
İçindekiler
- 1 Ki-Kare Bağımsızlık Testi Nedir?
- 2 Ki-Kare Bağımsızlık Testi Ne Zaman Yapılır?
- 3 Ki-Kare Bağımsızlık Testi Varsayımları
- 4 SPSS ile Ki-Kare Bağımsızlık Testi Nasıl Yapılır? (2 x 2) (Phi)
- 5 SPSS ile Ki-Kare Bağımsızlık Testi Nasıl Yapılır? (2 x 2 ‘den daha büyük ise mesela 3 x 2 ya da 3 x 3) (Cramer’s V)
Ki-Kare Bağımsızlık Testi, istatistiksel bir analiz yöntemidir ve iki kategorik değişken arasındaki ilişkiyi değerlendirmek için kullanılır. Bu test, birbirinden bağımsız iki grup arasında anlamlı bir ilişki olup olmadığını belirlemek için kullanılır. Bu yazıda Ki-Kare Bağımsızlık Testi’nin ne olduğunu ve SPSS programı ile nasıl yapılacağını anlatacağım.
NOT: Eğer bu sayfada anlatılan ki-kare testi, sizin aradığınız türdeki ki-kare testi değilse muhtemelen ki-kare uygunluk testi veya ki-kare homojenlik testi‘ni arıyorsunuz. Eğer durum böyleyse Ki-Kare Uygunluk Testi ve Ki-Kare Homojenlik Testi başlıklı yazılarımızdan birini okuyabilirsiniz. Emin değilseniz Ki-Kare Testi türlerini tanıttığım yazımı okumanızı tavsiye ederim.
AYRICA:
2 x 2 Ki Kare Analizi Adımlarına Geçmek İçin TIKLAYIN
3 x 3 Ki Kare Analizi Adımlarına Geçmek İçin TIKLAYIN
Ki-Kare Bağımsızlık Testi Nedir?
Ki-Kare Bağımsızlık Testi, iki kategorik değişken arasında istatistiksel olarak anlamlı bir ilişki (bağımlılık) olup olmadığını inceleyen bir testtir. Başka bir deyişle, bir değişkenin dağılımının diğer değişkene bağlı olup olmadığını araştırır.
Örneğin, bir araştırmacı cinsiyet (kadın/erkek) ile sigara içme durumu (içiyor/içmiyor) arasında ilişki olup olmadığını incelemek isteyebilir. Ki-Kare Bağımsızlık Testi, gözlenen frekanslar ile her iki değişkenin birbirinden bağımsız olması durumunda beklenen frekanslar arasındaki farkı hesaplar. Eğer fark anlamlıysa (p < 0.05), iki değişken arasında bağımlılık olduğu, yani dağılımlarının birbirine bağlı olduğu sonucuna varılır.
Yani Ki-Kare Bağımsızlık Testi sonucunda “Sigara içen kişiler daha çok erkek olma eğilimindedir.” şeklinde cümleler kurabilmek mümkün oluyor.
Ki-Kare Bağımsızlık Testi Ne Zaman Yapılır?
Ki-Kare Bağımsızlık Testi, iki kategorik değişkenin birbirine bağlı olup olmadığını incelemek istendiğinde yapılır. Yani, bir değişkenin dağılımının diğer değişkenden etkilenip etkilenmediğini görmek istediğinizde kullanılır.
Örnekler:
-
Cinsiyet (kadın/erkek) ile sigara içme durumu (içiyor/içmiyor) arasında ilişki var mı?
-
Eğitim düzeyi (lise, üniversite, yüksek lisans) ile internet kullanım sıklığı (günlük, haftalık, nadiren) arasında ilişki var mı?
Kısaca Ki-Kare Bağımsızlık Testi, iki kategorik değişken arasındaki ilişkiyi belirlemek için uygulanır.
Ki-Kare Bağımsızlık Testi Varsayımları
- Kategorik Veri Varsayımı: Ki-Kare Bağımsızlık Testi yalnızca kategorik verilerle çalışır. Değişkenler nominal veya en fazla ordinal ölçek türünde olmalıdır.
