
İçindekiler
SPSS analizlerinde kayıp veri önemli bir sorundur çünkü eksik veya yanlış veri analiz sonuçlarını ciddi şekilde etkileyebilir. Kayıp veriler, istatistiksel sonuçların doğruluğunu ve güvenilirliğini azaltabilir ve yanlış sonuçlara yol açabilir.
Kayıp verilere sahip kişilerin analize hiç dahil edilmemesi, örneklem büyüklüğünü azaltabilir ve sonuçların isabetliliğini düşürebilir. Özellikle kayıp veriler rastgele dağılmamışsa, analiz sonuçları örneklemi temsil etme konusunda yanıltıcı olabilir.
Kayıp verilerin yönetilmemesi veri setinde yanlılığa da neden olabilir. Eksik veri, analizlerdeki ilişkileri veya desenleri yanıltıcı şekilde değiştirebilir ve bu da karar alma süreçlerini etkileyebilir. Örneğin, kayıp veriye sahip bir değişken analize dahil edilmezse, bu değişkenin gerçek etkisi veya ilişkisi yanlış yorumlanabilir.
SPSS gibi analiz araçlarında eksik verilerin yönetimi, analiz sürecini karmaşıklaştırabilir. Kayıp verilerin uygun şekilde ele alınması için veri doldurma veya imputasyon (eksik verinin yazılım tarafından uygun görülen şekilde doldurulması) işlemleri yapılması gerekebilir. Bu işlemler, analizlerin doğruluğunu artırabilir ancak aynı zamanda veri setinin manipülasyonu yoluyla yanlılığa da yol açabilir.
