
İçindekiler
Ordinal Regresyon Analizi, bağımlı değişkenin ordinal (sıralı) yapıda olduğu durumda bağımsız değişkenlerden yola çıkarak bağımlı değişkeni tahmin etmek için kullanılan regresyon analizi türüdür. Bu yazıda, Ordinal Regresyon Analizi’nin ne olduğunu ve SPSS ile nasıl Ordinal Regresyon Analizi yapıldığını adım adım anlatıyorum.
Ordinal Regresyon Nedir?
Ordinal Regresyon Analizi, bağımlı değişken ordinal (sıralı) yapıda bir değişken olduğunda, yani tam olarak sayısal olmadığında, kategorik olduğunda ama sıralı kategorilere sahip olduğunda kullanılan bir regresyon analizi türüdür. Ordinal Regresyon analizinin amacı, bir veya daha fazla bağımsız değişkene dayanarak bir gözlemin daha yüksek bir kategoriye denk gelme olasılığını tahmin etmektir.
SPSS programında Ordinal Regresyon Analizi yapılırken, genellikle, Lojistik Regresyon Analizi’nde olduğu gibi Logit fonksiyonu kullanılır. Bu yüzden bu analizden bazı kaynaklarda “Ordinal Lojistik Regresyon” olarak da bahsedilir.
Ordinal Regresyon’da bağımlı değişken ordinal yapıda olmalıdır. Yani mesela aşağıdakiler gibi olabilir:
- Düşük-orta-yüksek risk
- Zayıf-orta-şiddetli depresyon
- Fakir-orta-zengin gelir durumu
- İlkokul-ortaokul-lise-üniversite eğitim durumu
Ordinal Regresyon, başka tür regresyon analizleriyle karıştırılabilir. Aşağıda Ordinal Regresyon analizinin diğer popüler regresyon analizi türlerinden farklarını kısaca anlattım.
- Bağımlı değişken sayısal yapıda veri olduğunda Çoklu Doğrusal Regresyon analizi yapılır (mesela stres ölçeği skoru). Ordinal Regresyon ise, bağımlı değişkenin sıralı kategorilere sahip olduğu durumlar için uygundur (mesela ilkokul-ortaokul-lise veya düşük-orta-yüksek gelir durumu).
- Bağımlı değişken 2 kategoriye sahip bir kategorik değişken (mesela hasta-sağlıklı) olduğu zaman Binary Lojistik Regresyon analizi yapılır. Bağımsız değişken 2’den fazla kategoriye sahip bir kategorik değişken (mesela A-B-0-AB kan grubu) olduğu zaman Multinominal Lojistik Regresyon analizi yapılır. Bunun aksine, Ordinal Regresyon analizinde bağımlı değişken sıralı kategorik bir yapıdadır (mesela fakir-orta-zengin veya düşük-orta-yüksek risk grupları).
Ordinal Regresyon, bağımlı değişkenin ordinal (sıralı) yapıda olduğu bütün regresyon analizlerinin genel adıdır. SPSS’te Ordinal Regresyon analizi yapıldığında, bu genellikle Logit fonksiyonunun kullanıldığı Ordinal Regresyon analizi şeklinde yapılmaktadır. Bu yüzden bu sayfanın devamında vereceğim örnekte bunun üzerinden gideceğim.

Ordinal Regresyon İçin Veriler Nasıl Olmalıdır?
- Yalnızca 1 adet bağımlı değişken olmalıdır.
- Bağımlı değişken 3 veya daha fazla kategoriye sahip olmalıdır ve kategorilerin belli bir sırası olmalıdır. (mesela havuç-portakal-muz uygun olmaz, hafif-orta-şiddetli hastalık uygun olur)
- Bağımsız değişkenler 1 veya daha fazla sayıda olabilir.
- Bağımsız değişkenler kategorik yapıda veya sürekli sayısal yapıda olabilirler, fark etmez.
Ordinal Regresyon Varsayımları
Ordinal Regresyon Analizi sonuçlarının yorumlanmasının uygun olabilmesi için öncelikle verinin bazı şartları sağlaması gerekmektedir.