- Beklenen Frekans Sayılarının Yeterliliği: Ki-Kare Bağımsızlık Testi testi için hücrelerin içinde beklenen frekans sayıları, hücrelerin en az %80’inde en az 5 olmalıdır. Aynı zamanda, beklenen frekans değeri 1’den küçük hiçbir hücre de olmamalıdır. Eğer bu koşullar sağlanmıyorsa, Ki-Kare Bağımsızlık Testi yeterince isabetli sonuçlar vermez. Bu durumda, Fisher’s Exact Test sonuçları yorumlanmalıdır.

SPSS ile Ki-Kare Bağımsızlık Testi Nasıl Yapılır? (2 x 2) (Phi)
SPSS ile Ki-Kare Bağımsızlık Testi yaparken, verimizin değişkenlerinin kaç seviyeye sahip olduğu önemlidir. “2 x 2” demek, 2 değişkenimiz olması ve her değişkenin 2 seviyesi olması demektir. Örneğin, verimizde cinsiyet değişkeni (erkek ve kadın kategorilerine sahip) ve medeni durum değişkeni (evli veya bekar) varsa, buna 2 x 2 veri diyoruz.
Bu başlıkta 2 x 2 Ki-Kare Bağımsızlık Testi’nin nasıl yapıldığını anlatıyorum. 2 x 2 ‘den daha büyük, mesela 3 x 2 veya 3 x 3 büyüklüğünde bir verimiz varsa Ki-Kare Bağımsızlık Testi’nin nasıl yapılacağını da, bu sayfada aşağıda bu başlıktan sonraki diğer başlıkta anlatıyorum.
Şimdi, SPSS ile 2 x 2 Ki-Kare Bağımsızlık Testi yapmaya başlayalım.
Analyze -> Descriptive Statistics -> Crosstabs tuşlarına basıyoruz.
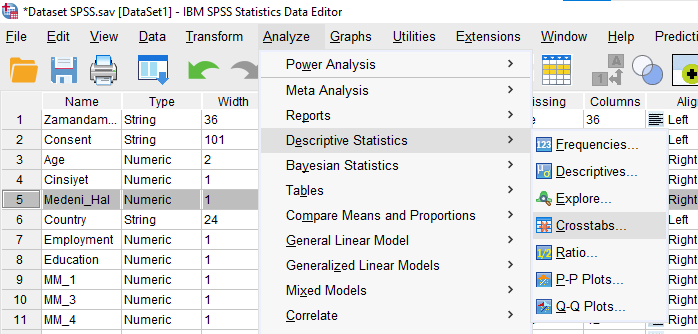
Değişkenlerimizin birini Row(s), diğerini Column(s) bölümüne atıyoruz.
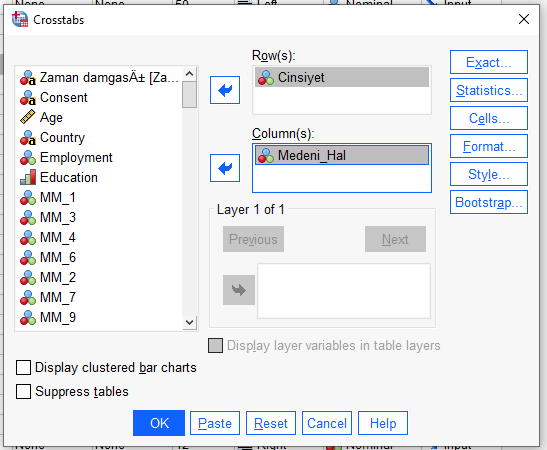
Statistics butonuna basıyoruz. Açılan küçük pencerede “Chi-square”i ve “Phi and Cramer’s V”yi işaretliyoruz.
“Chi-square” işaretlemek, SPSS’in Ki-Kare Bağımsızlık Testi yapmasını sağlar.