Sonuç olarak, kayıp verilerin analiz sürecinde doğru bir şekilde yönetilmemesi, istatistiksel sonuçların güvenilirliğini ve doğruluğunu olumsuz yönde etkileyebilir. Bu nedenle, eksik verilerin etkin bir şekilde ele alınması ve analizlerde doğru bir şekilde dikkate alınması önemlidir.

SPSS ile Kayıp Veri Bulma
SPSS ile, verimizdeki kayıp verilerin rastgele mi olduğunu yoksa belli bir yönde daha mı çok kayıp veri olduğunu bulmak mümkündür. MCAR Testi adı verilen testi yaparak, verimizdeki kayıp verilerin rastgele dağılıp dağılmadığını kontrol edebiliriz.
MCAR Testi = Little’s Missing Completely At Random Test (Little’ın Tamamen Rastgele Eksik Veri Testi)
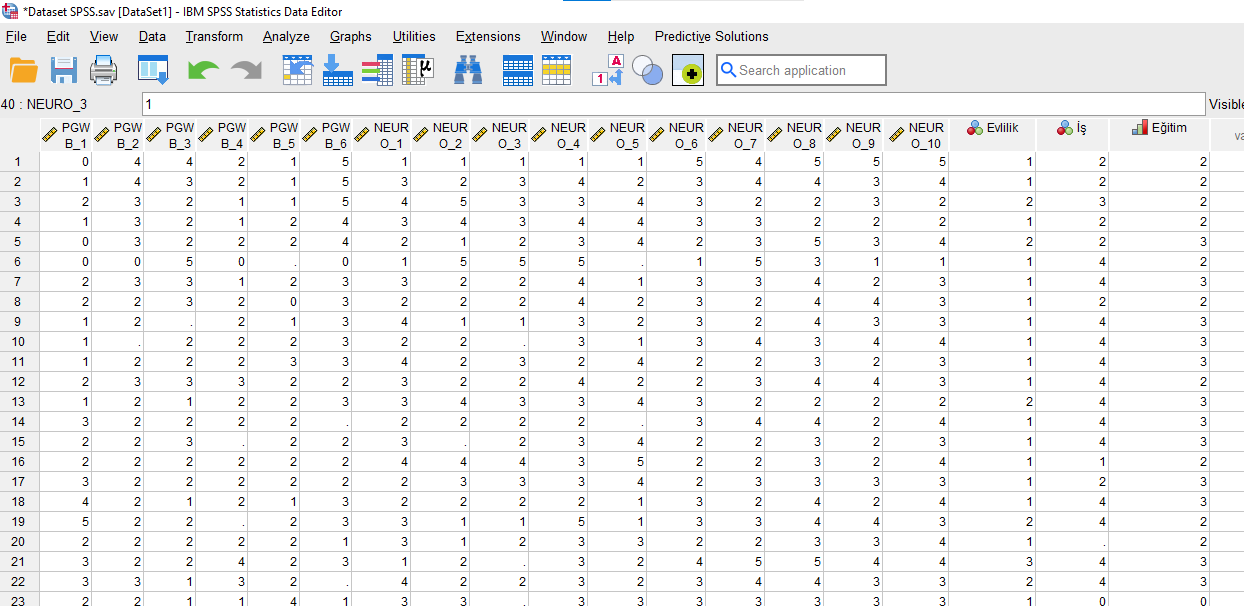
Bu örneğimizde, PGWB ve NEURO isimli iki tane ölçeğimizin soruları ve bir kişinin evlilik, iş ve eğitim durumları hakkında bilgi içeren bir verimiz var. Gördüğünüz gibi verideki bazı kutular sayı yerine nokta işareti ile dolu. İşte bunlar eksik verileri göstermektedir.
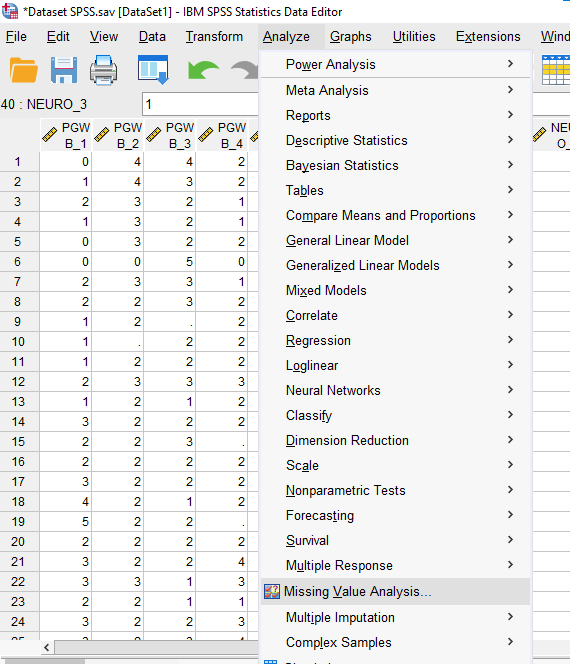
Analyze -> Missing Value Analysis
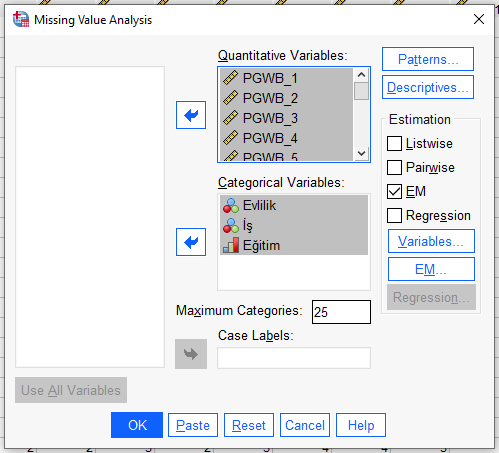
Verimizdeki devamlı ölçek şeklinde olan soruları Quantitative Variables kutusuna, kategorik ölçek şeklinde olan soruları da Categorical Variables kutusuna atıyoruz. EM seçeneğini işaretliyoruz. OK’a basıyoruz.