- Proportional Odds (Paralel Doğrular Varsayımı): Bağımsız değişkenlerin etkisi, bağımlı değişkenin tüm kategori eşiklerinde aynı olmalıdır.
Bu varsayımın sağlanıp sağlanmadığını analizi yaparken test ediyoruz, aşağıda gösteriyorum.
Bu varsayımın sağlanması çok önemli o yüzden her zaman bunu kontrol etmek lazım. Eğer bu varsayım sağlanmıyorsa Ordinal Regresyon yerine Multinominal Lojistik Regresyon analiziyle yola devam etmek gerekir.
SPSS ile Ordinal Regresyon Nasıl Yapılır?
Ordinal Regresyon, bağımlı değişkenin ordinal (sıralı) yapıda olduğu bütün regresyon analizlerinin genel adıdır. SPSS’te Ordinal Regresyon analizi yapıldığında, bu genellikle logit fonksiyonunun kullanıldığı Ordinal Regresyon analizi şeklinde yapılmaktadır. Bu yüzden bu sayfada SPSS’te Ordinal Regresyon analizinin nasıl yapıldığını anlatacağım.
Aşağıdaki adımları izleyerek SPSS programında Ordinal Regresyon analizi yapabiliriz.
Bu örnekte, bağımlı değişken bir Memnuniyet soru formu olacak. Katılımcılara, bir üründen memnun olup olmadığını soran 1 adet soru sorulmuş. Sorulara 1’den 7’ye kadar farklı cevaplar veriliyor, aşağıda görebilirsiniz. Bu sorulara verilen cevaplar arasında sıralı bir ilişki var, cevap numarası yükseldikçe memnuniyet artıyor. Fakat iki cevap numarası arasındaki uzaklığa tam olarak sayısal denemez (mesela 2 değeri 1’in 2 katı değil, sayılar sırayla yükseliyor sadece). Bu yüzden bu soru formu sürekli veri tipinde değil, sıralı (ordinal) veri tipinde diyebiliriz.
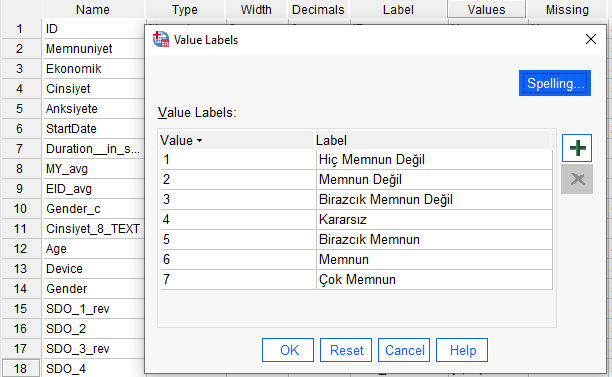
Bağımsız değişkenlerimiz ise şunlardır:
- Ekonomik Durum (Fakir – Orta – Zengin) (Ordinal Veri)
- Cinsiyet (Erkek – Kadın) (Kategorik Veri)
- Anksiyete Seviyesi (1’den 7’ye kadar her puan alınabiliyor) (Bu ölçek, 1-7 arası cevap seçeneği bulunan birden fazla sorunun birleştirilmesiyle oluşturulduğu için, sıralı veri değil de Sürekli Sayısal Veri gibi düşünülebilir)
SPSS’te Ordinal Regresyon analizi yapmaya başlayalım.