“Phi and Cramer’s V” işaretlemek, Ki-Kare Bağımsızlık Testi’ne dair etki büyüklüğünü analiz sonuçlarında görmemizi sağlar.
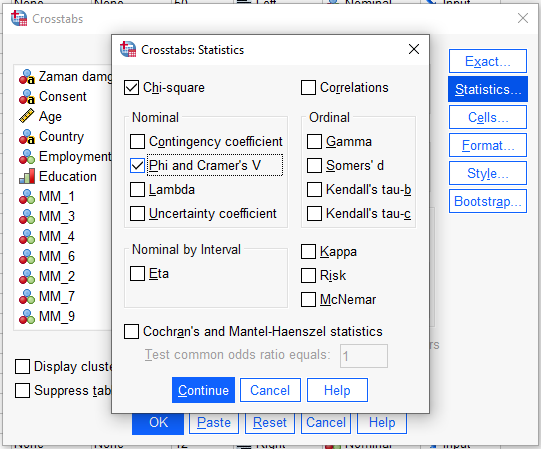
Continue’ya bastıktan sonra, deminki pencerede “Cells” butonuna basıyoruz.
“Observed” ve “Expected” seçenekleri seçili olacak şekilde ayarlıyoruz.
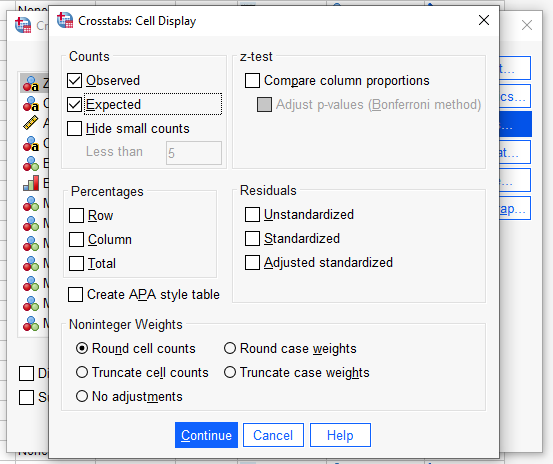
“Continue” ve sonra “OK” butonlarına basıyoruz.
SPSS bize Ki-Kare Bağımsızlık Testi’ne dair sonuç tablolarını sunacak. Bunları aşağıda inceleyebiliriz.
İlk tablo, analize verimizde bulunan kaç kişinin dahil edildiğidir. Eksik veri yoksa, bütün kişiler analize dahil edilir.
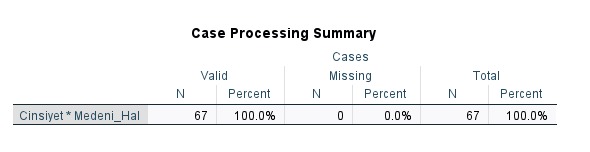
“Crosstabulation” tablosunda, hangi cinsiyetten kaç kişinin medeni halinin ne olduğunu görebiliyoruz. Gerçek değerleri görmek için, “Count” satırındaki değerlere bakmamız gerekiyor.
Mesela bizim örneğimizde, 26 kadın bekar, 10 kadın evli, 22 erkek bekar, 9 erkek evli olarak görünüyor. Toplam 36 kadın, 31 erkek, 48 bekar kişi, ve 19 evli kişi olduğunu da “Total” bölümüne bakarak görebiliriz.
“Expected Count” satırındaki değerler, iki değişken arasında hiçbir ilişki olmadığı kabul edilseydi her cinsiyette kaçar kişinin medeni durumunun ne olduğunu göstermektedir.
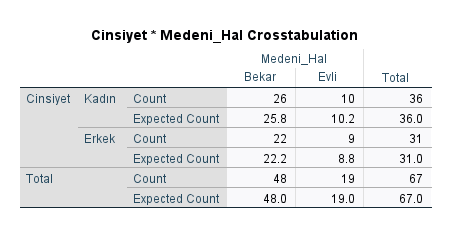
Ki Kare Bağımsızlık Testi sonucu istatistiksel olarak anlamlılık değerini, “Chi-Square Tests” tablosunda, “Pearson Chi-Square” satırındaki “Significance” sütunundan okuyoruz. Bu örnekte anlamlılık değeri yani p değeri 0.910 çıkmış. Bu p değeri 0.05’ten büyük olduğu için, “cinsiyet ve medeni durum arasında anlamlı bir ilişki bulunmamaktadır” demek oluyor.
