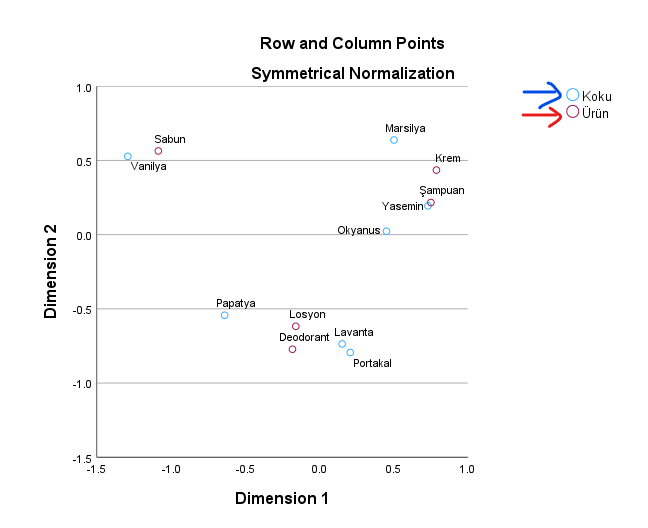
Son olarak, bize asıl en çok bilgiyi veren Uyum Analizi grafiğimiz olan, 2 değişkenin (Koku ve Ürün) de birlikte gösterildiği Uyum Analizi grafiğine bakalım.
Bu grafiğe göre, mesela sol üstte, Vanilya kokusu ile Sabun ürünü çok yakın konumlarda durmakta. Bu demek oluyor ki müşterilerde Vanilya kokulu ürün satın alma ile Sabun alma davranışı arasında bir ilişki varmış. Biraz önce yukarıda baktığımız “Correspondence Table” tablosuna tekrar bakarsak, Vanilya kokulu ürün alanların çoğunun Sabun aldığını tablodan okuyabiliriz. Bu grafik de, aslında bu tablodaki bilgiyi görselleştiriyor.
Aynı şekilde, Losyon-Deodorant ürünleri ile Lavanta-Portakal ürünleri birbirine yakın. Lavanta ya da Portakal kokulu ürün almakla Losyon ya da Deodorant almak arasında da bir ilişki görünüyor, o zaman biz üretici firma olarak Losyon ve Deodorant üreteceksek Lavanta ya da Portakal kokulu versiyonları daha fazla üretebiliriz.
Uyum Analizi (Correspondence Analysis) grafiğini bu şekilde okumaya devam edebiliriz.
SPSS ile Uyum Analizi hakkında bilmemiz gereken her şey bu kadardı. Unutmayın ki Uyum Analizi, Ki Kare gibi kategorik veri analizlerinde elde ettiğimiz “3 x 5” gibi kontenjans tablolarının (contingency table) grafiğe dökülerek görselleştirilmiş halidir. Bu sayede, istatistik konusuna çok hakim olmayan kişilere kategorik veri analizi sonuçlarını anlatmayı kolaylaştırır.
Bir yanıt bırakın