Analyze -> Regression -> Ordinal
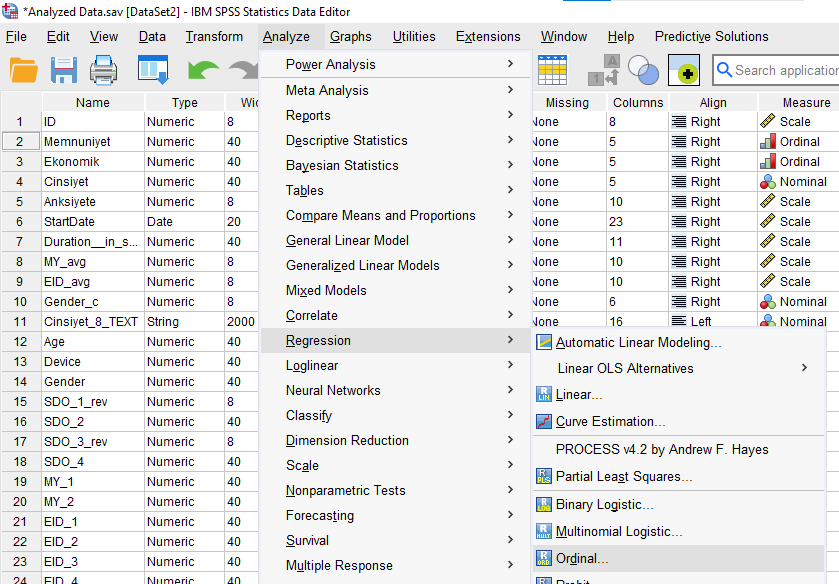
Bağımlı değişkeni Dependent kutusuna, kategorik veya ordinal yapıdaki bağımsız değişkenleri Factors kutusuna, sürekli veri tipindeki bağımsız değişkenleri de Covariates kutusuna atıyoruz.
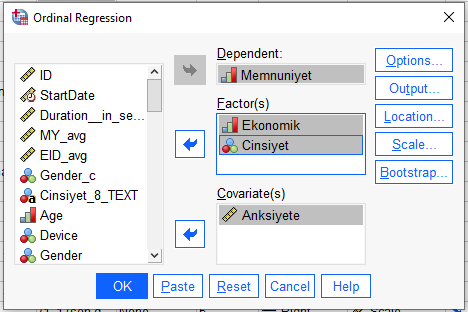
“Options”a basıp açılan pencerede Link olarak Logit seçildiğinden emin oluyoruz. (Bu SPSS’in bu analizi Ordinal Regresyon analizi şeklinde gerçekleştirmesini sağlıyor)
“Output”a basıp açılan pencerede resimde görülen seçenekleri işaretliyoruz.
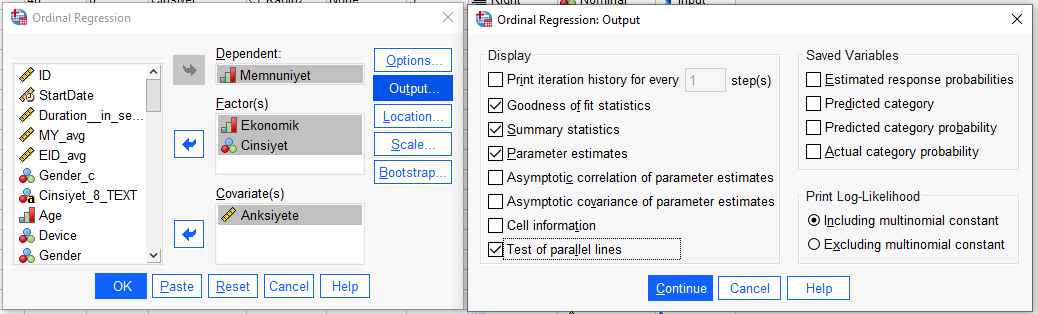
OK’a basarak analizi başlatabiliriz artık.

Ordinal Regresyon SPSS Tablo Yorumlama
SPSS, yaptığımız Ordinal Regresyon analizi sonucunda bize bir sürü tablo veriyor. Bu tabloların nasıl yorumlandığını göstereceğim şimdi.
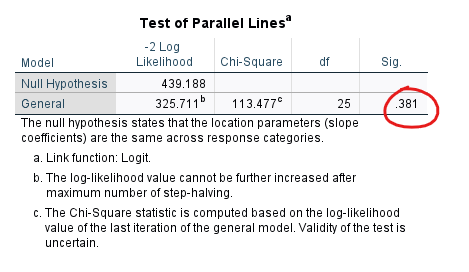
Test of Parallel Lines Tablosu
Her şeyden önce ilk bakmamız gereken tablo budur.
Ordinal Regresyon analizinin en önemli varsayımının test edildiği yer burası. Eğer bu tablodaki p değeri 0.05’ten küçük çıkarsa diğer tabloları okumadan Multinominal Lojistik Regresyon analizi yapmaya geçmeliyiz. Sebebini şimdi anlatıyorum.