Eğer p değeri 0.05’ten küçük çıksaydı “değişkenler arasında anlamlı bir ilişki var” demek olurdu.
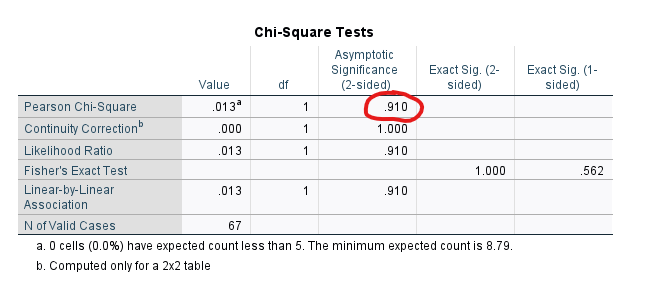
Ki Kare Bağımsızlık Testi Varsayımları başlığından hatırlayacağımız üzere, Ki-Kare Bağımsızlık Testi sonuçlarının güvenilir olması için, her hücredeki beklenen frekans değerlerinin 5’ten büyük olması gerekmekteydi. Bu örnekteki “Chi-Square Tests” tablosunun en alt kısmına bakarsanız, şöyle yazdığını göreceksiniz: “0 cells have expected count less than 5. The minimum expected count is 8.79.”
Bu demek oluyor ki, “Pearson Chi-Square” satırından okuduğumuz ki kare analizi sonucuna güvenebileceğiz.
Eğer tablonun altında “expected count less than 5” kısmında 0’dan büyük bir sayı yazsaydı, o zaman Ki-Kare Bağımsızlık Testi sonucunu bu tablodaki “Fisher’s Exact Test” satırından okumamız gerekecekti.
Ki Kare Post Hoc Analizi (2 x 2)
Eğer Ki-Kare Bağımsızlık Testi sonucu istatistiksel olarak anlamlı bir sonuç bulsaydık, hangi değişkenlerin hangi değerlerinin birbiriyle ilişkili olduğunu görmek için post hoc analizi yapmak gerekecekti. Bu biraz uzun, o yüzden bunu ayrıca bir yazıda uzun ve detaylı şekilde anlattım. Eğer ihtiyacınız olursa linke tıklayarak okuyabilirsiniz.
2 x 2 Ki Kare Etki Büyüklüğü Bulma (Phi)
Eğer Ki-Kare Bağımsızlık Testi’nde istatistiksel olarak anlamlı bir sonuç çıksaydı, “Symmetric Measures” tablosuna bakarak, bulduğumuz sonucun etki büyüklüğünü görebilecektik. Verimiz 2 x 2 büyüklüğünde olduğu için, Phi satırına bakarak okumamız gerekiyor. Buradaki “Value” sütunundaki değer, etki büyüklüğünü verecektir.
Bu örnekteki analizde Phi etki büyüklüğü 0.014 çıkmış. Oldukça küçük bir etki büyüklüğü. Zaten, yaptığımız Ki-Kare Bağımsızlık Testi’nde anlamlılık değeri 0.910 çıktığı için, istatistiksel olarak anlamlı bir ilişki de bulamadık. O yüzden etki büyüklüğünün böyle çok düşük çıkması normaldir.

Phi etki büyüklüğü değeri, 0 ile 1 arasında bir sayı olabilir.
- 0 ile 0,3 arasındaki Phi değerleri, küçük etki büyüklüğü anlamına gelir.
- 0,3 ile 0,5 arasındaki Phi değerleri, orta büyüklükte etki büyüklüğü anlamına gelir.