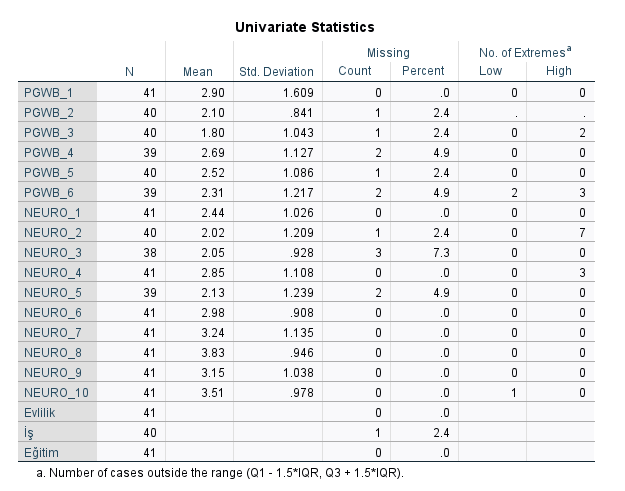
SPSS’in vereceği “Univariate Statistics” tablosunda, hangi sorularda kaçar tane eksik veri olduğunu görebiliriz. Genelde, bir soruda %2’den az eksik veri varsa bu göz ardı edilebilir. Daha fazla eksik veri varsa, eksik verileri tamamlama yoluna gidilebilir (bunu sayfanın devamında anlatacağım).
MCAR Testi’nin sonucunu, “EM Means” tablosunun altında görebiliriz. Tablonun altındaki Sig. p değeri 0.05’ten büyükse, demek olur ki verimizdeki kayıp veriler rastgele dağılmıştır. Genelde böyle olmasını tercih ederiz. Kayıp verilerin rastgele dağılmaması veri analizinde yanlılığa sebep olacaktır.


SPSS ile Kayıp Veri Tamamlama (eksik veriler rastgele ise)
Yaptığımız MCAR Testi’ne göre verimizdeki eksik veriler rastgele dağılmış ise, kayıp verileri birkaç şekilde tamamlayabiliriz. Bunlardan en popüler olan yöntem “Expectation-Maximization” yani “Beklentiyi-Maksimize-Etme” yöntemidir.
Expectation-Maximization Yöntemiyle Kayıp Veri Atama
Eksik veri atama konusunda en önerilen yöntem budur.
Analyze -> Missing Value Analysis
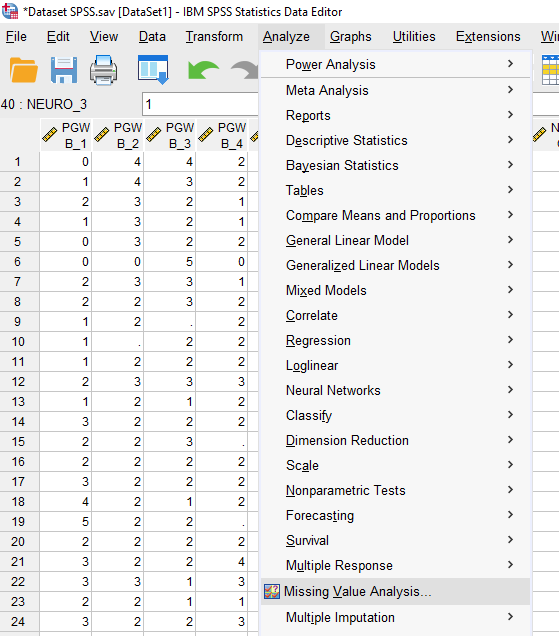
Birçok sorudan oluşan her ölçek için bu işlemi ayrı ayrı yapmak daha tercih edilmelidir çünkü veriler birbiriyle daha yüksek korelasyon gösterecektir ve bu daha isabetli olacaktır.
Önce bir ölçeğimizdeki soruları Quantitative Variables kutusuna koyuyoruz. EM işaretliyoruz. Sonra EM butonuna basıyoruz. Açılan pencerede aşağıda Save Completed Data işaretleyip Dataset Name kısmına yeni oluşturulacak değişkenin isminin ne olmasını istiyorsak onu yazıyoruz.