Proportional Odds (Paralel Doğrular Varsayımı)
Proportional Odds (Paralel Doğrular Varsayımı), ordinal lojistik regresyonun kalbidir. Eğer bu varsayımı modelinizden çıkarırsanız, modeliniz ordinal (sıralı) regresyon olmaktan çıkar, bildiğimiz çok kategorili (nominal/multinomial) lojistik regresyona dönüşür.
Ordinal regresyonda, bağımlı değişkeninizin kategorilerini birbirinden ayıran kesme noktaları (eşikler / thresholds) vardır.
- Örneğin bağımlı değişkenimiz müşteri memnuniyeti olsun: [Düşük] vs [Orta] vs [Yüksek].
- Model arka planda iki farklı karar sınırı (grafikte iki farklı doğru) çizer:
-
- Düşük ile Orta ve Yüksek arasındaki sınır.
- Düşük ve Orta ile Yüksek arasındaki sınır.
Diyelim ki bir hastalığın şiddetini inceliyorsunuz: Hafif, Orta, Ağır. Bağımsız değişkeniniz de Yaş.
Eğer paralel doğrular varsayımı sağlanıyorsa, model size tek bir Yaş katsayısı (β) verir. Pratikte bu durum şu anlama gelir:
- Yaşın, bir hastayı “Hafif” kategorisinden “Orta veya Ağır” kategorisine taşıma gücü (etkisi) neyse; aynı yaşın, hastayı “Hafif veya Orta” kategorisinden “Ağır” kategorisine taşıma gücü de tıpatıp aynıdır.
- Yani bağımsız değişkenin etkisi, kategorilerin neresinde olduğunuza göre değişmez. Model her kategori geçişi için ayrı bir katsayı hesaplamak yerine, tüm geçişler için ortak, tek bir katsayı kullanır.
Pratikte bu varsayım der ki: “Bağımsız bir değişkenin (örneğin fiyatın) bu iki sınır üzerindeki etkisi (eğimi) tamamen aynıdır.” Grafiğe döktüğünüzde bu iki sınır doğrusu birbirine paralel hareket eder. Yani fiyat arttıkça, müşterinin “Düşükten Ortaya” geçme olasılığı ne kadar tetikleniyorsa, “Ortadan Yükseğe” geçme olasılığı da aynı oranda (aynı katsayıyla) tetiklenir.
Pratikte Bize Sağladığı Kolaylık Nedir?
-
Yorumlama Kolaylığı: Eğer varsayım sağlanıyorsa, model çıktısını okumak çok kolaydır. “Yaş arttıkça, hastalık şiddetinin daha üst kategorilerde olma olasılığı X kat artmaktadır” der ve geçersiniz. Her kategori çifti için ayrı bir açıklama yapmanıza gerek kalmaz.
-
Model Sadeliği (Parsimony): Daha az parametreyle, daha sade ve güçlü bir model kurmuş olursunuz.
Bu Varsayım Pratikte Ne Zaman Patlar? (İhlal Durumu)
Her bağımsız değişken bu kurala uymak zorunda değildir. Varsayımın çiğnendiği duruma pratik bir örnek verelim:
Bağımlı değişkenimiz yine Eğitim Seviyesi olsun: [İlkokul] , [Lise] , [Üniversite]. Bağımsız değişkenimiz de Burs İmkanları olsun.
- Burs imkanlarının artması, bir kişiyi İlkokuldan Liseye geçirmede çok büyük bir etkiye sahip olabilir.
- Ancak aynı burs imkanları, zaten Lisede olan birini Üniversiteye geçirmede o kadar büyük bir etki yaratmıyor olabilir (çünkü orada devreye sınav başarısı, aile vizyonu vb. giriyor olabilir).
İşte bu durumda Paralel Doğrular Varsayımı İHLAL EDİLİR. Çünkü “Burs” değişkeninin etkisi, alt kategorilerde (İlkokul-Lise) farklı, üst kategorilerde (Lise-Üniversite) farklıdır. doğrular paralel değil, birbirini kesen cinstendir.
Eğer bu varsayım ihlal edilirse, o zaman Multinominal Lojistik Regresyon analiziyle yola devam etmeniz gerekmektedir.