- 0,5 ile 1 arasındaki Phi değerleri, büyük etki büyüklüğü anlamına gelir.
2 x 2 Ki Kare Odds Ratio
Etki büyüklüğünü gözümüzde daha iyi canlandırmak için, Phi ya da Cramer’s V değerleri yerine Odds Ratio (odds oranı) denen konsepti de kullanabiliriz. Buna göre, bu analizde istatistiksel olarak anlamlı bir etki çıksaydı, Ki-Kare Bağımsızlık Testi sonucu gruplar arası farkları daha iyi anlamak için aşağıdaki gibi bir Odds Oranı hesaplaması yapacaktık.
Bekar Kadın / Bekar Erkek = 26 / 22 = 1.18
Evli Kadın / Evli Erkek = 10 / 9 = 1.11
Sonra 1.18 / 1.11 = 1.06
Yani bu hesap demek olmuş olacaktı ki, “Bekar insanlar arasında birinin Kadın olma ihtimali, Evli insanlar arasında birinin Kadın olma ihtimalinin 1.06 katı kadardır.”
SPSS ile Ki-Kare Bağımsızlık Testi Nasıl Yapılır? (2 x 2 ‘den daha büyük ise mesela 3 x 2 ya da 3 x 3) (Cramer’s V)
Ki-Kare Bağımsızlık Testi yaptığımız veri setimizde, 3’er adet seviyeye sahip 2 değişken de olabilir. Mesela cinsiyet (erkek, kadın, LGBT) ve meslek (işsiz, iş sahibi, öğrenci) şeklinde 3’er seviyeye sahip 2 değişkenimiz olabilir. Buna 3 x 3 Ki-Kare Bağımsızlık Testi deniyor. Böyle verimizin 2 x 2’den büyük olduğu durumda, Ki-Kare Bağımsızlık Testi yapmak ve yorumlamak biraz daha uzuyor.
Aşağıda 2 x 2 ‘den daha çok kategoriye sahip olan verilerimiz olduğu durumda SPSS ile Ki-Kare Bağımsızlık Testi nasıl yapmamız gerektiğini adım adım anlatıyorum.
Analyze -> Descriptive Statistics -> Crosstabs tuşlarına basıyoruz.
“Crosstabs” penceresinde, değişkenlerimizi Row(s) ve Column(s) kutucuklarına yerleştiriyoruz. Hangi kutuya hangi değişkeni koyduğumuz fark etmez.
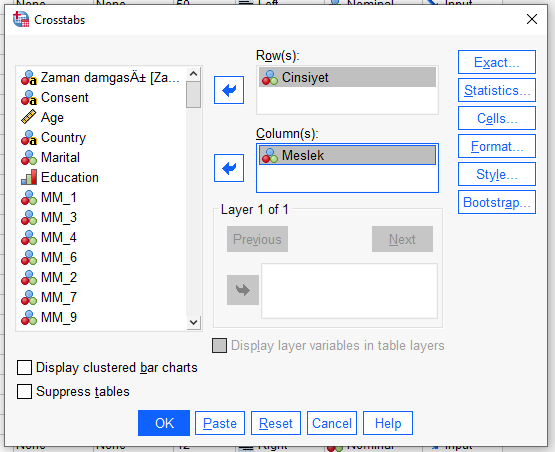
“Statistics” butonuna basıp, aşağıdaki resimdeki gibi, “Chi-square”, “Phi and Cramer’s V”, ve “Risk” işaretli olacak şekilde ayarlıyoruz.