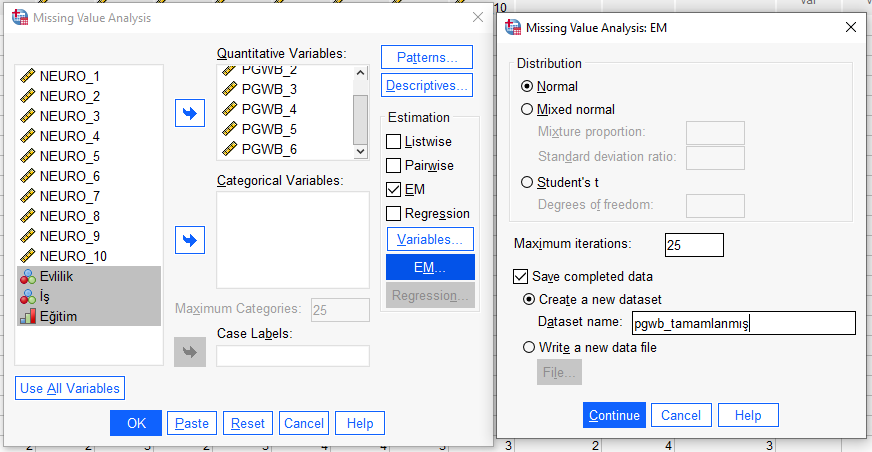
SPSS yeni bir veri seti dosyası açacaktır. Burada, deminki veri setinde eksik olan veriler, tamamlanmış olarak gözükecektir. SPSS, diğer verilerle karşılaştırıp eksik verilerin yerinde hangi verilerin olmasını en uygun gördüyse o değerleri eksik verilerin yerine yazmış olacaktır.
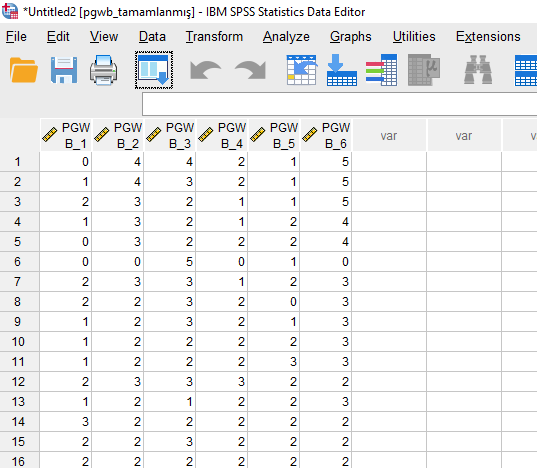
Yine Analyze -> Missing Value Analysis
Bu sefer diğer değişkenin sorularını kutuya koyup aynı işlemi yapıyoruz.
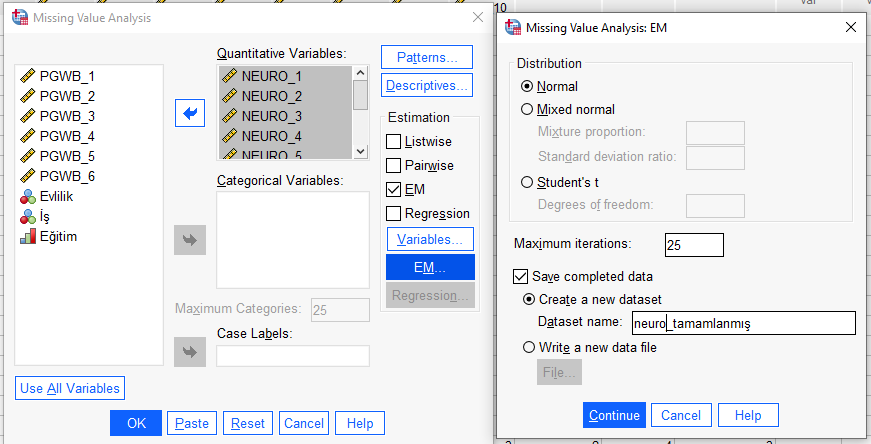
Yine yeni bir değişken dosyası açılacak. Orijinal dosyadaki eksik veriler bu dosyada tamamlanmış olarak görünecek.
İki veriyi birleştirelim şimdi.
İlk oluşturduğumuz yeni tamamlanmış değişken dosyasına gelelim.