Yani özet olarak “Test of Parallel Lines” tablosunda Sig. sütunu yani p değerinin 0.05’ten büyük olmasını istiyoruz. Büyük bir p değeri demek olur ki “bağımsız değişkendeki her kategori için bir katılımcının bağımlı değişkendeki yüksek veya düşük kategoriye düşme oranı, kategoriler arasında yaklaşık aynıdır”. Yani arada etkiyi karıştırıcı başka bir etki olmadığı anlamına gelmektedir. Bu tablodaki p değeri anlamlıysa Ordinal Regresyon yerine analizi Multinominal Lojistik Regresyon yöntemiyle analiz yapılması önerilir.
Bizde bu p değeri 0.381 yani varsayım sağlandı diyebiliriz.
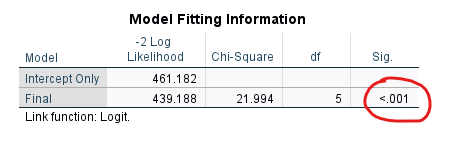
Model Fitting Information Tablosu
“Model Fitting Information” tablosunda Sig. sütunundaki değer p değerini gösteriyor. Eğer p değeri 0.05’ten küçük ise demek ki modelimizde en az 1 adet bağımsız değişken, bağımlı değişkeni anlamlı şekilde açıklayabilmiştir.
Bu tabloya göre modelin anlamlı olması, kurduğumuz regresyon modelinde (hiçbir anlamlı etki olmayan modele göre) model uyumunda önemli bir iyileşme olduğunu gösterir. Bu genellikle demek olur ki gözlemlediğimiz bağımsız değişkenlerden en az 1 tanesi bağımlı değişken üzerinde anlamlı etkiye sahiptir.
Bu örnekte p < 0.001 çıkmış yani 0.05’ten küçük olduğu için model bağımlı değişkeni istatistiksel olarak anlamlı şekilde tahmin etmeye yarıyor demektir.
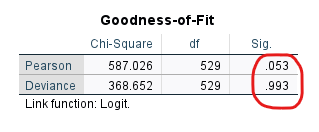
Goodness-of-Fit Tablosu
“Goodness-of-Fit” tablosunda bulunan değerler uyum iyiliğini gösterir yani kurulan ordinal lojistik regresyon modelinin veriye iyi uyum sağlayıp sağlamadığını gösterir. Biz iyi uyum sağlamasını isteriz. Bu yüzden Sig. sütunlarının (yani p değerleri) ikisinin de 0.05’ten büyük olmasını istiyoruz.
Bu tablo, gözlemlenen gerçek verilerin, uyumlu olduğunu düşünerek oluşturduğumuz modeldekilere ne kadar iyi karşılık geldiğinin ölçülmesi anlamına gelir. Burada 0.05’ten büyük bir değer, gözlemlenen veriler ile oluşturulan model arasında önemli bir fark olmadığı anlamına gelir (yani “model veriye uygundur” demektir).
Bizde p değerleri 0.053 ve 0.993 çıkmış yani model veriye uygun diyebiliriz.
Pseudo R Square Tablosu
“Pseudo R Square” tablosunda 3 adet değer vardır. Bunlara “Pseudo R-Square” yani “Yalancı R-Kare” denir. Bu değerler, doğrusal regresyon analizinde kullanılan R Square yani R Kare değeri gibi gerçek varyansı tam olarak temsil etmez, ancak doğrusal regresyondaki R Kare değerine benzetilerek modifiye edilmiştir.
- Nagelkerke satırını okuyarak “Nagelkerke R2 değeri (R2 = 0.138), modelin bağımlı değişkendeki varyansın yaklaşık %13.8’ini açıkladığını göstermektedir.” şeklinde bir yorum yapabiliriz.
- Cox and Snell için de benzer bir yorum geçerlidir.
Ordinal Regresyon analizi için özel olarak en popüler olan değer McFadden değeridir.
- “McFadden değeri 0.040 bulunmuştur; bu doğrultuda ordinal regresyon modelinin, hiçbir etkinin olmadığı modele göre %4.0 oranında bir iyileşmeyi sağladığını göstermektedir.” şeklinde yorumlanır.