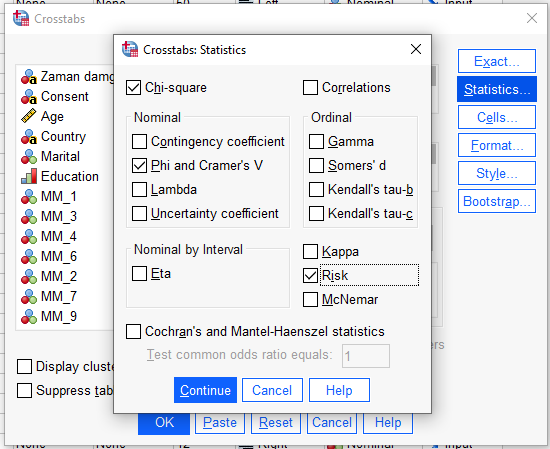
Continue ve OK’a basıyoruz ve SPSS bizim için Ki-Kare Bağımsızlık Testi’ni başlatıyor.
Aşağıda, SPSS sonuç tablolarını görebilirsiniz.
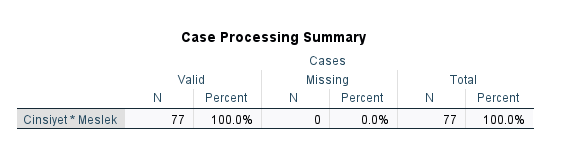
“Case Processing Summary” başlıklı tabloda, verimizde kaç kişi olduğu ve kaç kişinin verisinin eksik olduğu bilgilerini görebiliriz. Bizim verimizde 77 kişi var, hiç kimsenin verisi eksik değil.
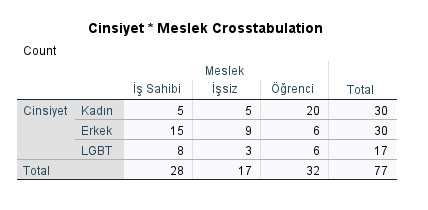
“Crosstabulation” tablosunda, hangi cinsiyetten kaç kişinin hangi meslek durumuna sahip olduğunun bilgisini görüyoruz. Mesela iş sahibi 5 kadın varken, işsiz 9 erkek ve 6 tane LGBT öğrenci varmış. 77 kişi arasında toplam 30 kadın ve aynı zamanda toplam 17 işsiz varmış.
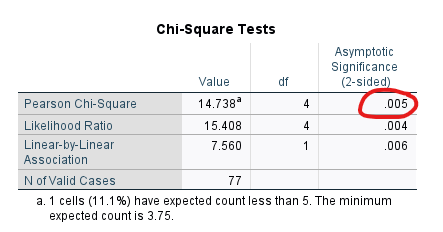
“Chi-Square Tests” tablosunda, Ki-Kare Bağımsızlık Testi’nin istatistiksel anlamlılık değerini (p değerini) görebiliyoruz. “Pearson Chi-Square” satırındaki, “Significance” sütunundaki değer bize p değerini veriyor.
Bu örnekte, p değeri 0.005 çıkmış. Bu değer 0.05’ten küçük olduğu için, cinsiyet ve meslek arasında istatistiksel olarak anlamlı bir ilişki olduğu sonucuna varıyoruz. Yani, “Farklı cinsiyetlerdeki kişilerin meslek dağılımları birbirine denk değildir. Bazı cinsiyetlerde birçok kişi bir çeşit meslekteyken başka cinsiyetlerde birçok kişi başka bir çeşit meslektedir.” şeklinde bir yorumlama yapabiliriz.
Cinsiyet ve meslek hakkında anlamlı bir ilişki olduğunu bulduk, fakat hangi cinsiyetlerin hangi meslekte daha yatkın olduğunu henüz bilmiyoruz. Bunu bulmak için, post hoc testleri yapmalıyız. Bu post hoc testlerinin mantığı, aynı ANOVA analizi yaparken olduğu gibidir. Ama SPSS’te yapılış adımları ANOVA’dakinden farklı.
3 x 3 Ki Kare Bağımsızlık Testi Post Hoc (Uzun Yol)
Ki Kare Bağımsızlık Testi sonucunda hangi değişkenlerin hangi değerleri arasında anlamlı bir ilişki olduğunu görmek için, SPSS’te post hoc testleri yapmak gerekiyor.