Data -> Merge Files -> Add Variables
İkinci oluşturduğumuz tamamlanmış değişken dosyasını seçelim.
Gördüğünüz gibi yeni oluşturulan, eksik verisiz iki dosya birleştirildi.
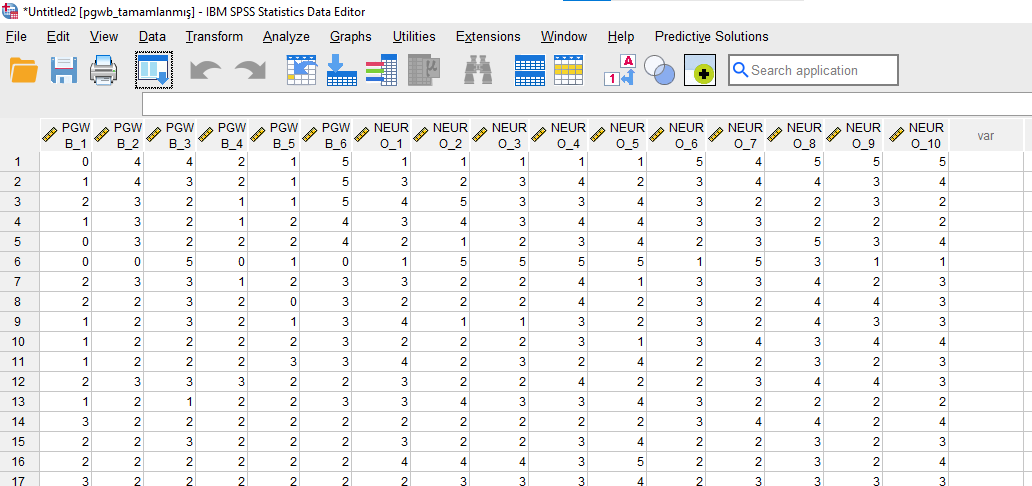
Artık, SPSS’te yapacağımız analizleri bu yeni veri dosyası üzerinden yapabiliriz. Eksik verileri SPSS en uygun gördüğü değerlerle değiştirmiş oldu,
Ortalama Değer Koyma Yöntemiyle Kayıp Veri Atama
Bu yöntemle, her sorunun hangi verileri kayıp ise, o bölümler katılımcıların o soruya verdikleri cevabın ortalaması kaç ise onunla doldurulur. Bu yöntem, gözlemlenen varyansı azalttığı için önerilmemektedir.
Transform -> Replace Missing Values
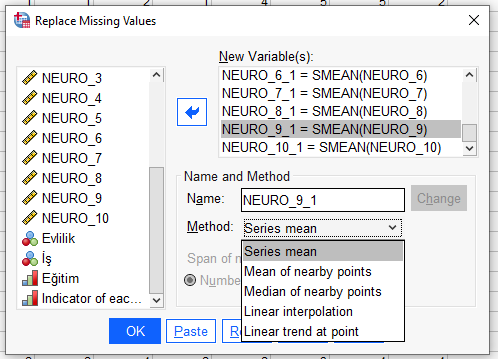
Açılan pencerede, kayıp verileri o sorunun ortalama değeriyle değiştirmek istediğimiz bütün soruları New Variable kutusuna atıyoruz. Sonra, Method menüsünden “Series Mean” seçiyoruz. OK’a basarsak eksik veriler ortalama değerler ile doldurulacaktır.
Linear Interpolation Yöntemiyle Kayıp Veri Atama
Deminki ortalama değer koyma yoluyla eksik veri tamamlama yöntemi yerine, aynı adımlar izlenerek Linear Interpolation yöntemi de seçilerek eksik veri tamamlama işlemi yapılabilir. Bunun için yapmak gereken tek şey Method menüsünde Series Mean’in altındaki Linear Interpolation seçeneğini seçmektir.
Aynı şekilde ihtiyaca göre menüdeki diğer yöntemlerden uygun olanlar da seçilerek uygulanabilir.