Parameter Estimates Tablosu
“Parameter Estimates” tablosunda Location bölümünü okumak gerekir. Threshold bölümünü okumak gereksizdir.
Anksiyete’yi yorumlayalım önce. Sig. sütunundaki p değeri 0.05’ten küçük olduğu için Anksiyete’nin bağımlı değişken üzerinde anlamlı bir etkisi var demek. Ne yönde anlamlı bir etkisi var diye bakmak için Estimate sütununda negatif mi pozitif mi bakmamız gerekiyor. Pozitif ise Anksiyete arttıkça Memnuniyet kategorisi artıyor demektir. (Estimate sütunundaki değer, Anksiyete’deki 1 birimlik artışın Memnuniyet’te kaç birimlik artışa karşılık geldiğini söylemez. Bunu daha sonra hesaplayacağız.)
Ekonomik durumla ilgili olan 3 satıra bakalım. 1 Fakir, 2 Orta Gelir, 3 Zengin diye kodlamıştık en başta verimizde. SPSS, Ordinal Regresyon analizini düzgün yapabilmek için Zengin kategorisini referans kategorisi olarak aldı. Fakir’in Zengin ile karşılaştırmasını en üstteki Ekonomik satırında görebiliriz. Buna göre, “Fakir katılımcılar Zengin’e göre daha düşük Memnuniyet’e sahiplermiş (Estimate sütunu değeri negatif çünkü). Ama bu durum istatistiksel olarak anlamlı değilmiş (çünkü Sig. yani p değeri 0.822).” Aynı şekilde, “Orta gelirli katılımcılar Zengin’e göre daha düşük Memnuniyet’e sahiplermiş (Estimate sütunu değeri negatif çünkü). Ama bu durum istatistiksel olarak anlamlı değilmiş (çünkü Sig. yani p değeri 0.266).”
Cinsiyet bölümünü de aynı şekilde okuyoruz. Verimizde 5 Kadın, 6 Erkek, 7 de Diğer cinsiyet olarak kodlanmıştı. “Diğer” kategorisi SPSS tarafından cinsiyet için referans kategorisi olarak belirlenmiş. O zaman en üstteki Cinsiyet satırlarına göre, “Kadın bireyler Diğer cinsiyete göre istatistiksel olarak anlamlı şekilde daha yüksek Memnuniyet’e sahiplermiş” ve “Erkek bireyler Diğer cinsiyete göre istatistiksel olarak anlamlı şekilde daha yüksek Memnuniyet’e sahiplermiş” diye iki cümle kurabiliriz.
Maalesef Fakir ile Orta Gelir’in karşılaştırmasını veya Erkek ve Kadın’ın karşılaştırmasını bu analizde göremiyoruz. Görmek istersek referans kategorisini ya Fakir ya da Orta Gelir (aynı zamanda ya Kadın ya da Erkek) olarak ayarlayıp tekrar böyle bir Ordinal Lojistik Regresyon analizi yapmamız gerekecektir.
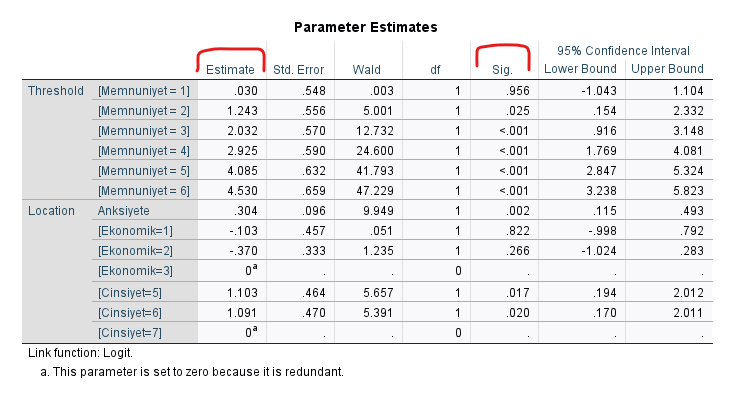
Maalesef, SPSS otomatik olarak “bağımsız değişkenlerdeki her 1 birimlik artış bağımlı değişkende neye karşılık geliyor” sorusunun cevabını vermemizi sağlayan sayısal değeri bize vermiyor. Bunu kendimiz hesaplamalıyız.