Bunun istatistiksel olarak en doğru yöntemi biraz uzun. Bunu, “Ki Kare Testi Post Hoc“ başlıklı yazıda uzun uzun her şey dahil anlatıyorum. Burada öyle uzun anlatacak olursam yazı gereksiz uzayacak. Eğer istatistiksel olarak en doğru ki kare post hoc analizini yapmış olmak istiyorsanız, linke tıklayarak ki kare post hoc’a özel yazımı okumanızı öneririm.
3 x 3 Ki Kare Bağımsızlık Testi Post Hoc (Kısa Yol)
Bu sayfada, aşağıda, daha kısa ve yeterince güvenilir olan, ama istatistiksel açıdan en altın standart yöntem olmayan ki kare post hoc yöntemini anlatacağım.
Önce, Analyze -> Descriptive Statistics -> Crosstabs tuşlarına basarak Crosstabs penceresini açıyoruz.
“Cells” butonuna basıyoruz.
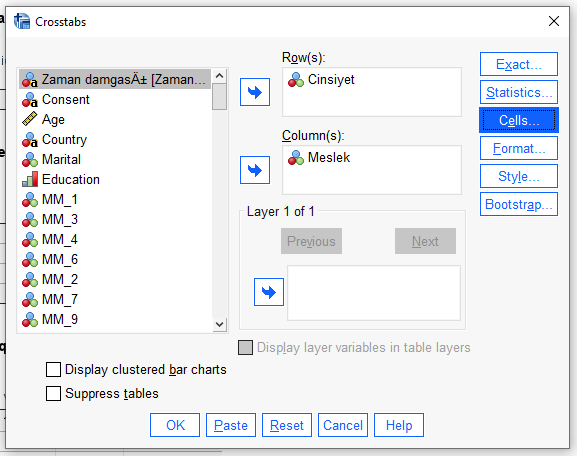
Açılan pencerede, “Residuals” bölümündeki “Adjusted standardized” seçeneğini işaretliyoruz.
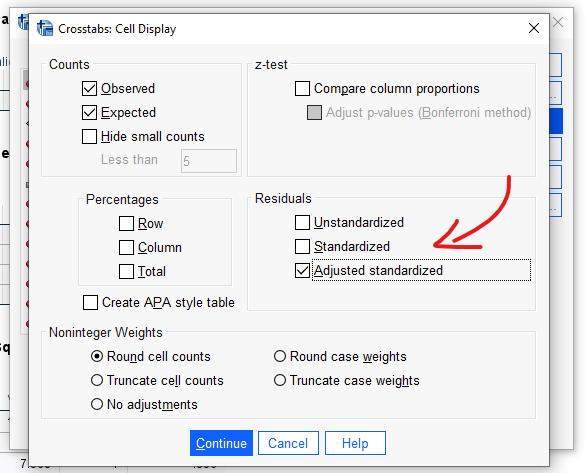
“Continue” ve “OK” butonlarına basıyoruz.
SPSS bize yeni tablolar verecek.
Bu tablolardan sadece “Crosstabulation” tablosuna bakmamız yeterli post hoc için.
“Crosstabulation” tablosunda, her grup için “Adjusted Residual” değerine bakmamız gerekiyor. İstatistik kaynaklarına göre, -1.96 değerinden küçük veya 1.96 değerinden büyük Adjusted Residual değerleri, 0.05 anlamlılık seviyesi eşik değerine göre, istatistiksel olarak anlamlı kabul edilmektedir.
Yani, Crosstabulation tablosundaki Adjusted Residual değeri -1.96’dan küçük veya 1.96’dan büyük değerlere sahip gruplar, beklenen değerden anlamlı olarak farklı sayıda kişi içermektedir. (Mesela iş sahibi olmak ve kadın olmak arasında anlamlı bir ilişki vardır. Bu veri setinde, iş sahibi kadın sayısı, beklenenden azdır.)