Ortalama Değer vs. Linear Interpolation Yöntemi Karşılaştırması
Ortalama Değer (Seri Ortalaması) Yöntemi:
Seri ortalaması yöntemi, eksik değerlerin serideki gözlemlenen verilerin ortalaması (ortalaması) ile değiştirilmesini içerir. Bu yöntem basittir ve eksik değerlerin mevcut verilerin sabit değeri (ortalaması) ile değiştirilmesi durumunda kullanılır. Eksik değerleri olan her değişken veya seri için gözlemlenen veri noktalarının (eksik değerler hariç) ortalaması hesaplanır. Eksik değerler daha sonra hesaplanan bu ortalama değerle değiştirilir.
Linear Interpolation:
Linear Interpolation, gözlemlenen veri noktaları arasında doğrusal bir ilişki olduğunu varsayarak eksik değerleri tahmin etmek için kullanılan bir yöntemdir. Komşu veri noktalarının değerlerine dayalı olarak eksik değerlerin tahmin edilmesini içerir. SPSS’te Linear Interpolation tipik olarak eksik değerlerin bitişik gözlemlenen değerler arasında doğrusal bir eğilimi takip ettiği varsayıldığında zaman serilerine veya sıralı verilere uygulanır. Eksik değer, en yakın önceki ve sonraki gözlemlenen veri noktalarının değerlerine göre tahmin edilir. Tahmini değer, iki bitişik nokta arasında sabit bir değişim oranı varsayılarak düz çizgi enterpolasyonu formülü kullanılarak hesaplanır.
Temel Farklılıklar:
- Tahmin Yaklaşımı: Linear Interpolation, bitişik gözlemlenen veri noktaları arasındaki varsayılan doğrusal eğilime dayalı olarak eksik değerleri tahmin ederek daha karmaşık bir yaklaşım kullanır. Buna karşılık, seri ortalaması yöntemi daha basittir ve eksik değerleri, gözlemlenen verilerden türetilen sabit bir ortalama değerle değiştirir.
- Veri Yapısının Ele Alınması: Linear Interpolation, gözlemler arasında süreklilik veya doğrusallık varsayımının olduğu zaman sıralı veriler için özellikle kullanışlıdır. Seri ortalaması yöntemi herhangi bir veri yapısına uygulanabilir ve eksik değerleri genelleştirilmiş bir özet istatistik (ortalama) ile değiştirir.
- Veri Dağıtımına Etkisi: Linear Interpolation, gözlemlenen noktalar arasında yumuşak bir geçiş olduğunu varsayarak verilerdeki yapıyı ve potansiyel eğilimleri korur. Seri ortalaması yöntemi, eksik değerleri sabit bir değerle değiştirerek, potansiyel olarak verilerin değişkenliğini ve istatistiksel özelliklerini etkileyerek dağılımı düzleştirme eğilimindedir.
Özetle, SPSS’te eksik değerleri doldurmak için Linear Interpolation ve seri ortalaması yöntemi arasında karar verirken verilerinizin doğasını (örneğin, zaman serisine karşı kesitsel) ve verilerin dağılımı ve istatistiksel özellikleri üzerinde istenen etkiyi göz önünde bulundurun. Doğrusal enterpolasyon daha incelikli ve bağlama özgüdür; seri ortalaması yöntemi ise yaklaşımı açısından daha basit ve daha geneldir.
SPSS ile Kayıp Veri Tamamlama (eksik veriler rastgele değilse)
Eğer verideki kayıp veriler, belli bir pattern’i izliyorsa ve rastgele değil ise, o zaman “Multiple Imputation with Regression” yani “regresyon ile çoklu imputasyon” yöntemi ile eksik veriler doldurulabilir. Bu yöntem uzun ve karmaşıktır, fakat uygulandığında en isabetli olan yöntem olarak bilinmektedir. Aşağıda bu yöntemi detaylıca anlatan 45 dakikalık bir video’nun link’ini koydum, ihtiyacınız olursa izleyip bu yöntemi öğrenebilirsiniz.

Bir yanıt bırakın