Bunu öğrenmek için, bu tabloda istatistiksel olarak anlamlı olan (p < 0.05) her satır için Estimate sütunundaki değeri, Exp() fonksiyonunun içine almamız gerekiyor elimizle. Herhangi bir hesap makinesinde bunu yapabilirsiniz.
Burada, Exp() fonksiyonu sonucunun değeri, Odds Ratio yani “gerçekleşme olasılıklarının oranı” cinsinden bize sunuluyor. Odds Oranı, 0 ile sonsuz arasında değişebilir. 1’den büyük bir Odds Ratio değeri artışı işaret ederken, 1’den küçük bir Odds Ratio değeri azalışı işaret eder.
Ordinal Regresyon analizi sonucunda “bağımsız değişkendeki 1 birimlik artış, bağımlı değişkende kaç birimlik bir artışa denk geliyor” şeklinde bir cümle kuramıyoruz. Bunun yerine, “bağımsız değişkendeki 1 birimlik artış, bir katılımcının daha yüksek bir gruba ait olma ihtimalini ne kadar arttırıyor” şeklinde bir cümle kurabiliyoruz.
Bu sayfada incelediğimiz Ordinal Regresyon analizi için bu işlemi her satır için sırayla yapacak olursak:
- Anksiyete: Exp(0.304) = 1.35 Odds Ratio değeri. Bu değişkenin türü sürekli veri tipi. Demek ki, “Anksiyete’de 1 birimlik artış, bir kişinin daha yüksek bir Memnuniyet kategorisinde yer alma ihtimalini 1.35 oranında arttırıyormuş (%35 arttırıyormuş).”
- Fakir vs Zengin: Exp(-0.103) = 0.90 Odds Ratio değeri. Bu değişkenin türü kategorik. Referans kategorimiz Zengin’di. Demek ki, “Zengin yerine Fakir olmak, bir kişinin daha yüksek bir Memnuniyet kategorisinde yer alma ihtimali, daha düşük bir Memnuniyet kategorisinde yer alma ihtimalinin yalnızca %90’ı kadardır.”
- Orta vs Zengin: Exp(-0.370) = 0.69 Odds Ratio değeri. Bu değişkenin türü kategorik. Referans kategorimiz Zengin’di. Demek ki, “Orta yerine Fakir olmak, bir kişinin daha yüksek bir Memnuniyet kategorisinde yer alma ihtimali, daha düşük bir Memnuniyet kategorisinde yer alma ihtimalinin yalnızca %69’u kadardır.”
- Kadın vs Diğer: Exp(1.103) = 3.01 Odds Ratio değeri. Bu değişkenin türü kategorik. Referans kategorimiz Diğer’di. Demek ki, “Diğer yerine Kadın cinsiyetinde olan bir kişinin daha yüksek bir Memnuniyet kategorisinde yer alma ihtimali, daha düşük bir Memnuniyet kategorisinde yer alma ihtimalinin 3.01’i kadarmış (%201 arttırıyormuş veya %301 katına çıkarıyormuş).”
- Erkek vs Diğer: Exp(1.091) = 2.98 Odds Ratio değeri. Bu değişkenin türü kategorik. Referans kategorimiz Diğer’di. Demek ki, “Diğer yerine Erkek cinsiyetinde olmak, bir kişinin daha yüksek bir Memnuniyet kategorisinde yer alma ihtimali, daha düşük bir Memnuniyet kategorisinde yer alma ihtimaline göre %198 arttırıyormuş (toplam %298 oluyor diye).”
Bu sayfada örnek olsun diye bütün değişkenler için hesapladım ama gerçekte yalnızca istatistiksel olarak anlamlı çıkan “Anksiyete”, “Erkek vs Diğer”, ve “Kadın vs Diğer”in sonuçları önemlidir, kalan sonuçlar istatistiksel olarak anlamsız olduğu için yorumlanmamalıdır.
SPSS ile Ordinal Regresyon analizi hakkında anlatmak istediğim her şey bu kadardı. Okuduğunuz için teşekkürler.
Bir yanıt bırakın