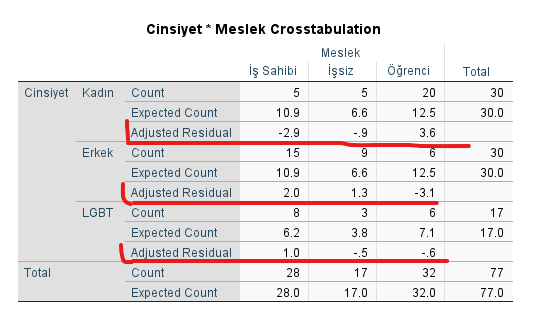
Bu örnekte, işsiz erkek ve iş sahibi LGBT dışında bütün cinsiyet-meslek çiftleri arasında anlamlı bir ilişki vardır. Gerçek değerin ortalamadan (ya da beklenen değerden) daha yüksek ya da daha düşük olduğuna Count ve Expected Count satırlarındaki değerleri karşılaştırarak bakabiliriz. Yani, tabloyu bu şekilde yorumlarsak, örneğin:
- “İş sahibi olan erkek sayısı, beklenenden anlamlı olarak daha fazladır.”
- “Beklenenden az orandaki kadın iş sahibidir.”
- “Kadınlar arasında istatistiksel olarak anlamlı biçimde yüksek oranda kişi, öğrencidir.”
formatında cümleler kurabiliriz.
3 x 3 Ki Kare Etki Büyüklüğü Bulma (Cramer’s V)
Hemen yukarıda gösterdiğim Ki Kare Bağımsızlık Testi sonucunda, p değeri 0.05’in altında olduğu için değişkenler arasında anlamlı bir ilişki olduğu sonucuna vardık. Post hoc testi yaparak hangi grupların beklenenden anlamlı olarak az ya da çok katılımcı içerdiğini de inceledik. Peki, değişkenler arasındaki ilişkinin ne kadar büyük olduğunu nasıl bulacağız?
Buna bulmak için, Ki Kare Bağımsızlık Testi’ne dair Cramer’s V etki büyüklüğü değerine bakmamız gerekiyor.
SPSS’te Ki Kare Bağımsızlık Testi yaptığımızda, SPSS bize “Symmetric Measures” başlıklı bir tablo da sunar. Bu tabloda, Cramer’s V satırıyla Value sütununun kesiştiği yere bakarsak, Cramer’s V değerini görebiliriz.
Bu örnekte, Cramer’s V değeri, 0.309 çıkmış. Peki bu Cramer’s V değerinin ne büyüklükte bir etki büyüklüğüne işaret ettiğini nereden bileceğiz? Cramer’s V değeri yorumlama işi biraz detaylı, o yüzden bu sayfanın gereksiz çok uzamaması adına onu Cramer’s V için özel olarak hazırladığım yazıda anlattım.
İstatistikçilerin en sık kullandığı Cramer’s V değeri yorumlama tablosuna göre göre, 3 x 3 Ki Kare Bağımsızlık Testi için 0.309 Cramer’s V değeri, orta büyüklükte bir etkiye işaret ediyor. Yani p değerine bakarak istatistiksel olarak anlamlı bulduğumuz Ki Kare Bağımsızlık Testi’nin etki büyüklüğü orta seviyededir.
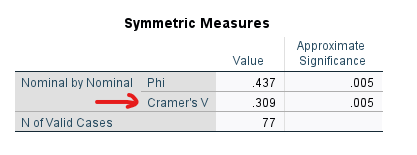
Cramer’s V satırında Approximate Significance sütununda p değeri yer alır ve bu Ki Kare Bağımsızlık Testi’nin istatistiksel anlamlılık düzeyini belirtir. Dikkat ederseniz bu, yukarıdaki “Chi-Square Tests” tablosundaki p değeriyle aynıdır.
Bir adet 2 x 2 ve bir adet de 3 x 3 örneklem üzerinden yaptığımız iki adet Ki Kare Bağımsızlık Testi’nin SPSS ile yapılış aşamaları ve yorumlama aşamaları bu kadardı. Artık, yapılan Ki Kare Bağımsızlık Testi’ni raporlama aşamasına geçilebilir.
Bir yanıt bırakın